Semantic Part Segmentation Is Now Possible With A Single Annotation!
3 main points
✔️ Semantic part segmentation is possible only by manually annotating 1~10 images
✔️ Use internal representation of GAN
✔️ Performance as good as 10-50x data despite fewer teacher data
Repurposing GANs for One-shot Semantic Part Segmentation
written by Nontawat Tritrong, Pitchaporn Rewatbowornwong, Supasorn Suwajanakorn
(Submitted on 7 Mar 2021 (v1), last revised 5 Jul 2021 (this version, v5))
Comments: CVPR 2021 (Oral)
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
first of all
Some prior work has tried to analyze GANs by making their internal information more interpretable; some work has tried to control the generated images by allowing users to play with the latent code of the GANs, and some work has tried to analyze GANs by making their internal information more interpretable. In this paper, we use the assumption that the internal representation of a GAN is closely related to the generated image and can retain semantic information.
Unlike semantic segmentation, which is the segmentation of objects in an image, the semantic part segmentation in this paper is aimed at segmenting parts within objects. This makes semantic part segmentation a more challenging task as there may be no visible boundary between two parts like eyes, nose, and face. This technique requires a huge amount of pixel-wise annotations and although existing methods have made considerable progress, they cannot control the segmentation of the parts of an object, resulting in arbitrary segmentation. In this paper, we can control these tasks by simply preparing a small number of annotated images.
In addition, although Few-Shot Semantic Segmentation has been tackled in meta-learning, it is not possible to learn a part-specific representation because it requires annotation masks of similar object classes. On the other hand, representations extracted from GANs can be trained unsupervised because they contain part-level information.
technique
We establish the conditions that we will introduce in this paper. First, given an unlabeled image and a few images (1~10) with part annotations, we aim to perform part segmentation on the unlabeled image. It is also assumed that these few part-annotated images can be manually set by the user. This task can be accomplished by providing a function $f$ that performs its part segmentation of information that would not be meaningful from the part-annotated images alone. The authors derive this function using a GAN that has been trained to produce images of the target object. In this article, we will now show how GANs can be used for this task, how trained GANs can be used for segmentation and extensions that allow segmentation without the need for GANs or advanced mapping during inference.
First, an introduction to how we extract representations from GANs: using GANs as a mapping function is not a simple problem, because GANs do not take as input the image pixels to be mapped, but rather a random latent code that is fed to the generator to produce an image. Using GANs as a mapping function is not a simple problem, because GANs generate images by feeding a random latent code as input to the generator, rather than the image pixels to be mapped. Therefore, we consider a situation where a latent code is fed to a convolution-based GAN (DCGAN) to generate an image. Each output pixel can be viewed as the result of a computation that can be traced back through each convolutional layer to the first input latent code. The computational hair color that generates a pixel is typically a Directed acyclic graph (DAG), where each node represents a parameter involved in the pixel computation and the input latent code. However, in the method proposed in this paper, each node represents an activation value, and the path is simply represented by a sequence of activations from all layers in the generator corresponding to that pixel.
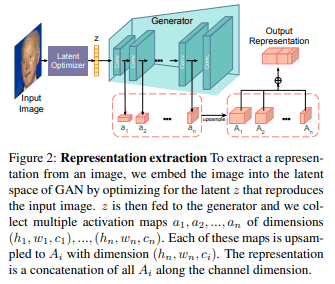
As shown in Fig. 2, we extract activation maps from all layers of the generator (each with $h_i,w_i,c_i$ dimensions) and denote them as $a_1,a_2,. .a_n$. Then we learn the pixel-wise representation as follows:
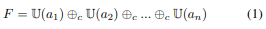
Here, $U()$ upsamples the input to the largest activation map $(h_n,w_n)$ and concatenates it along the channel dimension by $⊕c$. Normally, this feature map extraction process is only valid for images generated by the generator and cannot be used directly on test images. However, given an arbitrary test image, a feature map can be generated similarly by optimizing the latent code that generates the given image.
Generate $k$ random images from the trained GAN to achieve segmentation in Few-shot. We then create feature maps for these $k$ images and manually annotate them. These $k$ feature maps and annotations are used in pairs as supervised data to train the segmentation model (fig3).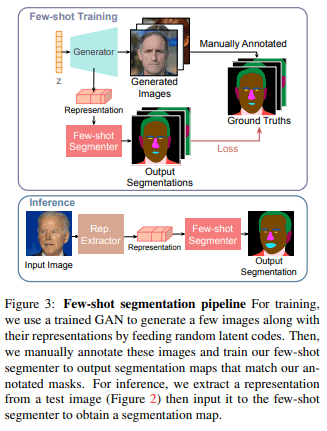
The segmentation of the test image is done by the latent code optimization described above to compute a pixel-wise feature map, which is then fed into the trained segmentation network.
One important point to note when performing this task using only GAN is that the test image must be close to the image distribution used for GAN. Otherwise, the optimization of the latent code will not be successful. If the object is a human face, the test image must have a similar distribution to the image used to train the GAN and must contain only one face. In addition, the optimization process of the latent code is computationally expensive and time-consuming because it requires multiple forward and backpropagation operations.
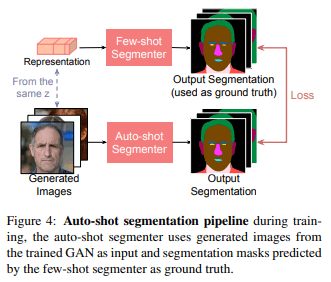
To solve the above problem, this paper creates a new pair of training data by using the trained GAN and the network of the proposed method and trains another network such as Unet. In this way, the segmentation is done by passing a single model without relying on GANs or feature maps. This process is called auto-shot segmentation in the paper. fig4 shows the flow of auto-shot segmentation.
Finally, we summarize the process flow in the proposed method once again.
- Train a GAN on the target object dataset
- Generating pixel-wise representation information of an image using a learned GAN
- Manually annotate the image generated by 2
- Perform Few-Shot Segmentation with Representation Information as Input
- Create a new dataset and predict a new segmentation map in 4
experiment
Experiment setup
In our paper, we use StyleGAN2 as a trained GAN. The few-shot network is a convolutional network (CNN) and a multilayer perceptron (MLP). In both CNN and MLP, Adam is used as the optimizer, and cross-entropy is used as the loss function. As mentioned earlier, UNet is used for the auto-shot segmentation network, and the training data for UNet is a pair of GAN-generated images and the segmented images of the few-shot network. In this process, the following data enhancements are made to the dataset:
- Random inversion
- 0.5~2 times random scaling
- -10~10 degrees random rotation
- The random movement of 0%~50% of image size
The data sets and evaluation metrics used in this paper are shown below:
- data set
- Human face (CelebAMask-HQ)
- Car (PASCAL-Part)
- Horse (PASCAL-Part)
- valuation index
- intersect-over-union(IOU)
- The ratio of the number of pixels belonging to that class to the total number of pixels
experiment
Human Face Part Segmentation
In the human face part segmentation experiment, we compare the architecture (CNN or MLP), the number of part classes (3 or 10), and how many annotations are done manually (1, 5, or 10) during the Few-Shot segmentation.
First, a comparison between CNNs and MLPs: unlike CNNs, MLPs are expected to be less accurate than CNNs because they infer each pixel independently. MLP performs almost as well as CNNs However, Table 1 shows that MLP has
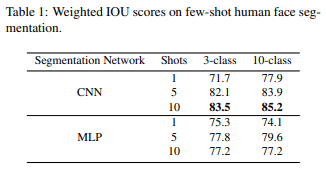
Table 2 shows a comparison between 10-shot segmentation and auto-shot segmentation. auto-shot segmentation only relies on the dataset generated by 10-shot segmentation Although auto-shot segmentation relies only on the dataset generated by 10-shot segmentation, it achieves the same IOU scores as 10-shot segmentation for all classes except clothes. The reason for the lower score for clothes is that the model is not able to cope with a large number of different types of clothes (colors and shapes).

Next, Fig5 and Tab3 show the generated images and IOUs of few-shot segmentation employing CNN. We can see that 10-shot has the best performance in both cases.

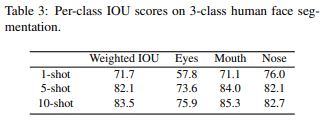
Fig. 6 shows the comparison between the results of supervised learning using the same architecture as the proposed method and CelebAMask-HQ dataset with the different number of labels and the results of the proposed method, few-shot segmentation. The graph shows that more than 100 annotations are required to surpass 1-shot segmentation, and about 500 annotations are required to achieve the same level of performance as 10-shot segmentation.
Car Part Segmentation
The part segmentation of a car is expected to be a more difficult task than that of a face image because of the wide variety of poses and appearances. However, as shown in Fig. 7, the proposed method can identify tires, windows, and license plates in one-shot images.

Table 4 compares the auto-shot trained by the proposed 10-shot method with DeepCNN-DenseCRF and Ordinal Multitask Part Segmentation. The performance is better than that of the baseline, which is fully supervised learning.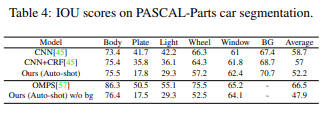
Horse Part Segmentation
Segmentation of horses is expected to be an even more difficult task than the previous two. The reason may be that horses have various poses such as standing and jumping, and the boundary between legs and torso is not clear. As expected, the performance of the proposed one-shot method is inferior to that of human faces and cars, but as shown in Fig. 8, a significant improvement can be achieved by increasing the number of annotations.

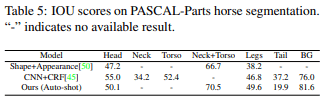
Table 5 compares auto-shot trained on 10-shot with Shape+Appearance and CNN+CRF. Table 6 shows the results of RefineNet and Pose-Guided Knowledge Table 6 shows the results of RefineNet and Pose-Guided Knowledge Transfer. The proposed method outperforms RefineNet but is slightly lower than Pose-Guided Knowledge Transfer with fully supervised learning over 300 shots.

summary
In this paper, we proposed an approach to use GANs, which are used for image generation, for few-shot semantic part segmentation. The novelty lies in the use of pixel-by-pixel representation information obtained from the GAN generation process. The proposed method enables part segmentation with very few annotations and achieves the same performance as fully supervised methods that require 10~50 times more labels. In addition, we can handle images with different sizes and orientations by creating a new dataset of segmented images generated by few-shot. This paper suggests that unsupervised representation learning, GAN, can be an effective and general-purpose distillation task for semantic and pixel-by-pixel prediction of object parts in the future.



Categories related to this article






