
強化学習でモデルを選択する時系列異状検知
3つの要点
✔️ 時系列の異状のパターンにはいくつかあり、あるパターンに特化したモデルは、他のパターンの異状検知が得意でないことがあります。
✔️ この手法RLMSADは、この問題に取り組むものです。異なる特徴の異状パターンを検出するモデルをプールし(ここでは5つ)、特定の時系列データに対して、どのモデルが適切であるかを、強化学習を用いて選択します。
✔️ この手法により、従来のモデルをしのぐ特性を確認しています。
Time Series Anomaly Detection via Reinforcement Learning-Based Model Selection
written by Jiuqi Elise Zhang, Di Wu, Benoit Boulet
(Submitted on 19 May 2022 (v1), last revised 27 Jul 2022 (this version, v4))
Comments: Accepted by IEEE Canadian Conference on Electrical and Computer Engineering (CCECE) 2022
Subjects: Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
時系列異状検出は、実世界のシステムの信頼性と効率的な運用のために非常に重要です。これまで、異状の特徴に関する様々な仮定に基づいて、多くの異状検出手法が開発されてきました。しかし、実世界のデータは複雑であるため、時系列内の異なる異状は、通常、異なる異状の仮定を必要とする多様な側面を持っています。このため、単一の異常検出器であらゆるモデルを常に上回ることは困難です。本研究では、異なるベースモデルの利点を活用するために、強化学習に基づくモデル選択の枠組みを提案しています。具体的には、まず異なる異常検知モデルのプールを学習し、次に強化学習を利用して、これらのベースモデルから候補モデルを動的に選択します。実世界のデータを用いた実験を実施した結果、提案手法は総合的な性能の点で全てのモデルを凌駕することが実証されました。
はじめに
スマートグリッドは、サイバーフィジカルシステム技術の一部として、先進的なインフラ、通信ネットワーク、計算技術を活用し、電力網の安全性と効率性を向上させることを目的としています。本論文の評価環境として、スマートグリッドが用いられています。
異常値(外れ値)は、「その集合の残りの部分と矛盾しているように見える観察結果」と定義されます。あるいは、「データ列の大部分のパターンや分布から逸脱している」データポイント または分布から外れているデータ点」と定義されます。このような 異常の発生は、通常、システムにおける潜在的なリスクを示しています。例えば、電力網の異常なメーター測定は、故障やサイバー攻撃の可能性を示唆し、金融時系列の異常は、「詐欺、リスク、個人情報の盗難、ネットワーク侵入、口座乗っ取り、マネーロンダリングなどの違法行為」を示唆しているかもしれません。したがって、異常検知はシステムの運用上の安全性を確保するために重要であり、医療システム, オンラインソーシャルネットワーク, Internet of Things (IoT), スマートグリッドなどの分野で応用が見られるようになっています。
異状検知装置は、通常、以下のいずれかの仮定に基づいて構築されます。
(1)異状は低い頻度で発生する
この仮定の下で、データの基礎となる確率分布を特徴付けることができれば、異状は確率の低い領域または分布の末尾で発生する可能性が最も高い。データストリームにおける異常検出に関するある研究 は、極値理論 (EVT) に基づいて入力データストリームの極値分布に適合し、異常検出のための正規性境界を推定するために PeaksOverThreshold (POT) アプローチを利用している。電力システム計測の異常値検出に関する別の研究 ] では、著者らはカーネル密度推定(KDE)を用いてメーター計測値の確率分布を近似し、さらに確率的オートエンコーダを提案して、正常データの統計区間の上下限を再構築することを提案する。
(2) 異常なインスタンスは大多数のデータから遠く離れているか、低密度の領域に発生する可能性が最も高い
この仮定に基づく手法は、多くの場合、最近傍の概念やデータ固有の距離/近接/密度メトリックを組み込んでいます。最近のある研究では、k-Nearest Neighbors(kNN)アルゴリズムの検出性能を複数の最先端の深層学習ベースの自己教師付きフレームワークと比較し、著者らは単純な最近傍ベース-アプローチが依然としてそれらよりも優れていることを発見しています。Internet of Things (IoT)における異常検知に関するある研究では,著者らはLocal Outlier Factor (LOF) のハイパーパラメーターチューニングスキームを提案しています。
(3) 入力データセットの良い表現が学習できた場合、異常は正常なインスタンスと著しく異なるプロファイルを持つと予想される。あるいは、学習した表現からさらに将来のデータを再構成または予測する場合、異常に基づく再構成は正常データに基づく再構成と著しく異なることが予想される。
最近の研究では、著者らはデータ表現の学習と再構成のために、GRU-RNN、Planar Normalizing Flows (Planar NF)、Variational Autoencoder (VAE) からなる異常検出フレームワークOmniAnomalyを提案している。そして、与えられた潜在変数の下での再構成確率が、異常スコアとして用いられる。宇宙船の異常検出に関する別の研究では、LSTM-RNNを用いてシーケンスの将来値を予測し、予測誤差を解釈するためにノンパラメトリックな閾値スキームを提案している。予測誤差が大きいと、時系列に異常がある可能性が高いことを意味する。
しかしながら、実世界のデータは複雑であるため、異常は様々な形で現れる可能性があります。テスト段階において、異常に関する特定の仮定に基づく異常検出器は、他の側面よりも特定の側面を好む傾向があります。つまり、ある単一のモデルは特定のタイプの異常に敏感である一方で、他の異常を見落としがちである可能性があります。異なるタイプの入力データに対して、他のすべてのモデルを凌駕する普遍的なモデルは存在しません。
異なる時間段階における複数の基本モデルの利点を活用するために、我々は各時間段階において候補モデルプールから最適な検出器を動的に選択することを提案します。提案する設定では、現在の異常予測は現在選択されているモデルの出力に基づきます。強化学習(RL)は、「数値報酬信号を最大化することによって状況を行動にマッピングする」ことに関係する機械学習パラダイムとして、この課題に対する論理的解決策であると思われます。強化学習エージェントは、総報酬を最大化することによって、最適な意思決定方針を学習することを目的としています。強化学習は、電気自動車の充電スケジュール, 家庭のエネルギー管理, 交通信号制御などの実世界の様々な問題に適用されてきた。また、短期負荷予測のためのモデル選択、時系列予測のためのモデル組み合わせ、時系列予測のためのアンサンブルの動的重み付けなど、様々な分野で動的モデル選択の有効性が実証されています。
本研究では、強化学習に基づく異常検知のためのモデル選択フレームワーク(RLMSAD)を提案します。本研究では、入力時系列の観測値と各ベースモデルの予測値に基づいて、各タイムステップで最適な検出器を選択することを目的とします。実世界のデータセットであるSecure Water Treatment (SWaT) を用いた実験により、提案フレームワークはモデルの精度において各ベース検出器を凌駕することが示されます。
技術的背景
時系列での教師なし異状検知
時系列(X = {x1, x2, ..., xt})とは、時間順にインデックスを付けたデータ列のことです。時系列は、各xiがスカラーである一変量と、各xiがベクトルである多変量とがあります。本論文では、多変量時系列における異常検出の問題を教師なし設定で扱います。学習シーケンスXtrainは正常なインスタンスのみを含む時系列であり、テストシーケンスXtestは異常なインスタンスが混入しています。学習段階では、正常なインスタンスの特徴を捉えるために、Xtrainに対して異常検出器を事前学習させます。テストでは、検出器はXtestを検査し、各インスタンスに対して異常スコアを出力します。このスコアを経験的な閾値と比較することで、各テストインスタンスの異常ラベルが得られます。
マルコフ決定過程と強化学習
強化学習(Reinforcement Learning, RL)は、逐次的な意思決定問題を扱う機械学習のパラダイムの一つです。
これは、総報酬を最大化することによって、環境中の最適な行動を発見するようにエージェントを訓練することを目的としており、通常マルコフ決定過程 (MDP) としてモデル化されます。標準的なMDPはタプル、M = (S, A, P, R, γ)として定義されます。この式で、S は状態の集合、A は行動の集合、P(s'|s, a) は状態遷移確率の行列、R(s, a) は報酬関数である。γは報酬計算の割引係数 は報酬計算のための割引係数で、通常0から1の間です。決定論的MDPでは、各行動はある状態に至る、すなわち状態遷移のダイナミッ クスは固定されているので、行列P(s'|s, a)を考える必要はなく、MDPは順に M = (S, A, R, γ)で表すことができる。リターンGt
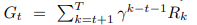
は、現在の時間ステップt後の将来累積報酬。 また、政策π(a|s)は、現在の状態と特定の行動を選択する可能性を対応させた確率分布である。強化学習エージェントは、期待総収益を最大化する決定方針π(a|s)を学習することを目的とします。
手法
全体のワークフロー
モデルのワークフローをFig.1 に示します。時系列入力はスライディングウィンドウで分割されます。各セグメント化されたウィンドウにおいて、最後のタイムスタンプが分析対象のインスタンスとなり、それ以前のすべてのタイムスタンプが入力特徴として使用されます。各異常検出器の候補は、まず個別に訓練セットで事前学習されます。次に、すべての検出器をテストデータに対して実行し、各検出器はすべてのテストインスタンスに対して一連の異常スコアを計算します。異常スコアを解釈するために、各ベース検出器に対して経験的に異常閾値を決定する必要があります。スコアと閾値に基づき、すべてのベースディテクタはテストデータに対する予測ラベルのセットを生成することができます。
前のステップで得られた予測スコア、経験的閾値、予測ラベルを用いて、さらに2つの信頼性スコアを定義します。これら 2 つの信頼度スコアは、予測スコア、閾値、予測ラベルとともに、状態変数としてマルコフ決定過程 (MDP) に統合されます。MDPが構築されると、適切な強化学習アルゴリズム(ここでの実装ではDQNを使用)を用いてモデル選択方針を学習することができます。

ベース検出器の性能評価
モデルプール内の候補検出器の性能を特徴付けるために、以下の2つのスコアを提案します。各異常検出器は、テストデータに対して一連の異常スコアを生成します。通常、異常スコアが高いほど、異常が存在する可能性が高いことを示します。その結果、予測されたスコアがモデルの閾値を超えるほど、その対応するインスタンスが現在のモデルの予測の下で異常である可能性が高くなります。そこで、あるスコアが閾値をどの程度超えているかによって、モデルの予測の妥当性を評価することが考えられます。ここで、距離-閾値信頼度(Distanceto-Threshold Confidence)を提案します。
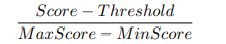
は、スコアの最大値と最小値の差(min-max scale で [0, 1] の範囲にスケールダウン)に対して、現在のスコアが閾値をどれだけ超えているかで計算されます。また、アンサンブル学習における多数決の考え方に着想を得て、予測-合意信頼度(Prediction-Consensus Confidence)を提案します。

これは、候補モデルの総数に対して、同じ予測をするモデルの数で計算されます。プール内で同じ予測を生成している候補モデルが多ければ多いほど、現在の予測が真である可能性が高くなります。
マルコフ決定過程(MDP)定式化
モデル選択問題は次のようにマルコフ決定過程として形式化されます(Fig.2参照)。この設定では、状態遷移は当然ながらシーケンスの時間ス テップとして時間順序に従うので、決定論的です。すなわち、状態遷移確率 P(s'|s) は st から st+1 までの直近で連続するあらゆる状態の組に対して 1、それ以外の場合に対して 0 です。割引係数γを1(割引なし)とします。
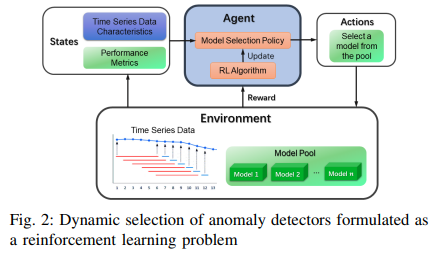
- 状態
状態空間はモデルプールと同じ大きさである。我々は各状態を選択された異常検出器とみなし、状態変数には、スケールされた異常スコア、スケールされた異常閾値、バイナリ予測ラベル(正常は0、異常は1)、距離-閾値信頼度、予測-合意信頼度を含む。各ベース検出器について、その異常スコアと閾値は minmax スケールを使用して [0, 1] に正規化されることに留意。
- アクション
アクション空間は離散的であり、モデルプールと同じサイズである。ここで、プールから1つの候補検出器を選択する各アクションは、プール内の選択されたモデルのインデックスによって特徴付けられる。
- 報酬
報酬関数は、予測されたラベルと実際のラベルの比較に基づいて決定される。これは、(r1, r2, r3, r4 > 0)で示される。

報酬は、エージェントが動的環境において適切なモデル選択を行うことを促すように設計されている。我々は、異常を「正」、正常なインスタンスを「負」と見なす。TP(True positive)とは、予測したラベルとグランドトゥルースのラベルの両方が「異常」であり、モデルが正しく異常を識別した状態を表す。True negative (TN) は、予測されたラベルとグラウンドトゥルースのラベルの両方が「正常」である場合を表し、言い換えれば、モデルは正常なインスタンスを正しく識別する。False positive (FP) は、予測されたラベルが "anomalous" で、ground truth のラベルが "normal" である場合を表し、モデルが正常なインスタンスを誤って分類していることを示唆する。FN(False negative)は、予測されたラベルが「正常」であり、グランドトゥルースのラベルが「異常」であるシナリオを表し、モデルが異常を見過ごし、正常であると誤認していることを意味する。
上記の4つのシナリオの実世界での意味を考慮し、報酬設定に関して以下の仮定を提案する。正常なインスタンスが大多数であり、異常は比較的まれである。したがって、正常なインスタンスを正しく識別することは、より些細なケースであると考える。この観点から、TN の報酬は相対的に小さく、TP の報酬は相対的に大きく、すなわち r1 > r2 であるべきである。
また、実際の異常を無視することは、一般に誤報を与えることよりも有害である。時には、むしろモデルが過敏になり、ポジティブな予測をしながら「大胆」になるように促すこともある。これにより、モデルはより多くのFPを生成する可能性があるが、実際の異常を無視するリスクを減らすこともできる。この点で、モデルが誤報を発生させた場合(FP の場合)よりも、実際の異常を検出できなかった場合(FN の場合)、すなわち r4 > r3 の場合に、モデルに厳しいペナルティを課すことになる。
実験
データセット
評価に用いたデータセットは、シンガポール工科デザイン大学のサイバーセキュリティ研究センターであるiTrustが収集したSecure Water Treatment (SWaT) Datasetです。このデータセットは、工業用水処理テストベッド内の51のセンサーとアクチュエーターの動作データを収集しています。ここの実験は2015年12月版で行われ、7日間の通常運転データと4日間の攻撃によって汚染されたデータ(異常値)が含まれています。これは51の特徴を持つ多変量時系列データセットです。7日間の通常データには496,800個のタイムスタンプが含まれており、事前学習セットとして選択されています。攻撃を受けている4日間のデータには449,919個のタイムスタンプが含まれており、テストセットとして選択されています。テストセットにおける異常データの割合は11.98%です。
ベースモデル
モデルプールを形成する際、異なる異常の仮定に基づくモデルを選択することで、選択の多様性を確保します。以下の 5つの教師なし異常検知アルゴリズムを候補モデルとして選択します。
- ワンクラスSVM(One-Class SVM )
サポートベクトルに基づく新規性検出のための手法である.データ密度の高い領域とデータ密度の低い領域を分離する超平面を学習することを目的とする。
- アイソレーションフォレスト(iForest)
Isolation Forestアルゴリズムは、異常は孤立しやすいという仮定に基づいている。複数のデータセット/データセット情報/決定木がデータセットにフィットしているとすると、異常なデータポイントは大多数のデータからより容易に分離できるはずである。したがって、決定木の根に比較的近い葉、すなわち、決定木のより浅い深さで異常が見つかると予想される。
- 異常値検出のための経験的累積分布(ECOD)
ECODは、多変量データの統計的異常値検出法である。ECODはまず、各データ次元に沿った経験的累積分布を計算し、次にこの経験的分布を利用して末尾確率を推定する。推定された末端確率をすべての次元で集計し、異常スコアを計算する。
- コピュラベースの異常値検出(COPOD)
COPODもまた、多変量データに対する統計的異常値検出法である。これは、すべてのデータポイントの末尾確率を予測するために経験的コピュラを仮定し、これがさらに異常スコアとして機能する。
- 多変量データに対する教師なし異常検出(Unsupervised Anomaly Detection on Multivariate : USAD)
これは表現学習に基づいた異常検出方法である。敵対的に訓練されたエンコーダとデコーダのペアを用いて、生の時系列入力に対するロバストな表現を学習する。テスト段階では、再構成誤差が異常スコアとして使用される。スコアが期待される正常な埋め込みから外れれば外れるほど、異常が発見された可能性が高くなる。
ワンクラスSVMとiForestについては、Scikit-LearnライブラリのデフォルトハイパーパラメータでSGDOneClassSVMとIsolationForestを使用します。ECODとCOPODについては、PyOD toolbox からECODとCOPODのデフォルト関数を採用しました。USAD については、著者のオリジナル GitHub リポジトリからの実装を使用します。
評価指標
本研究では、異状検知性能の評価として、精度(Precision)、再現率(Recall)、F-1スコア(F1)を用います。
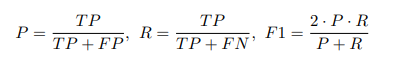
異常を「陽性」、正常なデータ点を「陰性」と考えます。定義によれば、真陽性(TP)は正しく予測された異常データ、真陰性(TN)は正しく予測された正常データ、偽陽性(FP)は誤って異常と予測された正常データ点、偽陰性(FN)は誤って正常と予測された異常データ点です。
実験の設定
ダウンサンプリングはタイムスタンプの数を減らすことで学習速度を上げることができ、またデータセット全体のノイズを除去することができます。データの前処理段階では、5つのタイムスタンプごとに5のストライドで平均を取るダウンサンプリングレートを適用しました。
SWaTデータセットの異常の割合(11.98%、約12%)を既に知っているので、閾値基準は12%に固定されます。これは、各ベース検出器において、データインスタンスのスコアがシーケンスの全出力スコアの上位12%にランクされる場合、現在の検出器がこのデータインスタンスを異常としてラベル付けすることを意味します。RLエージェントは、PyTorchベースの強化学習ツールボックスであるStableBaselines3のDQNのデフォルト設定を使用して学習しました。異なるハイパーパラメータ設定下でのRLモデルの性能を報告するために、ランダムな初期化で各実験を10回実行し、評価指標の平均と標準偏差を報告します。
結果と考察
1) 総合性能
まず、5つのベースモデル単独と強化学習モデル選択(RLMSAD)方式の性能を比較します。ここで、RLMSADの報酬設定は、TPが1、TNが0.1、FPが-0.4、FNが-1.5です。
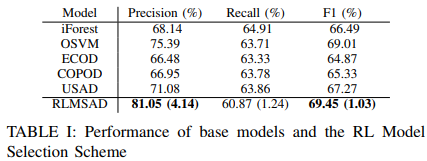
ベースモデルの精度(Precision)スコアは約66%から75%である。すべてのベースモデルは約63%のリコールを示している。ベースモデルのF-1スコアは約65%から69%である。
提案するフレームワークでは,全体の精度とF-1スコアがともに大きく向上しています.RLMSADの精度は81.05%、F-1は69.45%に達し、異常検知性能の大幅な向上が確認されました。
2) 報酬の設定の違い
MDPの定式化において、偽陽性(FP)と偽陰性(FN)に対するペナルティの効果を調査します。
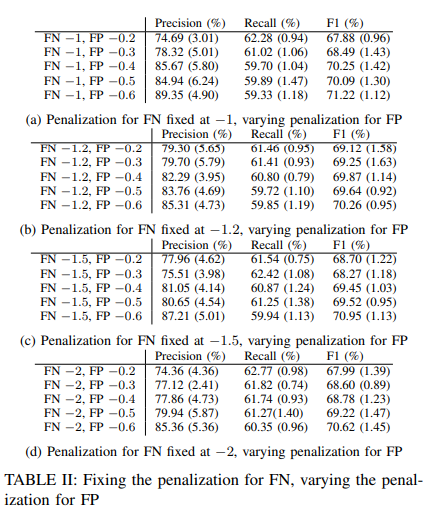
・誤認識に対するペナルティの効果
偽陰性に対するペナルティーを固定し、偽陽性に対するペナルティーを変化させました。その結果はTable IIに示されています。偽陽性に対するペナルティを増加させることは、予測に対してより慎重になるようモデルに指示することです。その結果、モデルはより少ない誤報を報告し、その予測にかなり自信がある場合にのみ異常を報告するようになります。言い換えれば、モデルはシーケンス内の比較的小さな偏差にあまり敏感でないため、精度が向上する可能性があります。また、多数派とは大きく異なるデータインスタンスのみを異常として報告するため、実際の異常をカバーすることが少なくなり、その結果、再現性が損なわれる可能性があります。このことは、Table II において、FP ペナルティが増加するにつれて、リコールスコアが減少し、精度スコアが増加することからも明らかです。
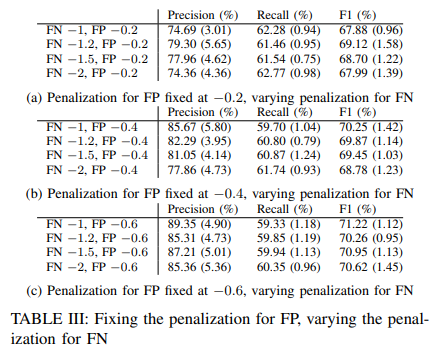
・偽陰性に対するペナルティの効果
偽陽性に対するペナルティを固定し、偽陰性に対するペナルティを変化させました。その結果はTable IIIに示されています。偽陰性に対するペナルティを増加させることは、異常の報告に関してモデルが「大胆」になることを促しています。偽陰性(すなわち、実際の異常を見逃すこと)のコストが高くなると、エージェントにとって最良の戦略は、実際の異常を多く見逃さないように、できるだけ多くの異常を報告することです。この場合、モデルは小さな偏差に過敏に反応し、精度を落とす可能性が高くなります。一方、インスタンスに異常のフラグを立てる可能性が高いので、より多くの実際の異常をカバーし、より高いリコールを達成する可能性も高くなります。このことは、Table IIIにおける精度スコアの一般的な低下とリコールスコアの上昇によって実証されます。
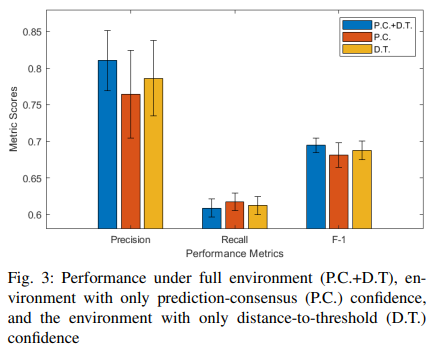
3) 切り分け研究
距離-閾値信頼度(D.T.)と予測-合意信頼度(P.C.)という二つの信頼度の効果を調べるために、切り分けを行いました。ここでは、本来の強化学習環境とは別に、2つの強化学習環境を構築しました。この2つの環境では、2つの信頼度スコアのそれぞれを状態変数から削除する。これら3つの環境それぞれで政策を再学習させ、検出性能をFig. 3に報告します。Fig. 3から、2つの信頼度スコアのどちらかを削除すると、精度とF-1スコアが大きく低下することがわかります。2つの信頼度スコアの両方を状態成分として考慮した場合にのみ、最適な性能が得られます。
まとめ
本論文では、時系列異状検出のための強化学習ベースのモデル選択フレームワークを提案しました。
具体的には、まず、ベースモデルの検出性能を特徴付けるために、距離-閾値信頼度と予測-合意信頼度という2つのスコアを導入しました。次に、モデル選択問題をマルコフ決定過程として定式化し、2つのスコアをRLの状態変数として用いました。長期的な期待性能を最適化するために、異常検出のためのモデル選択方針を学習することを目的としました。実世界の時系列に対する実験を行い、本手法のモデル選択フレームワークの有効性を示しました。今後は、データ固有の適切な特徴量の抽出と状態遷移への埋め込みに注力する予定です。これにより、RLエージェントはより有益な状態記述を得ることができ、より頑健な性能を得ることができる可能性があります。




この記事に関するカテゴリー






