BroadFace: A New Way To Train Tens Of Thousands Of Face Instances At Once, Overcoming The Limitations Of Mini-Batch Learning
3 main points
✔️ Past embedding vectors were stored as queues, allowing the data to be used more comprehensively for training and improving discrimination capabilities.
✔️ It can be easily applied to existing face recognition and does not require additional memory load during inference.
✔️ Extensive experimentation using nine datasets resulted in a significant improvement in accuracy compared to traditional methods.
BroadFace: Looking at Tens of Thousands of People at Once for Face Recognition
written by Yonghyun Kim, Wonpyo Park, Jongju Shin
(Submitted on 15 Aug 2020)
Comments: Accepted at ECCV2020
Subjects: Computer Vision and Pattern Recognition (cs.CV)
Overview
Facial recognition is used for a variety of applications, including electronic payments, smartphone screen locks, and person detection for surveillance cameras. Research on facial recognition has been done for decades, but the adoption of Convolutional Neural Networks (CNNs) in the last few years has dramatically improved recognition accuracy. However, many challenges still remain.
Since the performance of facial recognition models is evaluated using a dataset containing first-time IDs, most research has been focused on improving the discriminative capabilities of the embedded space. A recent mainstream effort has been the introduction of objective functions that maximize inter-class discrimination and intra-class compactness.
However, due to memory limitations, previous studies have applied small mini-batches that utilize only a portion of the data set. Therefore, we use a large number of data at a time to comprehensively reflect the ID of the dataset, and learning the best decision boundary in the embedded space is becoming more and more difficult. Learning tens of thousands of IDs in mini-batches of small size requires huge iterations. One could simply increase the size of the mini-batch, but this would be impractical due to the large memory load. In addition, past research has shown that it does not necessarily improve accuracy.
Therefore, In this paper, a new learning method called BroadFace, which comprehensively learns the vast identity of a dataset was proposed. The central vector of the identification information, which is the weight vector of the classifier, can be estimated in as many as tens of thousands of instances. Due to a large number of instances reflected, the central vector can be estimated with higher accuracy. BroadFace is a new learning method that overcomes the limitations of mini-batch learning and can be easily applied to traditional face recognition methods.
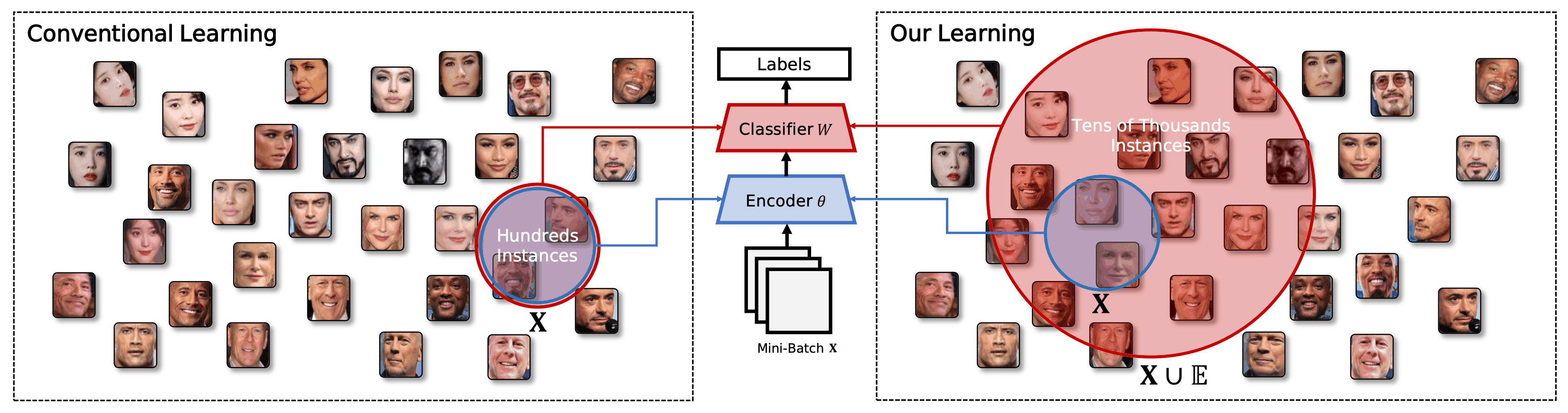
BroadFace maintains the embedding vectors from past iterations as queues and uses the embedding vectors from both the mini-batch and queue of each iteration to optimize the classifier's decision boundaries. Since the parameters of the model are iteratively updated, subsequent iterations cause errors with the queue embedding vectors. Therefore, it also introduces corrections to reduce errors between embedding vectors by accounting for differences in identity-representative vectors from past iterations.
To read more,
Please register with AI-SCHOLAR.
OR


Categories related to this article


![[Swin Transformer] T](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



