完全教師無しで物体検出と背景のセグメンテーションを行うVAEベースの最新手法 "SPACE"
3つの要点
✔️ 完全教師無しで物体検出が可能
✔️ 完全教師無しで背景の構成要素ごとに分離可能
✔️ 下流タスクとして強化学習への応用の可能性
SPACE: Unsupervised Object-Oriented Scene Representation via Spatial Attention and Decomposition
written by Zhixuan Lin, Yi-Fu Wu, Skand Vishwanath Peri, Weihao Sun, Gautam Singh, Fei Deng, Jindong Jiang, Sungjin Ahn
(Submitted on 8 Jan 2020 (v1), last revised 15 Mar 2020 (this version, v3))
Comments: In proceeding of ICLR2020
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV); Machine Learning (stat.ML)
概要
近年、Object-oriented Representation Learning (OORL) という分野が多く研究されています※1。OORLにおいて教師なしでオブジェクトごとに分離する手法はVariational AutoEncoder (VAE: 変文自己符号化器) を用いた物体検出ベース (Spatial Attention-based) とVAEを用いた画像をオブジェクトごとの分離ベース (Scene Mixture-based) に分かれていました。
しかしながら、物体検出ベースは前景の物体を検出して分離することはできましたが、背景が既知でなければ使えませんでした。また、オブジェクトごとの分離ベースは非常に分離画像がボヤけている上、大量の前景オブジェクトがある場合にはうまく機能しませんでした。
今回紹介するOORLの最新手法であるSPACEは論文タイトルの通り、物体検出ベース (Spatial Attention-based) とオブジェクトごとの分離ベース (Scene Mixture-based) を組み合わせることで、大量の前景オブジェクトがある場合にも機能し、State of the Artのオブジェクトの分離性能を達成しました。
また、強化学習における定番データセットであるAtariデータセットにおいても有効に機能することを証明し、下流タスク※2として強化学習への応用可能性が見えています。
それでは見ていきましょう。
※1 OORLはオブジェクトに焦点を当てた何かしらの学習という分野ですが、本記事ではOORLをオブジェクトの分離に関する分野として定義して扱っていきます。
※2 下流タスク (Down stream task) とはタスクAを解決するためのモデルを活用するためのタスクBのことを指します。例えば、クラス分類で訓練済みの認識モデルを物体検出で使えば、物体検出が下流タスクに該当します。
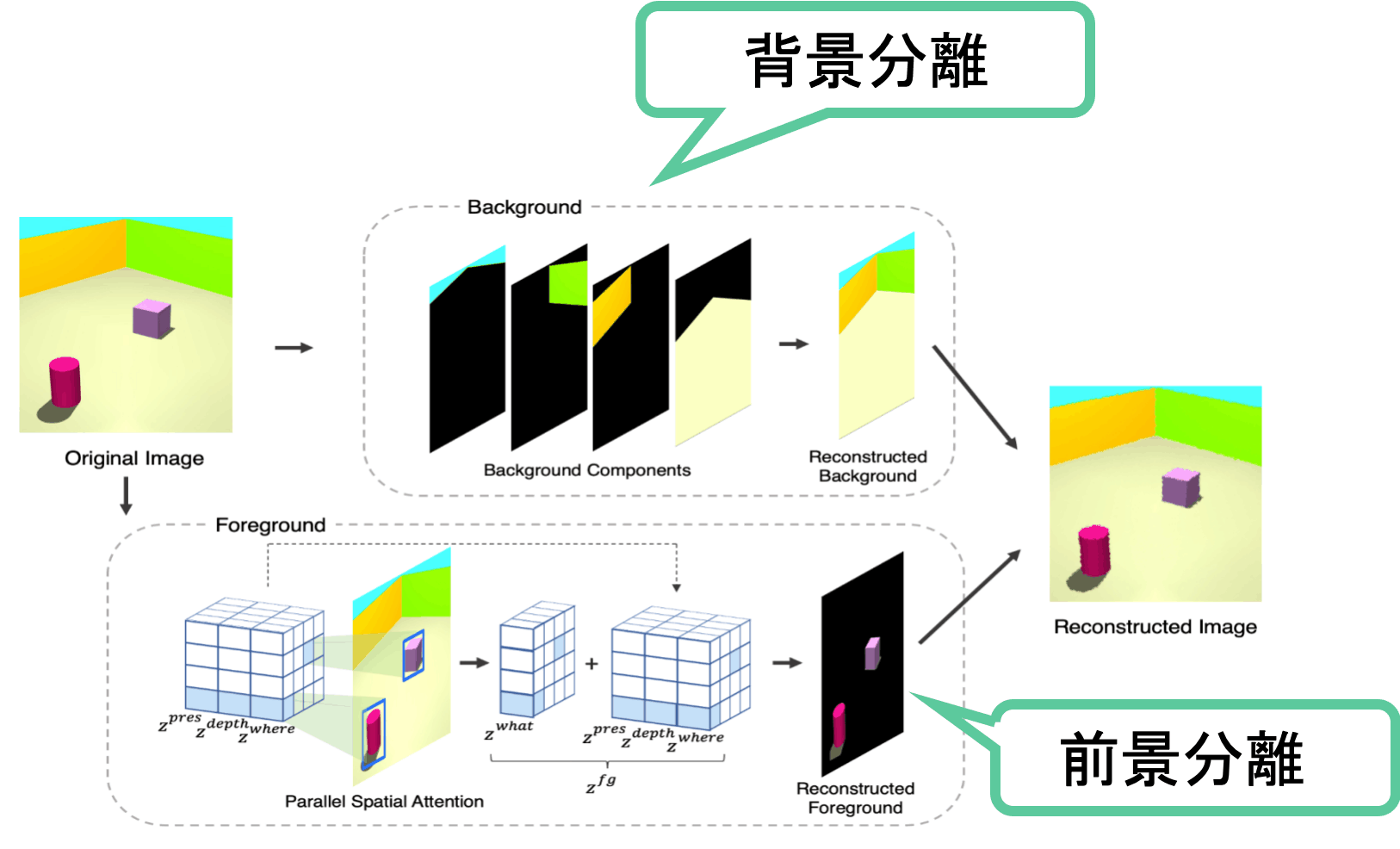
図1: SPACEの概要図
本論文のメインアイデアと貢献
メインアイデア
本論文のメインアイデアはシンプルです。前景の分離には教師無し物体検出であるSpatial Attentionベースの手法を用いて、背景の分離にはScene Mixtureベースの手法を用いるというものです※3。非常に合理的な発想ですね。
本論文を理解するためにはVAEとSpatial Attentionベースの手法、Scene Mixtureベースの手法を理解する必要があります。
※3 SPACEは、今までのSpatial Attentionベースの手法の処理の遅さを克服する工夫が取り入れられているのですが、SPACEの大筋とは関わりがないので、今回の記事ではさらっとのみ触れます。ご興味がある方はSPACEの論文中のBoundary Lossという項目をご参照ください。
続きを読むには
(6652文字画像10枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー

