
【InfiMM-WebMath-40B】24億の数学文書からなるデータセットでLLMの数学性能を向上させる!
3つの要点
✔️ 数学的推論能力を向上させるための大規模マルチモーダルデータセット「InfiMM-WebMath-40B」を提案
✔️ 24億のウェブページから収集したテキストと画像を組み合わせ、MLLMのトレーニングを最適化
✔️ MathVerseやWe-Mathベンチマークで優れた推論性能を示し、オープンソースモデルの限界を突破
InfiMM-WebMath-40B: Advancing Multimodal Pre-Training for Enhanced Mathematical Reasoning
written by Xiaotian Han, Yiren Jian, Xuefeng Hu, Haogeng Liu, Yiqi Wang, Qihang Fan, Yuang Ai, Huaibo Huang, Ran He, Zhenheng Yang, Quanzeng You
(Submitted on 19 Sep 2024)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
提案手法
この論文では、数学的推論能力を強化するための新しい大規模なマルチモーダル事前学習データセット「InfiMM-WebMath-40B」を提案しています。このデータセットは、24億の科学・数学関連のウェブドキュメントと、85億の画像URL、約400億のテキストトークンで構成されています。これにより、テキストと画像を組み合わせて処理する能力を持つ「Multimodal Large Language Models(MLLMs)」のトレーニングを支援し、特に数学の問題における推論能力を向上させることができます。
具体的には、このデータセットはCommonCrawlという大規模なウェブスクレイピングのリポジトリからデータを収集しています。まず、数十億件のウェブページから科学と数学に関連するページのみを選別し、そこからさらに画像とテキストが連動したデータをフィルタリングして作成しています。このプロセスには、特定のルールに基づくフィルタリングや、モデルベースのフィルタリング技術が使用されています。最終的には、2400万件の高品質なウェブドキュメントが生成され、数学的推論のトレーニングに最適化されています。
このデータセットを使用することで、従来のオープンソースモデルを超える性能を示すMLLMを構築できることが、いくつかの実験結果で確認されています。たとえば、「MathVerse」や「We-Math」といった最新のベンチマークでは、テキストと画像を効果的に組み合わせた問題解決が可能となり、特に視覚的な要素を含む数学的推論において大きな進歩を遂げています。
この手法により、特に数式やグラフ、図などが多用される複雑な数学の問題を効果的に解決できるMLLMの開発が加速されると考えられます。提案されたデータセットの大規模性と品質の高さが、オープンソースコミュニティ全体にとって非常に重要な資源となることが強調されています。
実験
この論文の実験では、InfiMM-WebMath-40Bデータセットの有効性を確認するために、いくつかのベンチマークを使用しています。実験の目的は、提案されたデータセットが大規模マルチモーダル数学推論モデル(MLLM)の性能をどれだけ向上させるかを検証することです。
まず、モデルのアーキテクチャは、視覚的な特徴を抽出するためにSigLipモデルを使用し、視覚とテキストの結合部分でPerceiver Resamplerを用いるという、最先端のビジョン・ランゲージ学習の手法に基づいています。2つのLLM(DeepSeek-Coder 1.3BとDeepSeek-Coder 7B)を使用して実験が行われました。
トレーニングは3段階で行われました。最初はモダリティの整合段階で、視覚とテキストのモダリティ間のギャップを埋めるため、一般的な画像とテキストのペアを使用して訓練しました。この段階では、視覚エンコーダーとLLMのバックボーンは固定され、Perceiver Resamplerのみが訓練されました。
次に、InfiMM-WebMath-40Bデータセットを用いた追加の事前訓練が行われ、マルチモーダルな数学的知識の獲得を強化しました。ここでは、コンテキスト長を4096トークン、最大32枚の画像を使用して1エポック分の訓練が行われました。
最後の段階では、命令データセットを使用したファインチューニングが行われました。この段階では、視覚エンコーダーは固定され、Perceiver ResamplerとLLMのパラメータが更新されました。訓練には、ScienceQAやDocVQAなどのデータセットが使用され、これにより命令追従能力が向上しました。
実験の結果として、InfiMM-WebMath-40Bを使用したモデルは、MathVerseとWe-Mathという2つのベンチマークで高い性能を発揮しました。特にMathVerseベンチマークでは、従来のオープンソースモデルを上回る成績を収め、We-Mathにおいても優れたマルチモーダル推論能力が示されました。特に7Bモデルでは、72Bや110Bの他のモデルに匹敵する性能が確認されました。
結論
この論文の結論では、InfiMM-WebMath-40Bが初の公開された大規模マルチモーダル数学事前学習データセットとして、オープンソースの研究コミュニティに重要な貢献を果たしたことが強調されています。このデータセットは、特に数学的推論において、テキストと画像を組み合わせた高度な学習を可能にし、複雑な数学的問題の解決能力を向上させるための基盤を提供しています。
InfiMM-WebMath-40Bを用いたモデルは、特にMathVerseとWe-Mathといった最新のベンチマークで優れた性能を発揮し、従来のオープンソースモデルよりも優れた結果を示しました。特に、7Bモデルは、72Bや110Bの他の大規模モデルに匹敵するパフォーマンスを達成しました。この成果は、InfiMM-WebMath-40Bの高品質なマルチモーダルデータセットが数学的推論能力を大きく強化することを示しています。
今後の研究としては、数学記号や図、式を効率的に処理するための視覚エンコーダの強化や、強化学習技術を用いて数学的推論能力をさらに向上させる計画が示されています。これにより、マルチモーダル数学推論の複雑さに対処し、さらに高精度なAIモデルを開発する道が開かれるとされています。
図表の解説
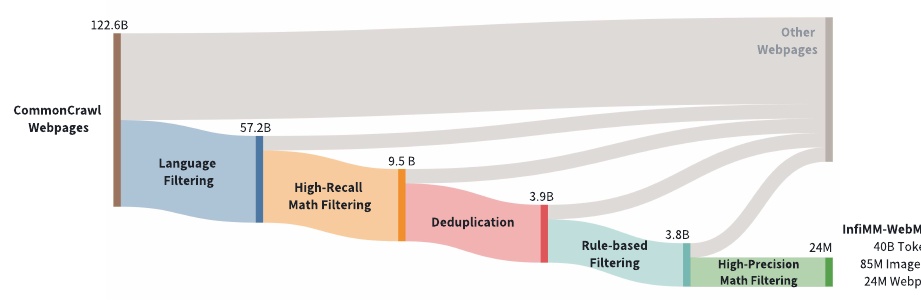
この図は、数学関連データセット「InfiMM-WebMath-40B」の構築プロセスを示しています。はじめに、CommonCrawlという大規模なウェブデータセットからスタートして、122.6億のウェブページが対象となります。
第一段階として、「Language Filtering」が行われ、言語ベースでフィルタリングされ57.2億のページに絞り込みます。続いて、「High-Recall Math Filtering」を適用し、関連する数学コンテンツを識別し9.5億ページとなります。
次に、「Deduplication」によって、重複するデータを削除し3.9億ページに減らされます。このプロセスを経て、「Rule-based Filtering」が行われ、より不必要な要素を除去します。この段階でのデータ数は3.8億ページです。
最後に「High-Precision Math Filtering」により、高精度な数学コンテンツだけを残し、最終的に約24万ページが選ばれます。この24万ページには、40億のテキストトークンと8500万の画像が含まれています。このフィルタリングプロセスにより、数学に特化した高品質なデータセットが構築されます。
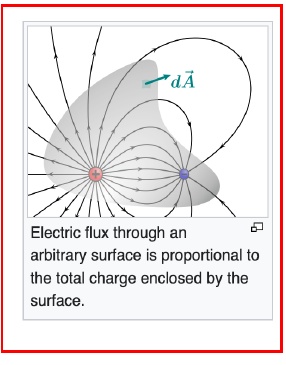
この図は、ガウスの法則に関連する「電気フラックス」の概念を視覚的に説明しています。図には、曲面のような形の中に電荷があり、その周りに電場の線が描かれています。これらの電場線は、電荷の周囲にどのように電場が広がっているかを示しています。
図の中央には、正と負の電荷が示されており、それに向かってまたはそこから離れる形で電場線が配置されています。電気フラックスは、この面を通過する電場線の合計を指し、面によって囲まれた電荷の総和に比例します。つまり、囲まれた電荷の量が多いほど、電気フラックスも大きくなるということです。
dAのベクトルは、面のちょうどその部分での微小なエリア要素を表し、電場線と面の関係性を描写しています。この図は、物理学や電磁気学において、重要な概念の理解を助けるビジュアル教材の一部として役立ちます。
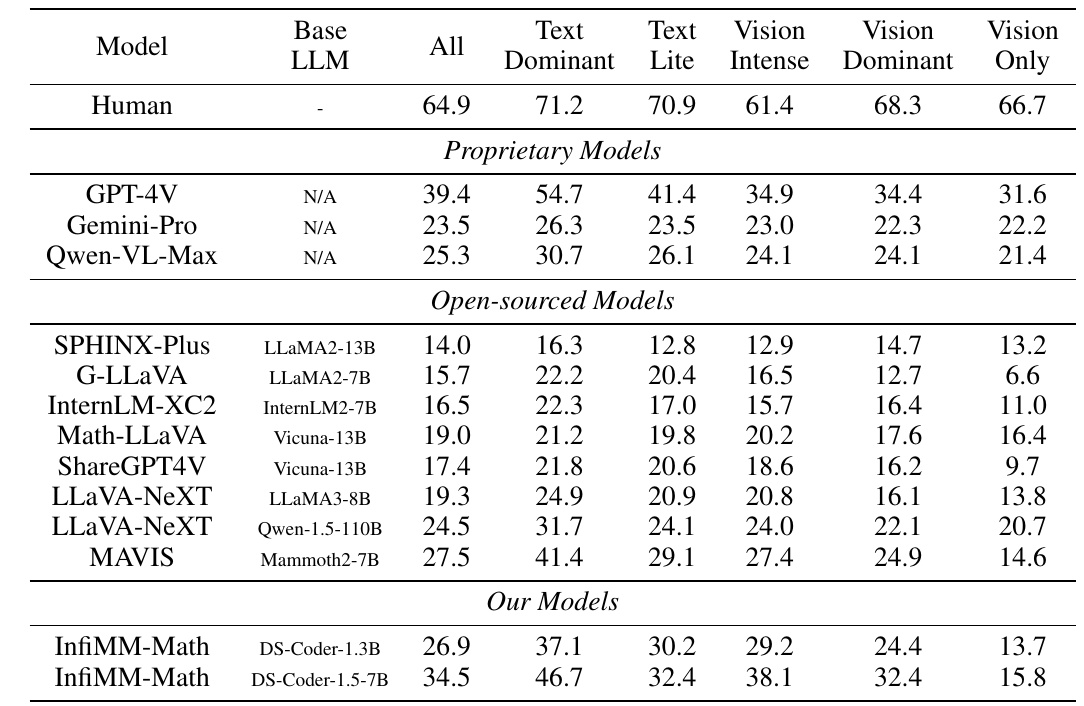
この表は、さまざまなモデルの性能を評価したものです。
- 表の最初の列にはモデル名が示されています。「Human」は人間のパフォーマンスの基準を示しています。
- 次に、「Base LLM」は各モデルが基礎としている大規模言語モデル(LLM)の種類を示します。
- 「All」列は、すべてのタイプのタスクでの総合スコアを表しています。
- 続く列には、タスクの特性に応じたスコアが示されています:「Text Dominant」はテキストが主な情報源のタスク、「Text Lite」はテキスト情報が少ないタスク、「Vision Intense」は画像情報が多いタスク、「Vision Dominant」は画像がメインの情報源のタスク、「Vision Only」は完全に画像情報のみのタスクを表します。
この表では、「Proprietary Models」としてGPT-4V、Gemini-Pro、Qwen-VL-Maxの3つの非公開モデルが評価されています。また、「Open-sourced Models」は、公開されているモデル群で、中でもSPHINX-Plus、G-LLaVA、InternLM-XC2、Math-LLAVAなどがあります。
最後に、「Our Models」には、InfiMM-Math DS-Coder-1.3BとDS-Coder-1.5-7Bの2つのモデルが記載されています。これらのモデルは、一部のスコアで他のオープンソースモデルを上回る結果を示しています。
全体的に見ると、InfiMM-Mathモデルは特に「All」や「Text Dominant」、「Vision Intense」で高いパフォーマンスを発揮し、視覚情報とテキスト情報を組み合わせたタスクにおける優位性を示しています。これは、機械学習の初心者でも理解しやすいように、視覚とテキストの両方を用いる複雑なタスクでの能力を向上させるための設計の成果です。
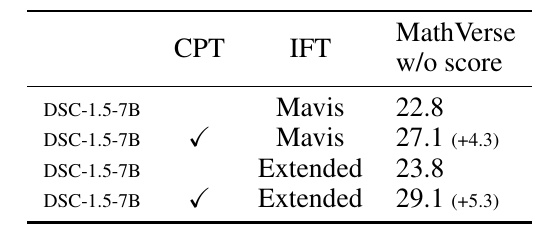
この図は、機械学習モデルの評価結果を示しています。具体的には、DeepSeek-Coder 1.5-7Bモデルの異なるトレーニング設定におけるMathVerseという評価基準でのスコアを比較しています。
表には二つの主なトレーニング手法があります。CPT(Continue Pre-training)とIFT(Instruction Fine-Tuning)です。これらはモデルの性能を向上させる方法です。
- 「Mavis」および「Extended」という二種類のデータセットを用いた結果が示されています。
- CPTを用いない場合、Mavisデータセットで22.8のスコアが得られていますが、CPTを用いることで27.1と向上しています。
- Extendedデータセットでは、CPTを用いることでスコアが23.8から29.1に向上しています。
この表から、CPTを用いると模型の性能が高まることがわかります。特に、より多様なデータを使うExtendedデータセットでの向上が顕著です。
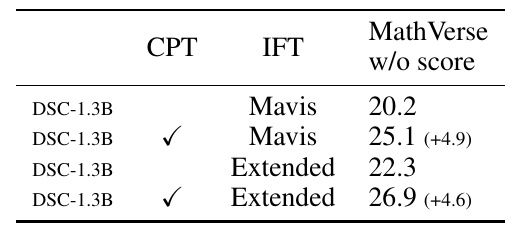
この表は、ある機械学習モデルで行った実験の結果を示しています。具体的には、「CPT」と「IFT」という二つの異なる訓練手法が組み合わされたときの効果を測っています。
- 「CPT」は、Continual Pre-Trainingの略で、既存のデータセットを使いながらモデルを再訓練する手法です。
- 「IFT」は、Instruction Fine-Tuningの略で、指示に基づいたデータセットでモデルを調整する手法です。
表には、以下のような情報が示されています。
- 「DSC-1.3B」は、使用されたモデルの名前です。
- 「Mavis」と「Extended」は、異なるデータセットの名前です。
- 「MathVerse w/o score」は、MathVerseという評価基準でのスコアを示しています。そのスコアは、数学的な問題を解く能力を測っています。
- 例えば、「Mavis」データセットのみで評価した場合のスコアは20.2ですが、「CPT」を行うと25.1に向上しています。
これらの結果は、異なる訓練手法を組み合わせることで、モデルの性能が向上することを示しています。それぞれのスコア向上幅も詳細に示されているため、手法の効果を具体的に理解するのに役立ちます。
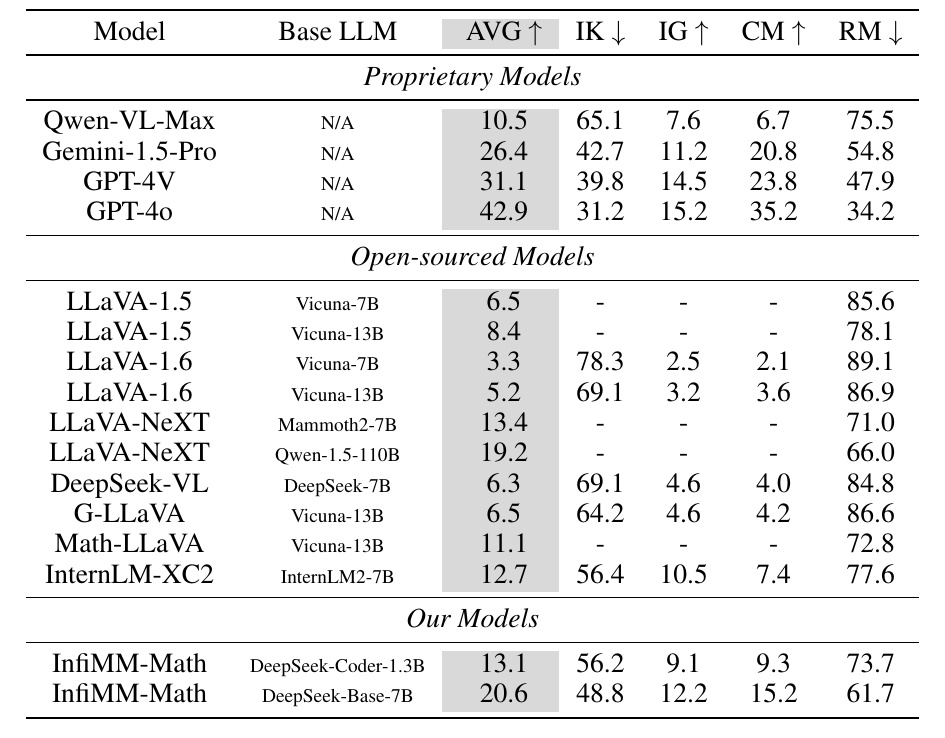
この表は、さまざまな言語モデル(LLM)がWe-Mathという数学に関するベンチマークでどの程度の性能を発揮するかを比較しています。
ModelとBase LLMの列:
- Modelの列には各モデルの名称が記載され、その下に使われている基本モデル(Base LLM)が示されています。
- Base LLMは自然言語処理に使用される主要なモデルで、各モデルで利用されています。
Proprietary Models:
- これらは企業によって所有されている非公開モデルです。
- Qwen-VL-MaxやGPT-4oなど、性能の異なるさまざまなモデルがあります。
Open-sourced Models:
- 公開されているオープンソースのモデルです。
- LLaVAシリーズやDeepSeek-VLなどが含まれ、多くのモデルが記載されています。
Our Models:
- これは研究チームが自ら開発したモデルです。
- InfiMM-MathがDeepSeek-Coder-1.3BとDeepSeek-Base-7Bのベースモデルを使用していることがわかります。
パフォーマンス指標:
- AVGは平均性能スコアを示します。高いほど全体的に優れていることを意味します。
- IK(Insufficient Knowledge)は知識不足の場合の割合で、低いほど良好です。
- IG(Inadequate Generalization)は不十分な一般化の指標で、この値が高いほど優れています。
- CM(Complete Mastery)は完全な理解度を示し、高いことが望ましいです。
- RM(Rote Memorization)は丸暗記の割合で、低い方が自然な理解を示します。
この図表は、それぞれのモデルがどの程度の性能を持つかを視覚的に容易に把握できるようにするためのものです。モデルの全体的なマスター能力や知識の欠如を測定する手段として役立ちます。また、独自開発のモデルが他の公開モデルと比較しても競争力があることを示しています。
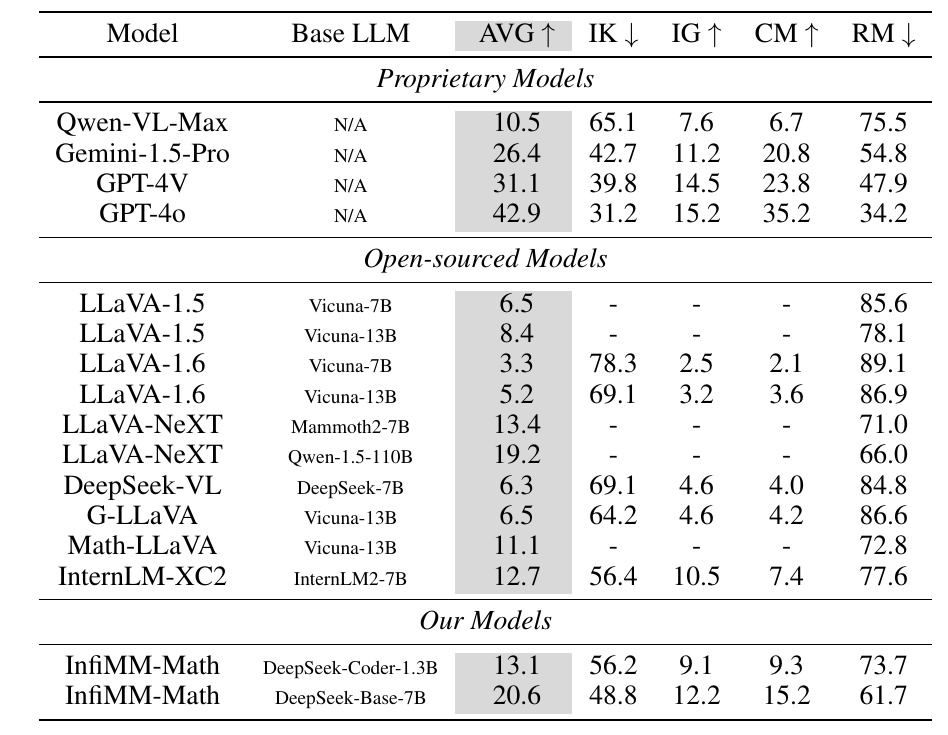
この図は、さまざまな機械学習モデルのパフォーマンスを比較した表です。各モデルの平均スコア(AVG)や、特定の評価基準に基づくスコア(IK、IG、CM、RM)が記載されています。
- 「Proprietary Models」というカテゴリには、Qwen-VL-MaxやGPT-4Vなど、専有モデルが含まれており、それぞれ異なる評価指標でスコアが示されています。例えば、GPT-4oは他のモデルと比較して特に高い「CM」スコア(35.2)を持っています。
- 「Open-sourced Models」というカテゴリには、LLaVAシリーズやMath-LLaVAなどのオープンソースモデルが含まれています。これらのモデルは、専有モデルと比較して一般的にAVGスコアが低い傾向にありますが、視覚情報を重視したモデルも見受けられます。
- 「Our Models」には、InfiMM-Mathという独自のモデルが示されており、DeepSeek-Coder-1.3BやDeepSeek-Base-7Bといった基本モデルを使用しています。これらのモデルは、一部の評価基準(IK、IG、CM)で他のオープンソースモデルと同等以上のスコアを記録しています。
この表は、異なるモデルの性能における強みや弱みを一目で理解するためのものであり、特に数学的な推論能力に関心を持つ人々にとって有用です。

この表は、分類モデルの評価結果を示しています。使われたモデルは「LLM-Classifier」と「FastText-Classifier」の2種類です。それぞれのモデルでMMLU(STEM)とGSM8Kというベンチマークでのスコアが記載されています。
まず、「MMLU(STEM)」とは、さまざまな科学・技術分野の知識を測定するための評価で、LLM-Classifierが32.8、FastText-Classifierが31.1のスコアを獲得しています。次に、「GSM8K」は数学的推論を評価するベンチマークで、LLM-Classifierは17.5%のスコア、FastText-Classifierは20.2%のスコアです。これにより、GSM8Kにおいては、FastText-Classifierが優れていることが分かります。
また、テキストの平均長さも示されており、LLM-Classifierは平均して2500、FastText-Classifierは平均して1700の長さです。このことから、FastText-Classifierの方が掲載情報が少ない場合でも、効果的である可能性が示唆されています。



この記事に関するカテゴリー



