V3D: 3D Object Generation From A Single Image
3 main points
✔️ Automatic 3D generation has received widespread attention recently, and while the latest methods have significantly increased generation speed, model capacity and 3D data limitations have led to the generation of objects lacking in detail
✔️ V3D incorporates geometric consistency and multi-view consistency into learning and video diffusion V3D aims to solve this challenge by incorporating geometric consistency into learning and leveraging video diffusion models
✔️ Extensive experiments have demonstrated the superior performance of the proposed approach. In particular, it shows excellent results in terms of production quality and multi-view consistency
V3D: Video Diffusion Models are Effective 3D Generators
written by Zilong Chen, Yikai Wang, Feng Wang, Zhengyi Wang, Huaping Liu
(Submitted on 11 Mar 2024)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
Recent advances in AI have enabled technologies to automatically generate 3D content. While there have been significant improvements in this area, there are still some challenges with current methods. Some approaches are slow and produce inconsistent results, while other methods require training on large 3D data sets, limiting the use of high-quality image data.
This commentary paper focuses on the generation of 3D content using video diffusion models. Video diffusion models are typical models that generate detailed and consistent video scenes. Because many videos naturally capture objects from different angles, these models help us understand the 3D world.
In this paper, we propose a new method called V3D, which uses a video diffusion model to generate multiple viewpoints of an object or scene and reconstructs the 3D data based on those viewpoints. This approach is applicable to both individual objects and large scenes.
In generating3Dobjects, models are trained using videos of 3D objects rotating 360 degrees to improve accuracy. It also introduces new losses and model structures to improve the consistency and quality of the generated viewpoints.
To make this method practical in the real world, we also propose a method for creating 3D meshes from the generated data. The method has also been extended to include scene-level 3D generation, allowing for accurate camera path control and handling of multiple input viewpoints.
Extensive experiments, including qualitative and quantitative evaluations, have demonstrated the superior performance of the proposed approach. In particular, it significantly outperforms previous studies in terms of generation quality and multi-view consistency. It is expected that the proposed approach will overcome the limitations of current 3D generation techniques and open up new possibilities for AI-based 3D content generation.
Proposed Method
Summary
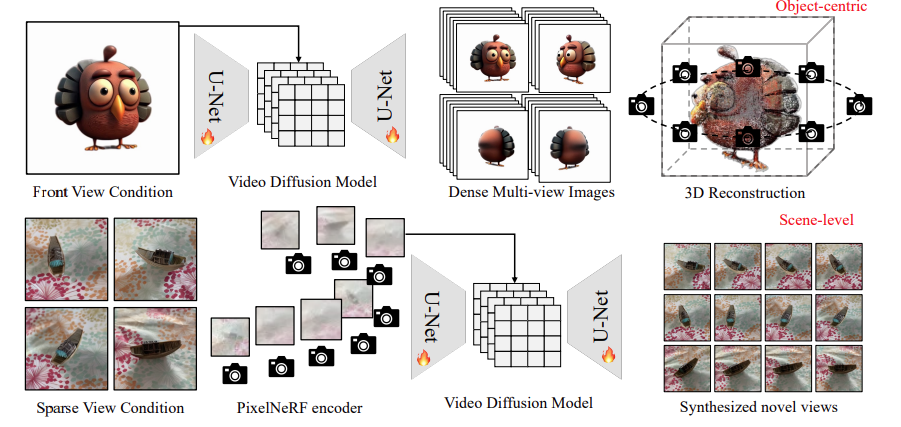
As shown in Figure 1, V3D leverages a video generation model to take advantage of the structure and strong prior knowledge of large, pre-trained video diffusion models to facilitate consistent multi-view generation.
For 3D generation from object images, the base video diffusion model is fine-tuned with a 360-degree orbital video of a synthetic 3D object drawn at a fixed circular camera position, and a reconstruction and mesh extraction pipeline suitable for the generated multiple views is proposed.
Scene-level 3D generation incorporates the PixelNeRF encoder into the base video diffusion model to precisely control the camera position in the generated frames, allowing it to seamlessly adapt to any number of input images. Details are as follows.
360-Degree View Generation from Images of Target Object
To generate multi-view images from a single viewpoint, V3D interprets continuous multi-view images rotating around an object as video, treating multi-view generation conditional on frontal viewing as a form of image-to-video generation. This approach addresses the scarcity of 3D data by leveraging the comprehensive understanding of the 3D world provided by large, pre-trained video diffusion models. It also takes advantage of the inherent network architecture of the video diffusion model to effectively generate a sufficient number of multi-view images.
Specifically, wefine-tunedStable Video Diffusion (SVD, Blattmann et.al, 2023),a representative model for video generation, on the Objaverse dataset. To enhance image-to-3D adaptation, we removed irrelevant conditions such as motion bucket IDs and FPS IDs and made it independent of altitude angle. Instead, we randomly rotated the object to allow the generated model to respond to inputs with non-zero altitude.
Robust 3D Reconstruction and Mesh Extraction
∙ 3D Reconstruction
After acquiring an imagearound an objectusing afine-tunedvideo diffusion model, thenext step is to reconstruct it into a 3D model. 3D Gaussian Splatting (Kerbl et.al, 2023) is used for this task.
Ensuring per-pixel consistency between views is difficult and can easily introduce artifacts in the 3D reconstruction. To solve this problem, we take advantage of the per-pixel loss of MSE.In addition, image-level perceptual and similarity losses are introduced toprevent floating or blurry texturesdue to MSE. The final loss is defined as follows

∙ Mesh Extraction
A mesh extraction pipeline for the generated views is also proposed to meet the requirements of real-world applications. For fast surface reconstruction, NeuS ( Wang etl.al, 2021) using a multi-resolution hash grid will be employed; V3D will apply normal smooth loss and sparse regularization loss to improve geometry to generate fewer views than the usual NeuS use case V3D applies normal smooth loss and sparse regularization loss to improve geometry.
To improve blurry textures resulting from inconsistent generated images, textures are refined in the generated multiview using LPIPS loss, while geometry is kept unchanged. This process is completed in less than 15 seconds with efficient differentiable mesh rendering, improving the quality of the final output.
Extension to Scene-Level 3D Generation
Unlike object view generation, scene-level 3D generation requires images to be generated along the camera's path, requiring precise control of the camera's orientation and accommodating multiple input images.
To address this challenge and maintain consistency, V3D integrates the PixelNeRF feature encoder into the video diffusion model, as shown in the lower part of Figure 1.feature mapsextracted by PixelNeRFare concatenated into the U-Net input to explicitly encode relative camera pose information.
This approach can seamlessly support any number of images. Other settings and architecture of the model are similar to object-centric generation.
Experiment
Object-Centric 3D Generation

In this section, we evaluate the performance of the proposed V3D in image-to-3D conversion and discuss the comparison results with other methods. In the upper part of Figure 2, V3D shows better quality than 3DGS-based TriplaneGaussian and LGM. These methods produce a blurry appearance due to the limited number of Gaussians they generate.
At the bottom of Figure 2, V3D outperforms the latest SDS-based Magic123 and ImageDream in front view consistency and fidelity, while Magic123 has inaccurate geometry and blurred backs, and ImageDream produces oversaturated textures. The proposed method achieves results in less than 3 minutes and is significantly faster than optimization-based methods.
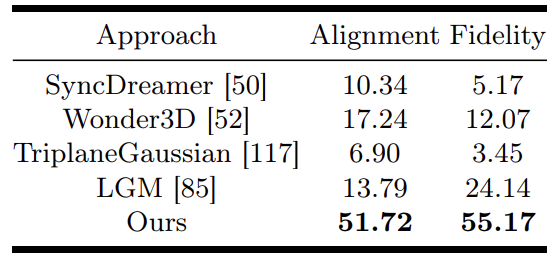
Meanwhile, a human evaluation study was conducted on the generated 3D objects. Specifically, 58 volunteers were asked to evaluate objects generated by V3D and other methods while viewing a 360° spiral video rendered based on 30 condition images. The two evaluation criteria were
- (a) Consistency: how well the 3D asset matches the condition image
- (b) Fidelity: how realistic the generated objects are.
Table 1 shows the win rates for these two criteria for each method.
V3D was rated the most compelling model overall, significantly outperforming other competing methods in both image consistency and fidelity.
Scene-Level 3D Generation
The performance of the proposed V3D in generating scene-level 3D was tested on a 10-category subset of the CO3D dataset. Only one epoch of V3D was fine-tuned in each category of video to match the same settings as in the previous study.
Results are shown in Table 2.
The proposed method consistently outperforms prior studies in terms of image metrics, demonstrating the effectiveness of using pre-trained video diffusion models for scene-level 3D generation. The zero-shot version of V3D (trained exclusively on MVImgNet) also performs well, outperforming most prior studies.
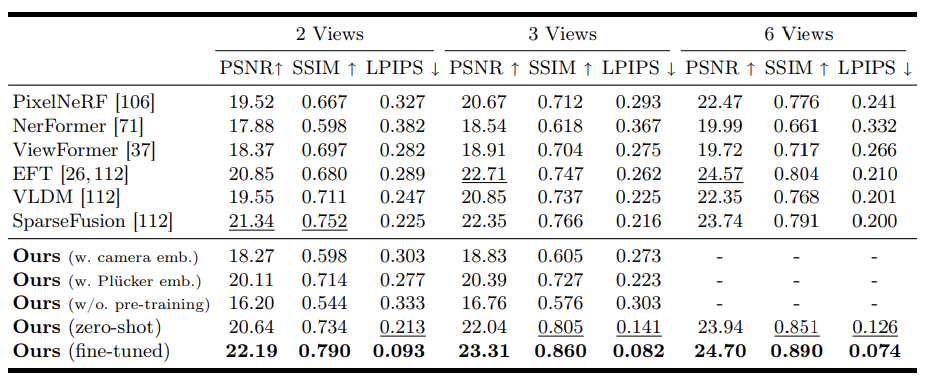
Figure 3 shows a qualitative comparison of the multiviews generated by SparseFusion and V3D on the fire hydrant subset of the CO3D dataset. To further refine the comparison, a multi-view stereoscopic reconstruction was performed in COLMAP using camera poses, and Figure 3 shows the number of points in the resulting point cloud and the Chamfer distance to the point cloud reconstructed from the real image.
It has been shown that point clouds reconstructed from images generated by V3D contain more points and are closer to point clouds reconstructed from real images.In other words, the proposed method shows significant advantages in both reconstruction quality and multi-view consistency.

Conclusion
This article introduced V3D, which generates a 3D object from a single image.
V3D utilizes a video generation model and leverages the structure and rich prior knowledge of a large pre-trained video diffusion model to achieve consistent multi-view generation.Wealsoproposed anew reconstruction pipeline and learning loss to achieve consistent and highly accurate 3D object reconstruction.
Through extensive qualitative, quantitative, and human evaluations, the superior performance of the proposed approach was demonstrated. In particular, it significantly outperforms previous studies in terms of generation quality and multi-view consistency. It is expected that the proposed approach will break through the limitations of current 3D generation technologies and open up new possibilities for 3D content generation by AI.



Categories related to this article