
時系列用の最新トランスフォーマーをサーベイ
3つの要点
✔️ 時系列用のトランスフォーマーについてレビューし、その長所と限界に焦点を当てる
✔️ トランスフォーマーのネットワーク構造とアプリケーションの観点からサマリー
✔️ 今後の発展の方向性について提案
Transformers in Time Series: A Survey
written by Qingsong Wen, Tian Zhou, Chaoli Zhang, Weiqi Chen, Ziqing Ma, Junchi Yan, Liang Sun
(Submitted on 15 Feb 2022 (v1), last revised 10 Feb 2023 (this version, v4))
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Signal Processing (eess.SP); Machine Learning (stat.ML)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
トランスフォーマーは自然言語処理やコンピュータビジョンにおける多くのタスクで優れた性能を発揮しており,時系列用途においても大きな関心を呼んでいます。トランスフォーマーの複数の利点の中でも、長距離の依存性と相互作用を捉える能力は、時系列モデリングにとって特に魅力的であり、様々な時系列アプリケーションにおいて目覚ましい進歩をもたらしています。本論文では、時系列モデリングのためのトランスフォーマー方式を系統的にレビューし、その長所と限界に焦点を当てます。
特に、時系列トランスフォーマーの発展を2つの観点から検討しています。ネットワーク構造の観点からは、時系列解析の課題に対応するためにトランスフォーマーに施された適応と修正を要約しています。アプリケーションの観点からは、予測、異常検出、分類などの共通のタスクに基づいて、時系列トランスフォーマーを分類しています。実例として、ロバスト分析、モデルサイズ分析、季節-トレンド分解分析を行い、トランスフォーマーが時系列においてどのように機能するかをレビューしています。最後に、有用な研究指針を提供するために、将来の方向性について議論し、提案しています。
なお、本論文でレビューしている論文の原典については、原論文のReferenceを参照してください。
はじめに
深層学習におけるトランスフォーマーの革新性[Vaswani et al., 2017]は、自然言語処理(NLP)[Kenton and Toutanova, 2019]、コンピュータビジョン(CV)[Dosovitskiy et al., 2021]、音声処理[Dong et al., 2018]、および他の分野[Chen et al., 2021b]での優れた性能により最近大きな関心を呼んでいます。過去数年にわたり、様々なタスクの最先端のパフォーマンスを大幅に前進させるために、数多くのトランスフォーマーの亜種が提案されています。NLPアプリケーション[Qiu et al., 2020; Han et al., 2021]、CVアプリケーション[Han et al., 2020; Khan et al., 2021; Selva et al., 2022]、効率の良いTransformer [Tay et al., 2020] 、アテンションモデル [Chaudhari et al., 2021; Galassi et al., 2020] など、異なる側面からかなり多くの文献レビューがあります。
トランスフォーマーは逐次データにおける長距離の依存関係や相互作用に対して優れたモデリング能力を示しており、それゆえ時系列モデリングにも適用されるようになりました。時系列モデリングにおける特別な課題に対処するために、Transformerの多くの類型が提案されており、予測[Li et al., 2019; Zhou et al., 2021; Zhou et al., 2022]、異常検出[Xu et al., 2022; Tuli et al., 2022], 分類 [Zerveas et al., 2021; Yang et al., 2021] 等、様々な時系列タスクへの応用が成功裏に行われてきています。例えば、季節性や周期性は時系列の重要な特徴です[Wen et al., 2021a]。一方、長距離と短距離の時間依存性を効果的にモデル化し、季節性を同時に捉える方法は、依然として課題です[Wu et al., 2021; Zhou et al., 2022]。時系列のためのTransformerは深層学習における新たな課題であるため、体系的かつ包括的な調査は、時系列コミュニティに大いに貢献するでしょう。時系列のための深層学習に関連するいくつかのサーベイが存在し、予測[Lim and Zohren, 2021; Benidis et al., 2020; Torres et al., 2021]、分類[Ismail Fawaz et al., 2019]、異常検出[Choi et al., 2021; Bl ́ azquez-Garc ́a et al., 2021]、データ増強[Wen et al., 2021b]が含まれていますが、時系列に対するTransformersにほとんど触れられていませんでした。
この論文では、時系列トランスフォーマーの主な開発を要約することによって、そのギャップを埋めることを目的としています。時系列トランスのネットワーク修正とアプリケーションドメインの両方の観点から、新しい分類法を提案します。ネットワークの修正については、時系列モデリングの性能を最適化する目的で、トランスフォーマーの低レベル(すなわちモジュール)と高レベル(すなわちアーキテクチャ)の両方についてなされた改良について議論します。アプリケーションについては、予測、異常検出、分類を含む一般的な時系列タスクのためのトランスフォーマーを分析し、要約しています。各時系列トランスフォーマーについて、その洞察、長所、限界を分析します。時系列モデリングのためにトランスフォーマーを効果的に使用する方法についての実用的なガイドラインを提供するために、ロバスト性の分析、モデルサイズの分析、季節-トレンドの分解分析を含む時系列モデリングの複数の側面を検証する広範囲な実証研究を実施します。最後に、時系列トランスフォーマーの誘導バイアス、時系列トランスフォーマーとGNN、時系列トランスフォーマーの事前学習、時系列トランスフォーマーとNASを含む時系列トランスフォーマーの将来の可能な方向性を議論しています。これは、時系列データのモデリングのためのトランスフォーマーの主要な開発を初めて包括的かつ体系的にレビューしたものです。
時系列でのトランスフォーマーの分類
既存の時系列トランスフォーマーを整理するために、ネットワークの改変と応用分野の観点から、Fig. 1に示すような分類法を提案します。この分類法に基づき、既存の時系列トランスフォーマーを体系的にレビューします。ネットワークの変更という観点からは、時系列モデリングにおける特別な挑戦に対応するために、トランスフォーマーのモジュールレベルおよびアーキテクチャレベルの両方で行われた変更を要約します。アプリケーションの観点からは、予測、異常検出、分類、クラスタリングなどのアプリケーションタスクに基づいて、時系列トランスフォーマーを分類します。
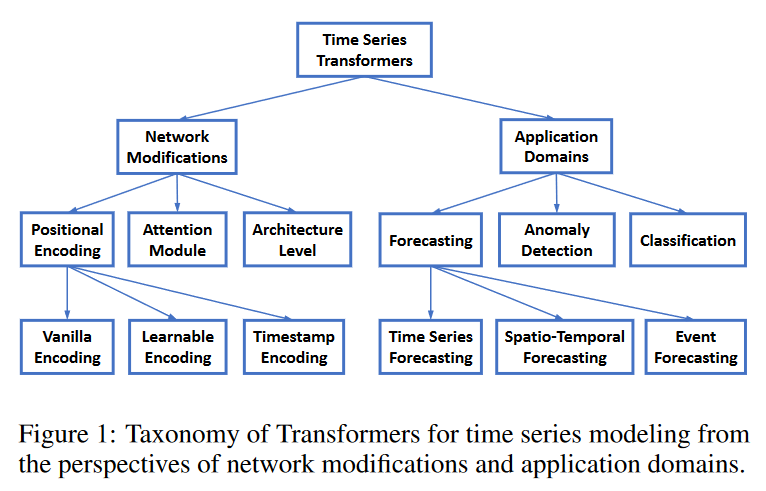
時系列用にネットワーク改造
位置エンコーディング
トランスフォーマーは順列等価であり、時系列の順序が重要であるため、入力時系列の位置をトランスフォーマーに符号化することは非常に重要です。一般的な設計は、まず位置情報をベクトルとしてエンコードし、それを入力時系列とともに追加入力としてモデルに注入します。トランスフォーマーで時系列をモデル化する際に、これらのベクトルをどのように取得するかは、大きく3つに分けることができます。
・バニラポジショナルエンコーディング
いくつかの研究[Li et al., 2019]では、[Vaswani et al., 2017]で使われているバニラ位置エンコーディングを単に導入し、それを入力時系列の埋め込みに追加してトランスフォーマーに供給しています。この平易なアプリケーションでは、時系列からある程度の位置情報を抽出することはできますが、時系列データの重要な特徴を十分に活用することはできませんでした。
・学習可能なポジションエンコーディング
バニラ位置エンコーディングは手作りで表現力や適応力が低いため、時系列データから適切な位置エンコーディングを学習することがより効果的であることがいくつかの研究で明らかにされています。固定的なバニラ位置エンコーディングと比較して、学習されたエンコーディングはより柔軟であり、特定のタスクに適応することができます。
[Zerveas et al., 2021]はトランスフォーマーに埋め込み層を導入し、各位置インデックスに対する埋め込みベクトルを他のモデルパラメータと合同で学習している。[Lim et al., 2019]は、時系列における順序情報をより良く利用することを目的として、位置埋め込みを符号化するためにLSTMネットワークを使用しました。
・タイムスタンプエンコーディング
実世界で時系列をモデル化する場合 実世界のシナリオで時系列をモデル化する場合、タイムスタンプ情報には、カレンダータイムスタンプ(例:秒、分、時、週、月、年)、特殊タイムスタンプ(例:休日、イベント)などが一般的にアクセス可能です。これらのタイムスタンプは、実際のアプリケーションではかなり 実際のアプリケーションでは非常に有益なものですが、バニラトランスフォーマーではほとんど活用されていません。この問題を軽減するために、Informer [Zhou et al, 2021]は、学習可能な埋め込みを用いることで、タイムスタンプを追加の位置情報としてエンコードすることを提案しました。同様の タイムスタンプの符号化方式は、Autoformer [Wu et al., 2021]やFEDformer[Zhou et al., 2022]でも同様のタイムスタンプエコード方式が採用されています。
アテンションモジュール
トランスフォーマーの中心となるのは、セルフアテンションモジュールです。これは、入力パターンのペアワイズ類似性に基づいて動的に生成される重みを持つ完全連結層と見なすことができます。その結果、完全連結層と同じ最大経路長を共有するが、パラメータの数ははるかに少なく、長期的な依存関係のモデリングに適しています。
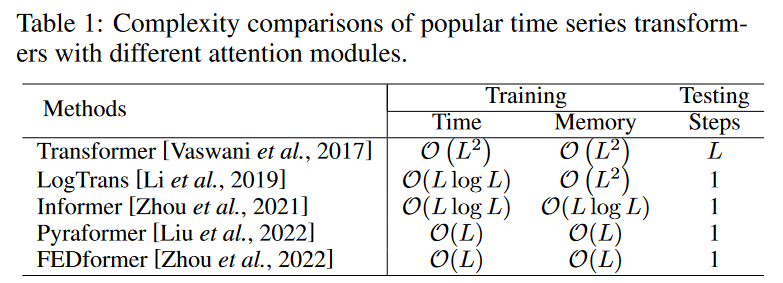
バニラトランスのセルフアテンションモジュールは、O(L2)(Lは入力時系列長)の時間・メモリ複雑度を持ち、これが長い時系列を扱うときの計算ボトルネックとなります。この2次的な複雑さを軽減するために、多くの効率的なトランスフォーマーが提案され、それらは大きく2つに分類されます。
(1) LogTrans [Li et al., 2019]やPyraformer [Liu et al., 2022]のようにアテンションメカニズムにスパース性バイアスを明示的に導入するものです。
(2) Informer [Zhou et al., 2021]やFEDformer [Zhou et al., 2022]など、計算を高速化するためにセルフアテンション行列の低ランク特性を探索するものです。Table 1では、時系列モデリングに適用される一般的なトランスフォーマーの時間およびメモリの複雑さの両方を要約しています。
アーキテクチャーレベルのイノベーション
トランスフォーマーの個々のモジュールを時系列のモデル化に対応させることに加え、多くの研究[Zhou et al, 2021; Liu et al, 2022]は、トランスフォーマーをアーキテクチャレベルで刷新することを試みています。最近の研究では、時系列の多重解像度的な側面を考慮し、トランスフォーマーに階層的なアーキテクチャを導入しています。Informer [Zhou et al., 2021]は、アテンションブロックの間にストライド2の最大プール層を挿入し、その半分のスライスに系列をダウンサンプリングしています。
Pyraformer [Liu et al., 2022]はC-ary treeベースのアテンションメカニズムを設計し、最も細かいスケールのノードが元の時系列に対応し、より粗いスケールのノードがより低い解像度の系列を表しています。Pyraformerは、異なる解像度にまたがる時間依存性をよりよく捉えるために、スケール内アテンションとスケール間アテンションの両方を開発しました。異なるマルチ解像度の情報を統合する能力に加えて、階層的なアーキテクチャは、特に長い時系列に対して効率的な計算を行うという利点も享受することができます。
時系列トランスフォーマーのアプリケーション
予測、異常検出、分類などの重要な時系列タスクへのトランスフォーマーの適用についてレビューします。
予測でのトランスフォーマー
ここでは、時系列予測、空間・時間予測、イベント予測の3種類の予測タスクについて考察します。
・時系列予測
予測は、時系列の最も一般的かつ重要なアプリケーションです。LogTrans [Li et al., 2019] は、セルフアテンション層でクエリとキーを生成するために因果的な畳み込みを採用することで、畳み込みセルフアテンションを提案しました。これは,セルフアテンションモデルにスパースバイアス(Logsparseマスク)を導入し,計算量をO(L)からO(Llog L)に減少させるものです。
Informer [Zhou et al., 2021]は、スパースバイアスを明示的に導入する代わりに、クエリーとキーの類似性に基づいてO(log L)ドミナントクエリーを選択し、LogTransと同様の計算量の改善を達成します。
LogTransと同様の計算量の改善を達成しています。また、長期予測を直接生成する生成型デコーダを設計し、長期予測のための1ステップ予測による累積誤差を回避しています。
AST [Wu et al., 2020]は、生成的な敵対的エンコーダ・デコーダのフレームワークを使用している。エンコーダ・デコーダのフレームワークを用いて、時系列予測のためのスパーストランスフォーマー モデルを学習します。これは、敵対的 を直接形成することにより、時系列予測を改善することができています。ネットワークの出力分布を直接形成し、一歩先の推論による誤差の蓄積を回避することで また,一歩先の推論を行うことで,誤差の蓄積を避けることができます。
Autoformer [Wu et al., 2021]は、自己相関機構を持つシンプルな季節トレンド分解アーキテクチャを考案し、アテンションモジュールとして機能します。機構がアテンションモジュールとして働くシンプルな季節トレンド分解アーキテクチャを考案しました。自己相関ブロックは伝統的なアテンションブロックではありません。入力信号間の時間遅延の類似性を測定し、上位k個の類似した部分系列を集約して出力をを生成し、O(Llog L)の複雑さを軽減しています。
FEDformer [Zhou et al., 2022]は、フーリエ変換とウェーブレット変換を用いた周波数領域でのアテンション操作を適用したものです。周波数の固定サイズの部分集合をランダムに選択することで、線形な複雑性を実現します。AutoformerとFEDformerの成功により、時系列モデリングのための周波数領域でのセルフアテンションメカニズムの探求がコミュニティでより注目されていることは注目に値します。
TFT [Lim et al., 2021]は、静的共変量エンコーディングによるマルチホライズン予測モデルを設計しています。静的共変量エンコーダ、ゲーティング特徴選択、時間的セルフアテンションデコーダを備えた多ホライズン予測モデル および時間的セルフアテンションのデコーダを含みます。これは、予測するために様々な共変量から有用な情報を符号化し、選択します。また、グローバルに取り入れた解釈可能性を保持します。さらに、時間依存性、イベントなどを組み込んだ解釈可能性を保持します。
SSDNet [Lin et al., 2021]とProTran [Tang and Matteson, 2021]はTransformerと状態空間モデルを組み合わせて、確率的な予測を提供するものです。SSDNetはまずTransformerを用いて時間的パターンを学習し、SSMのパラメータを推定し、次にSSMを適用して季節トレンド分解を行い、解釈可能な能力を維持します。ProTranは変分推論に基づく生成的なモデリングと推論手順を設計します。
Pyraformer [Liu et al., 2022] は、異なる範囲の時間依存性を線形時間およびメモリ複雑度で捕らえるために、二分木を辿る経路を持つ階層的ピラミッド型アテンションモジュールを設計しています。
Aliformer [Qi et al., 2021]は、知識誘導型アテンションと、アテンションマップを修正・ノイズ除去する分岐を用いて、時系列データに対する逐次予測を行うものです。
・時空間予測
時空間予測では、正確な予測を行うために、時間依存性と時空間依存性の両方を考慮する必要があります。Traffic Transformer [Cai et al., 2020]は、時空間依存性を捉えるためのセルフアテンションモジュールと空間依存性を捉えるためのGraph neural networkモジュールを用いたエンコーダ・デコーダ構造を設計しています。交通流予測のためのSpatialtemporal Transformer [Xu et al., 2020]は、さらに一歩踏み込んでいます。時間的依存性を捉えるための時間的トランスフォーマーブロックの導入に加えて、空間的依存性をよりよく捉えるために、グラフ畳み込みネットワークとともに空間的トランスフォーマーブロックも設計しています。時空間グラフトランスフォーマー [Yu et al., 2020]は、歩行者軌道予測を改善するために、複雑な時間-空間アテンションパターンを学習することができるアテンションベースのグラフ畳み込みメカニズムを設計しています。
・イベント予測
現実のアプリケーションでは、不規則で非同期なタイムスタンプを持つイベントシーケンスデータが自然に観察されます。これは、サンプリング間隔が等しい通常の時系列データとは対照的です。イベント予測は、次のような目的で行われます。
イベント予測は、過去のイベントの履歴から将来のイベントの時間とマークを予測することを目的としており、しばしば時間点過程(TPP) [Shchur et al., 2021]によってモデル化されます。
最近、いくつかのニューラルTPPモデルが、事象予測の性能を向上させるために、トランスフォーマーを取り入れ始めています。
Self-attentive Hawkes process (SAHP) [Zhang et al., 2020] とTransformer Hawkes process (THP) [Zuo et al., 2020] は、履歴イベントの影響を要約し、イベント予測のための強度関数を計算するためにトランスフォーマーエンコーダアーキテクチャを採用しています。彼らは、イベント間の間隔を利用できるように、時間間隔を正弦波関数に変換することで位置エンコーディングを修正します。その後、より柔軟なattentive neural Datalog through time (A-NDTT) [Mei et al., 2022] が提案され、SAHP/THPスキームを拡張し、全ての可能なイベントと時間をアテンションで埋め込むことができるようになりました。実験によれば、既存の手法よりも洗練されたイベント依存性をよりよく捉えることができています。
異状検知でのトランスフォーマー
深層学習はまた、異常検知のための新規開発の引き金にもなります[Ruff et al., 2021]。ディープラーニングは表現学習の一種であるため、再構成モデルは異常検知タスクにおいて重要な役割を果たします。再構成モデルは、単純な事前定義されたソース分布Qから実際の入力分布P +にベクトルをマッピングするニューラルネットワークを学習することを目的としています。Qは通常、ガウス分布または一様分布です。異常スコアは再構成エラーによって定義されます。直感的には、再構成誤差が大きいほど、つまり入力分布からの可能性が低いほど、異常スコアは高くなります。異常と正常を区別するために閾値が設定されます。
最近、[Meng et al., 2019]は、時間依存性に対する他の従来のモデル(例えば、LSTM )と比較して、異常検出にトランスフォーマーを使用する利点を明らかにしました。より高い検出品質(F1によって測定)に加えて、トランスフォーマーベースの異常検出は、LSTMベースの手法よりも著しく効率的であり、そのほとんどはトランスフォーマーアーキテクチャの並列計算によるものです。TranAD [Tuli et al., 2022], MT-RVAE [Wang et al., 2022], TransAnomaly [Zhang et al., 2021] など複数の研究において、研究者は、異常検出におけるより良い再構成モデルのために、VAEs [Kingma and Welling, 2013] や GANs [Goodfellow et al., 2014] など、ニューラル生成モデルと トランスフォーマー の結合を提案しています。
TranADは、単純なトランスフォーマーベースのネットワークでは、異常の小さな偏差を見逃す傾向があるため、再構成誤差を増幅するための敵対的学習手順を提案しています。GAN形式の敵対的学習手順は、2つのトランスフォーマーエンコーダと2つのトランスフォーマーデコーダによって設計されており、安定性を得ることができます。切り分け分析の結果、トランスフォーマーエンコーダ・デコーダを交換した場合、F1スコアが11%近く低下することがわかり、トランスフォーマーアーキテクチャが異常検知に重要であることが示されました。
MT-RVAEとTransAnomalyはVAEとトランスフォーマーを組み合わせたものですが、両者は異なる目的を共有しています。TransAnomalyはVAEとトランスフォーマーを組み合わせることで、より多くの並列化を可能にし、学習コストを80%近く削減することができます。MT-RVAEでは、マルチスケールトランスフォーマーは、異なるスケールの時系列情報を抽出・統合するために設計されています。従来のトランスフォーマーの欠点であった局所的な情報のみを抽出し、逐次的に解析することを克服しています。
多変量時系列のための時系列トランスフォーマーは、GTA[Chen et al., 2021d]のようなグラフベースの学習アーキテクチャとトランスフォーマーを組み合わせたものがいくつか設計されています。MT-RVAEも多変量時系列のためのものですが、次元が少ないか、シーケンス間の密接な関係が不十分であることに注意する必要があります。
グラフニューラルネットワークモデルがうまく機能しないような、次元が少ない、あるいはシーケンス間の密接な関係が十分でない場合です。そこで、MT-RVAEでは、位置符号化モジュールを変更し、特徴学習モジュールを導入しています。GTAはグラフ畳み込み構造を持ち、影響伝播過程をモデル化します。MT-RVAEと同様に、GTAも「グローバル」な情報を考慮しますが、バニラマルチヘッドアテンションの代わりに、多枝アテンション機構、つまり、グローバル学習されたアテンション、バニラマルチヘッドアテンション、近傍畳み込みを組み合わせた機構を採用しています。
つまり、グローバル学習型アテンション、バニラ型マルチヘッドアテンション、近傍畳み込みの組み合わせです。
AnomalyTrans [Xu et al., 2022] は、トランスフォーマーと Gaussian Prior-Association を組み合わせて、稀なアノマリーをより区別しやすくします。TranADと同様の動機を共有していますが、AnomalyTransは非常に異なる方法でこの目標を達成します。その洞察は、正常と比較して、異常は系列全体と強い関連性を構築することが難しく、隣接する時点とは容易に関連性を構築できるというものです。AnomalyTransでは、事前関連と系列関連は同時にモデル化されます。再構成損失に加えて、事前関連と系列関連をより区別できるように制約するために、minimax戦略によって異常モデルが最適化されます。
分類でのトランスフォーマー
トランスフォーマーは、長期的な依存関係を捉えることができるため、様々な時系列の分類タスクに有効であることが証明されています。分類トランスフォーマーは通常、セルフアテンション層が表現学習を行い、フィードフォワード層が各クラスの確率を生成するシンプルなエンコーダ構造を採用します。
GTN [Liu et al., 2021]は2つのタワーからなるトランスフォーマーを用い、各タワーはそれぞれ時間ステップ単位のアテンションとチャンネル単位のアテンションを働かせます。2つのタワーの特徴を統合するために、学習可能な重み付き連結(「ゲーティング」とも呼ばれる)が使用されます。提案するトランスフォーマーの拡張は、13個の多変量時系列の分類において、最良の結果を達成します。[Rußwurm and Korner, 2020] は、生の光学衛星時系列分類のためのセルフアテンションに基づくトランスフォーマーを研究し、リカレントニューラルネットワークや畳み込みニューラルネットワークと比較して、最良の結果を得ています。
また、事前に学習されたトランスフォーマーも分類タスクにおいて研究されています。[Yuan and Lin, 2020]は、生の光学衛星画像の時系列分類のためのトランスフォーマーを研究しています。著者らは、ラベル付けされたデータが限られているため、自己教師付き事前学習スキーマを使用しています。[Zerveas et al., 2021]は教師なし事前学習フレームワークを導入し、モデルは比例的にマスクされたデータで事前学習されます。事前学習されたモデルは、分類などの下流タスクで微調整されます。
[Yang et al., 2021]は、下流の時系列分類問題に大規模な事前学習済み音声処理モデルを使用することを提案し、30の一般的な時系列分類データセットで19の優位な結果を生成しています。
Experimental Evaluation and Discussion
このセクションでは、トランスフォーマーが時系列データ上でどのように機能するかを分析するために、実証的な研究を実施します。具体的には、典型的なベンチマークデータセットETTm2 [Zhou et al., 2021]に対して、異なる構成で異なるアルゴリズムをテストします。
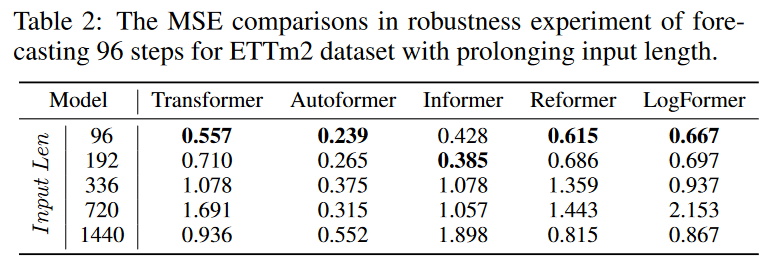
頑強性分析
しかし、これらの研究では、短い固定サイズの入力を使って最良の結果を得ています。このような効率的な設計が実際に使われているのか疑問が残ります。そこで、入力列の長さを長くした実験を行い、長時間の入力列に対する予測力と頑健性を検証しました。
Table 2に示すように、入力列を長くした場合の予測結果を比較すると、様々なトランスフォーマーベースのモデルが急速に劣化していることがわかります。この現象は、慎重に設計された多くのトランスフォーマーが、長い入力情報を効果的に利用できないため、長期的な予測タスクにおいて実用的でないことを意味します。長時間の連続入力を単に実行するだけでなく、十分に活用するためには、より多くの研究が必要です。
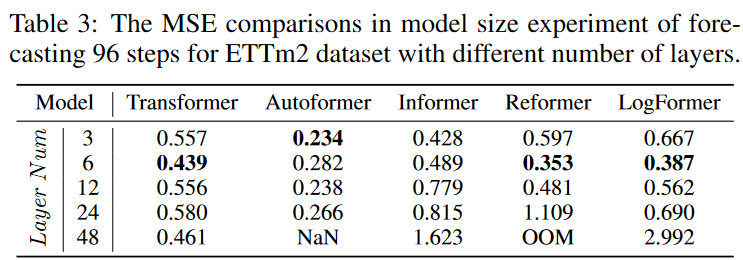
モデルサイズ分析
時系列予測の分野に導入される前に、トランスフォーマーはNLPとCVのコミュニティで圧倒的な性能を示しました。[Vaswani et al, 2017; Kenton and Toutanova, 2019; Qiu et al, 2020; Han et al, 2021; Han et al., 2020; Khan et al., 2021; Selva et al., 2022]といった具合です。これらの分野でトランスフォーマーが持つ重要な利点の1つは、モデルサイズを大きくすることで予測力を高めることができることです。通常、モデル容量はトランスフォーマーのレイヤー数によって制御され、CVやNLPでは一般的に12~128の間で設定されます。
しかし、Table 3の実験に示すように、様々な層数のトランスフォーマーのモデルで予測結果を比較すると、3層から6層の最も浅いトランスフォーマーに軍配があがります。これは、モデルの容量を増やし、より良い予測性能を達成するために、深い層を持つ適切なトランスフォーマーアーキテクチャを設計する方法についての問題を提起しています。
季節性トレンド分解分析
最新の研究では、研究者[Wu et al., 2021; Zhou et al., 2022; Lin et al., 2021; Liu et al., 2022]が、時系列予測におけるトランスフォーマーの性能にとって季節-トレンドの分解が重要であることに気付き始めています。Table 4に示す簡単な実験として、[Wu et al., 2021]で提案された移動平均トレンド分解アーキテクチャを用いて、様々なアテンションモジュールをテストしています。季節トレンド分解モデルは、モデルの性能を50 %から80 %と大幅に向上させることができます。これはユニークなブロックであり、分解によるこのような性能ブーストは、トランスフォーマーのアプリケーションの時系列予測において一貫した現象であると思われ、さらに調査する価値があります。

将来研究の機会
ここでは、時系列におけるトランスフォーマーの研究において、潜在的に有望ないくつかの方向性を強調します。
時系列トランスフォーマーへの誘導バイアス
バニラトランスフォーマーはデータのパターンや特性について何の仮定も持ちません。長距離依存関係をモデル化するための一般的で普遍的なネットワークであるが、その代償として、すなわち、データのオーバーフィットを避けるためにトランスフォーマーを訓練するために多くのデータが必要であることも挙げられます。時系列データの重要な特徴の1つは、季節性/周期性とトレンドパターンです[Wen et al., 2019; Cleveland et al., 1990]。最近のいくつかの研究では、時系列トランスフォーマーに系列の周期性[Wu et al., 2021]や周波数処理[Zhou et al., 2022]を取り入れることで、性能を大幅に向上させることができることが示されています。したがって、今後の方向性の一つとして、時系列データの理解と特定のタスクの特徴に基づいて、トランスフォーマーに誘導バイアスをより効果的に導入する方法を検討することが挙げられます。
時系列用のトランスフォーマーとGNN
多変量時系列や時空間時系列はますます一般的になってきており、高次元の処理技術、特に次元間の根底にある関係を捕らえる能力が求められています。グラフニューラルネットワーク(GNN)の導入は、空間的な依存関係や次元間の関係をモデル化するための自然な方法です。最近、いくつかの研究により、GNNとトランスフォーマー/アテンションの組み合わせは、交通予測[Cai et al., 2020; Xu et al., 2020]やマルチモーダル予測[Li et al., 2021]のように大幅な性能向上をもたらすだけでなく、時空間ダイナミクスや潜在的偶然性のより良い理解も得られることが実証されています。トランスフォーマーとGNNを組み合わせて、時系列の空間-時間モデリングを効果的に行うことは、将来の重要な方向性です。
時系列用の事前学習トランスフォーマー
大規模な事前学習済みトランスフォーマーモデルは、NLP [Kenton and Toutanova, 2019; Brown et al., 2020] やCV [Chen et al., 2021a] における様々なタスクの性能を大幅に向上させました。しかし、時系列用の事前学習済みトランスフォーマーに関する研究は限られており、既存の研究は主に時系列分類に焦点を当てています[Zerveas et al., 2021; Yang et al., 2021]。したがって,時系列における様々なタスクのために,どのように適切な事前学習済みトランスフォーマーモデルを開発するかは,今後の検討課題として残されています。
時系列用のNAS付トランスフォーマー
埋め込み次元、ヘッド数、レイヤー数などのハイパーパラメーターは、トランスフォーマーの性能に大きく影響します。これらのハイパーパラメータを手動で設定するのは時間がかかり、最適でない性能になることが多いです。ニューラルアーキテクチャ探索(NAS)[Elsken et al., 2019; Wang et al., 2020]は、効果的なディープニューラルアーキテクチャを発見する手法として普及しており、NLPやCVにおけるNASを用いたトランスフォーマーの設計の自動化は最近の研究でも見られます [So et al., 2019; Chen et al., 2021c]。高次元かつ長尺になりうる産業スケールの時系列データに対して、メモリ効率と計算効率の両方に優れたトランスフォーマーアーキテクチャを自動的に発見することは実用上重要であり、時系列トランスフォーマーの重要な将来の方向性です。
まとめ
本論文では、様々なタスクにおける時系列トランスフォーマーに関する包括的なサーベイを提供しています。レビューされた手法を、ネットワークの修正とアプリケーションのドメインからなる新しい分類法で整理しています。各カテゴリーの代表的な手法を要約し、実験的評価によってその長所と限界を議論し、将来の研究の方向性を強調しました。 





この記事に関するカテゴリー






