What Are The Data Set Requirements For Successful Self-supervised Controlled Learning?
3 main points
✔️ Analyze self-supervised contrastive learning on four large image datasets
✔️ Investigate the impact of datasets in terms of data volume, data domain, data quality, and task granularity
✔️ Show what we know about the preferred dataset conditions for successful self-supervised learning
When Does Contrastive Visual Representation Learning Work?
written by Elijah Cole, Xuan Yang, Kimberly Wilber, Oisin Mac Aodha, Serge Belongie
(Submitted on 12 May 2021 (v1), last revised 4 Apr 2022 (this version, v2))
Comments: CVPR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
first of all
Self-supervised contrastive learning, pre-trained by ImageNet, has been successfully used to generate valid visual representations for many downstream tasks.
Can the success of such self-supervised contrastive learning be reproduced on other datasets than ImageNet? And under what conditions does self-supervised contrastive learning succeed?
In the paper presented in this article, we answer this question by studying self-supervised contrastive learning on four large data sets.
More specifically, we investigated the impact of data volume, dataset domain, data quality, and task granularity on self-supervised contrast learning during pre-training.
experimental setup
We first describe the experimental setup for examining the effect of the dataset on self-supervised controlled learning.
data-set
In our experiments, we use four large datasets, described next.
- ImageNet: 1.3M image dataset consisting of 1k classes (using ILSVRC2012 subset of ImageNet-21k dataset)
- iNat21: 2.7M animal and plant image dataset consisting of 10k classes
- Places365: 1.8M image dataset consisting of 365 classes (using "Places365-Standard(small images)" where all images are resized to 256x256)
- GLC20):1M remote sensing image dataset consisting of 16 classes
About fixed size subsets
In our experiments, we also use selected subsets of 1M, 500k, 250k, 125k, and 50k images from each dataset to investigate the effect of sample size.
This subset is sampled only once and the images are selected uniformly and randomly. Each subset is nested, e.g. ImageNet(500k) contains all images from ImageNet(125k). Also, the test set is identical regardless of the training subset used.
Learning Details
In the paper, we mainly experiment with SimCLR. We use ResNet-50 as the backbone and follow standard protocols (self-supervised learning followed by linear classifier or end-to-end fine-tuning).
experimental results
In our experiments, we investigated the effects of data quantity, dataset domain, data quality, and task granularity on control learning.
amount of data
First, we consider the amount of data in self-supervised contrastive learning.
Here, there are two important notions of data volume, which are described below.
- Number of unlabeled images used in pre-training
- Number of labeled images used to train the classifier
Of these two, labeled images are an effect, and it is desirable to learn a representation that can be generalized to as few as possible. And while unlabeled images are inexpensive to obtain, they are proportionally related to the cost of pre-training.
To investigate the relationship between these two data volumes and performance, we train SimCLR on various numbers of unlabeled images and evaluate the results when evaluated on various numbers of labeled images. The results are as follows.
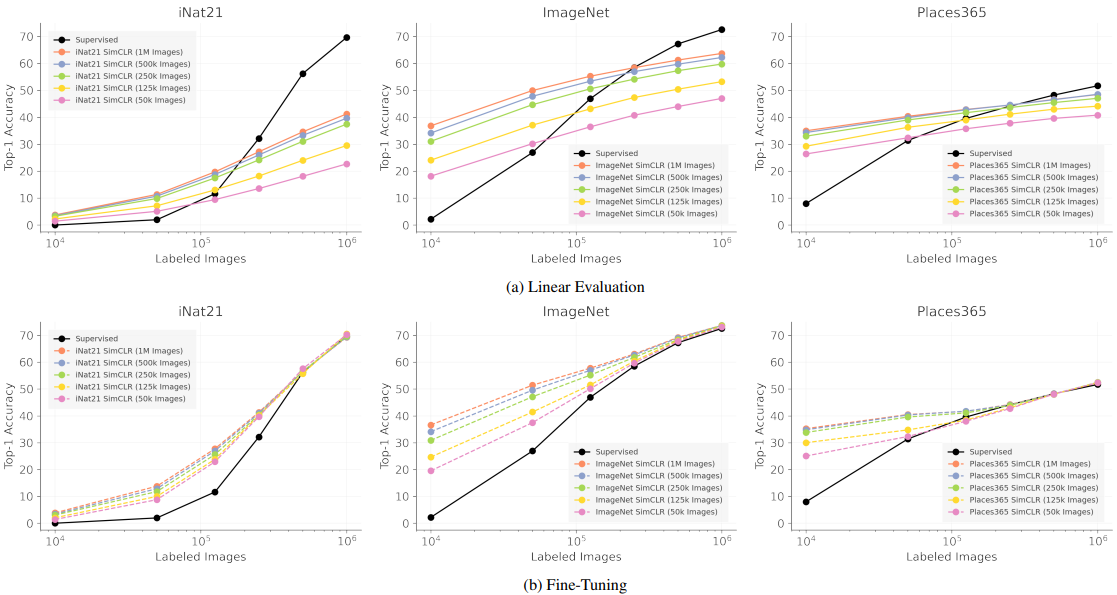
Supervised corresponds to the result of learning from scratch.
The implications of these results are as follows.
- Using more than 500k images during pre-training is not very effective: when 500k or 1M images are used for pre-training, the Top-1 accuracy degradation is limited to 1-3%, and the pre-training time can be significantly reduced in exchange for a small accuracy degradation.
- Self-supervised learning (SSL) is a good initialization when the number of supervised images is limited: Fine-Tuning of the SimCLR representation shows very good results when the number of labeled images is around 10k or 50k.
- For the self-supervised representation to perform close to the fully supervised representation, a large number of labeled images is required: although the ultimate goal of self-supervised learning is to achieve comparable performance to supervised learning with only a small amount of labeled data, the difference between the performance of fully supervised learning (right end of the black curve) and the performance with few labeled images performance and the performance difference between the fully supervised learning (right side of the black curve) and the case with few labeled images remains very large.
- iNat21 is valuable as an SSL benchmark: a very large performance difference exists between self-supervised and supervised learning on the iNat21 benchmark, making it an important benchmark for future research.
data domain
Next, we investigate which images belonging to which domains should be used for pre-training.
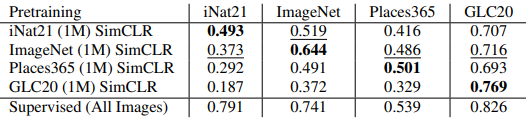
Here is the linear classifier fine-tuning evaluation when SimCLR is trained on iNat21 (1M), ImageNet (1M), Places365 (1M) and GLC20 (1M).
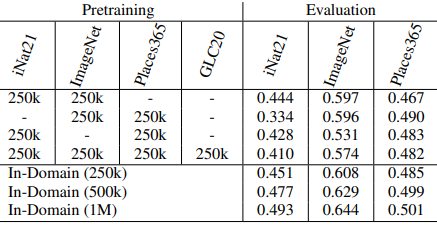
The combined results for these datasets are also shown below.
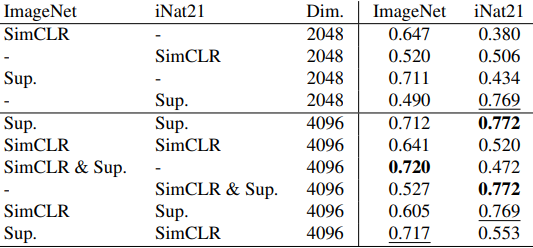
Furthermore, the results of using the fused representation obtained by concatenating the respective representation outputs are as follows.
From these results, the following findings were obtained concerning the data domain.
- The pre-training data domain is important: when the domain is the same as when pre-training (on the diagonal in the first table), the results are consistently better than in the cross-domain case. SimCLR trained on ImageNet also shows the best cross-domain performance, suggesting that better results are obtained when the data domains of the pre-training and downstream tasks are similar.
- Adding cross-domain pre-training data does not necessarily lead to a general representation: the second table shows the results when fusing different datasets. However, the results are consistently worse when fusing different datasets than using a single pre-trained dataset (In-Domain). This result can be attributed to the fact that the contrast learning task during pre-training is easier when different domains are included in the dataset.
- Self-supervised representations can be largely redundant: the third table shows the results when fusing representations of models trained with ImageNet and iNat21. The results show that the performance change (-0.6% or +1.4%) for the combination of ImageNet SimCLR and iNat21 SimCLR is small compared to the difference in their respective representation performance (>12%), suggesting that these representations are redundant. The performance change is also larger (+4.7% or -4.2%) when combining supervised and self-supervised representations.
data quality
Next, we investigate the effect of pre-training data quality on performance. Specifically, we experiment with the results when only the pre-training data is artificially degraded. The results are as follows.
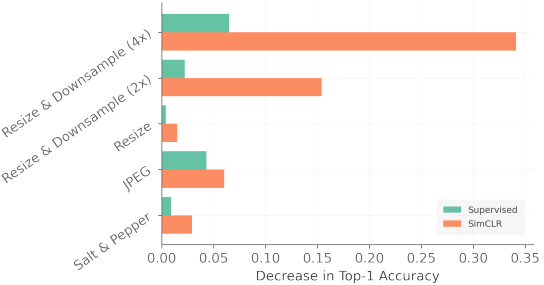
Findings from the results are as follows
- Image resolution is important for SSL: SimCLR performs the worst when images are degraded by downsampling (2x or 4x) (about 15% and 34%, respectively). This performance degradation is significantly larger than for supervised learning, indicating that SimCLR's feature representation is flawed.
- SSL is relatively robust against high-frequency noise: JPEG and Salt&Pepper add high-frequency noise to the image, but these effects are kept small compared to downsampling. This may be because texture information, which is important for CNNs, is corrupted by downsampling.
task granularity
Finally, we investigate whether there are downstream tasks for which the self-supervised learning representation is particularly suitable or unsuitable. The paper addresses this question by concluding that classification performance depends on the granularity of the task (label fineness/coarseness).
We now experiment with the label hierarchy available in ImageNet, iNat21, and Places365 to see how much performance depends on label granularity. We consider labels closer to the root of the label hierarchy to be rougher and labels farther from the root to be finer. The results are as follows. 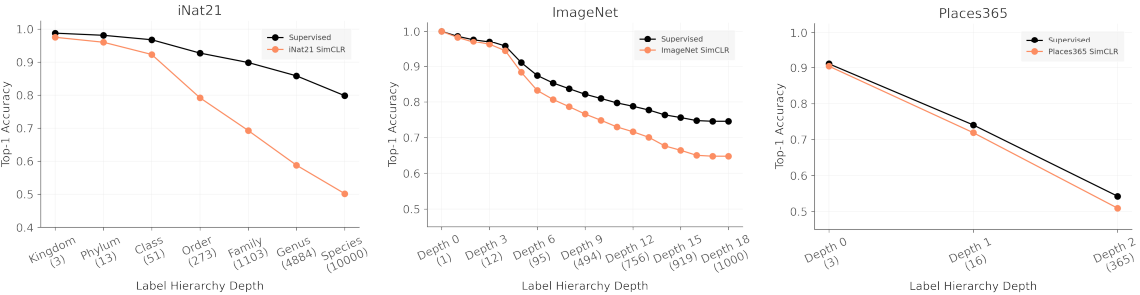
Findings from the results are as follows
- The performance difference between SSL and supervised learning increases as the task granularity gets finer: both SimCLR and supervised learning degrade in performance as the task granularity gets finer, but SimCLR degrades more rapidly. Also, SimCLR degrades most severely on iNat21, again suggesting that iNat21 is a challenging benchmark for SSL.
- Augmentation may be destructive: Since the control training methods are designed for ImageNet, the default augmentation methods may not be well tuned for other datasets, which may lead to performance degradation. For example, the "color jitter" in SimCLR may destroy important information if color is important for class classification. (However, this hypothesis does not fully explain our experimental results, as SSL performance also degrades with granularity in ImageNet.)
- Contrastive learning may have a coarse-grained bias: the paper assumes that contrastive learning loss tends to cluster images based on overall visual similarity. If this hypothesis is based, then the clusters that can be distinguished by contrast learning would be coarse-grained and would not be able to distinguish differences between fine-grained classes. Therefore, the effect of coarser clustering may be apparent when the task is fine-grained while this effect is overlooked when the classes are coarse-grained.
In general, further analysis is needed to understand the task granularity gap in SSL, and this is an area for future work.
summary
Comprehensive experiments on four large image datasets have been used to analyze important properties in self-supervised learning (SimCLR).
As a result, various important findings were revealed, including the amount of data required for pre-training, the relationship between data domain and performance, the effect of degradation such as image resolution on implementation, and the relationship between the fineness of task labels and model performance.
However, there are some limitations, such as the dataset size used in the experiments being on a similar scale to ImageNet, and the series of experiments being focused on SimCLR, so a more detailed investigation is needed in the future.





Categories related to this article






