
ExpeL, An LLM Agent That Learns Autonomously From Experience, Is Now Available!
3 main points
✔️ Propose ExpeL, a new LLM agent that learns autonomously from training tasks
✔️ Two modules, Experience Gathering and Insights Extraction, allow the agent to learn autonomously from experience
✔️ Experience of tasks By accumulating task experience and learning autonomously, ExpeL outperforms existing methods in comparative experiments
ExpeL: LLM Agents Are Experiential Learners
written by Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, Gao Huang
(Submitted on 20 Aug 2023)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
In the history of machine learning, researchers have long explored the potential of autonomous agents, and recently the incorporation of large-scale language models (LLMs) into these agents has found a variety of applications across disciplines.
While one of the major advantages of LLM is its wealth of knowledge and its versatility in a variety of tasks, its high computational cost has been cited as a problem due to the large amount of human-labeled data sets required.
In addition, while fine-tuning L LMs has recently become a popular technique, it has been found that fine-tuning LLMs for specific tasks is not only resource-intensive, but can also degrade the generalizability of the model.
To address these issues, this paper describes a paper that proposes ExpeL, a new LLM agent that autonomously collects and extracts experience (experience) from training tasks, extracts knowledge using natural language, and makes informed decisions.
ExpeL: Experiential Learning Agent
Our human learning is mainly carried out by two types of processes
- Store the process of a successful task in memory and call (retrieve) it as a concrete example for reference when performing a new task
- Extracts high-level insights from experience with tasks performed and enables generalization to new tasks
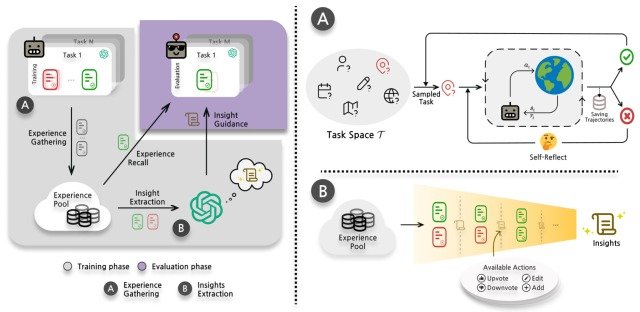
ExpeL implements the first process by a module calledExperience Gathering and the second process by a module called Insights Extraction, and the overall process is shown in the figure below.
Let's look at each of these.
Experience Gathering
When we humans perform an inexperienced task, we go through a process of "remembering and referring to memories of similar tasks that we have solved before.
Motivated by this, the paper proposes experience recall, a method that "retrieves successful processes from the experience pool collected during training based on task similarity.
In this method, the agent interacts with the environment during the learning phase , collects experiences through an experience collection process using existing research on reflection, and stores them in an experience pool, the Faiss vectorstore.
When actually performing the evaluation task, kNN retriever and all-mpnet-base-vs embedder are used to find and execute the above k successful processes that have the maximum similarity between the evaluation task and the inner product task (tasks collected so far).
Here, each time the agent finishes a task or reaches the maximum number of steps, the ExpeL agent repeats the process of storing the collected experience in a pool and moving on to the next task.
Insights Extraction
To take advantage of the variety of results collected in Experience Gathering, agents extract insights from the experience and generalize them to new tasks in two different ways
- Have agents compare failed and successful processes in the same task
- Have agents identify patterns from successful processes of different tasks
To perform the above analysis, the implementation creates an empty set of insights, gives the LLM a list of failed/successful pairs or successful processes from the experience pool, and the LLM performs one of the following four actions on the set of insights based on the list
- ADD: Add new insights
- UPVOTE: Vote in favor of existing insights
- DOWNVOTE: Vote against existing insights
- EDIT: Edit the contents of an existing insight
The template used to perform the above process is shown below.

This structure allows users to smoothly add insights to the agent, reduces computational resources due to the small amount of data required, and is easy to implement.
In addition, while self-improvement methods such as Reflextion promote intra-task improvement, ExpeL enables inter-task learning, making it independent of a specific domain and thus gaining a versatility not found in existing research.
Experiments
To demonstrate the effectiveness of ExpeL, this paper conducted a comparison experiment with an existing model based on the following benchmark tasks.
- HotpotQA: Tasks that let agents perform inference and question answering using the Wikipedia Docstore API, a search tool.
- ALFWorld: Tasks that let agents perform interactive decision-making tasks in a virtual environment that mimics the home
- WebShop: Tasks that let agents perform interactive decision-making tasks in a virtual environment that mimics an online shopping site
Seven different models were used in the experiment: Imitation Learning, ExpeL(insights-only),ExpeL(retrieve-only),ExpeL(ours),Act, ReAct, and Reflextion.
Here, Imitation Learning is a type of reinforcement learning, ExpeL (insights-only) is a model that does not perform similar task search in ExpeL, and ExpeL (retrieve-only) is a model that does not extract insights as well.
In addition, each benchmark task was not performed separately, but rather consecutively in the order HotpotQA, AFLWorld, and WebShop.
The results of the experiment are shown in the figure below.
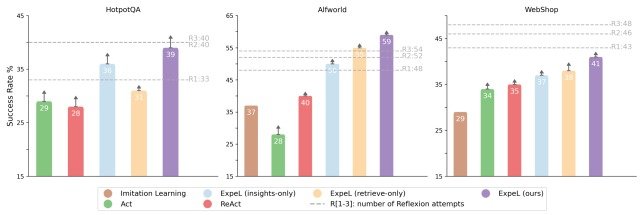
The figure shows that ExpeL consistently outperforms the existing model in all tasks, demonstrating the effectiveness of this method.
In addition, comparing the performance of ExpeL (insights-only) and ExpeL (retrieve-only) confirms that task similarity search and insight extraction are both essential and synergistic in ExpeL.
Another important finding is the comparison with the Reflextion model, where ExPeL performs as well as Reflextion in HotpotQA and better than Reflextion in ALFWorld.
This indicates that Reflextion improves performance on a task-by-task basis by repeating task execution (R1, R2, R3), whereas ExpeL accumulates experience on each task, allowing it to learn across tasks.
On the other hand, in WebShop, ExpeL performed below Reflextion, suggesting that there is still room for improvement.
Summary
How was it? In this article, we described a paper that proposed ExpeL, a new LLM agent that autonomously collects and extracts experience (EXPERIENCE) from training tasks, extracts knowledge using natural language, and makes informed decisions.
The ability to learn autonomously from experience is essential for the development of human-like intelligent agents, and the ExpeL proposed in this paper is a very promising first step.
On the other hand, the experiments conducted in this study were limited to text-based tasks only, and the author noted that the Vison Language model and caption model could be applied to more general tasks by incorporating image information, and future progress will be closely watched.
The details of the ExpeL architecture and experimental results presented in this paper can be found in this paper for those who are interested.



Categories related to this article






