Real-time Facial Expression Recognition Realized By Compressed Video-based System!
3 main points
✔️ They propose a way to recognize facial expressions directly from compressed videos
✔️ Compressed videos contain Facial expression muscle movements are embedded as differential data, so we can build a robust model utilizing the intrinsic features of facial expressions
✔️ Reduce computational cost and speed up processing by utilizing differential data
Identity-aware Facial Expression Recognition in Compressed Video
written by Xiaofeng Liu, Linghao Jin, Xu Han, Jun Lu, Jane You, Lingsheng Kong
(Submitted on 1 Jan 2021 (v1), last revised 7 Jan 2021 (this version, v2))
Comments: Accepted at ICPR 2020
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Multimedia (cs.MM)


Abstract
Sending and receiving video data over the Internet such as Netflix, YouTube and TikTok has become commonplace, and this trend is expected to intensify as 5G becomes more widespread. Because of the large data size of this video data, it is generally handled in a compressed format. By eliminating useless data to the extent that it can be recovered, and by reducing the data to only the minimum necessary, the video can be handled efficiently. This also has a great impact on facial expression recognition, which is the theme of this article.
Scenes in which facial expression recognition is used include work efficiency improvement by automatically extracting highlight scenes from captured videos, searching for marketing materials, and Observation of patients in the medical field, and or robots that change their behavior according to human emotions. Various These are just a few examples. All of these require the processing of a large amount of video data. In particular, robots that change their motions in response to human emotions require real-time reactions, so it is necessary to process the data as efficiently as possible.
Most of the previous methods processed RGB images of decoded compressed video sequences, but IFERCV, which this paper introduces, recognizes facial expressions directly from compressed video data. As a result, it achieves three times faster processing speed with the same level of accuracy as conventional methods.
IFERCV, a Facial Expression Recognition Model Using Compressed Data
As mentioned earlier. For facial expression recognition of video, the conventional method decodes the image into RGB image once, as shown in the figure below (yellow). On the other hand, IFERCV recognizes facial expressions without decoding the compressed video. Therefore, compared to the conventional method, IFERCV eliminates the decoding process and performs facial expression recognition using compressed data with less data volume, which dramatically increases the processing speed.
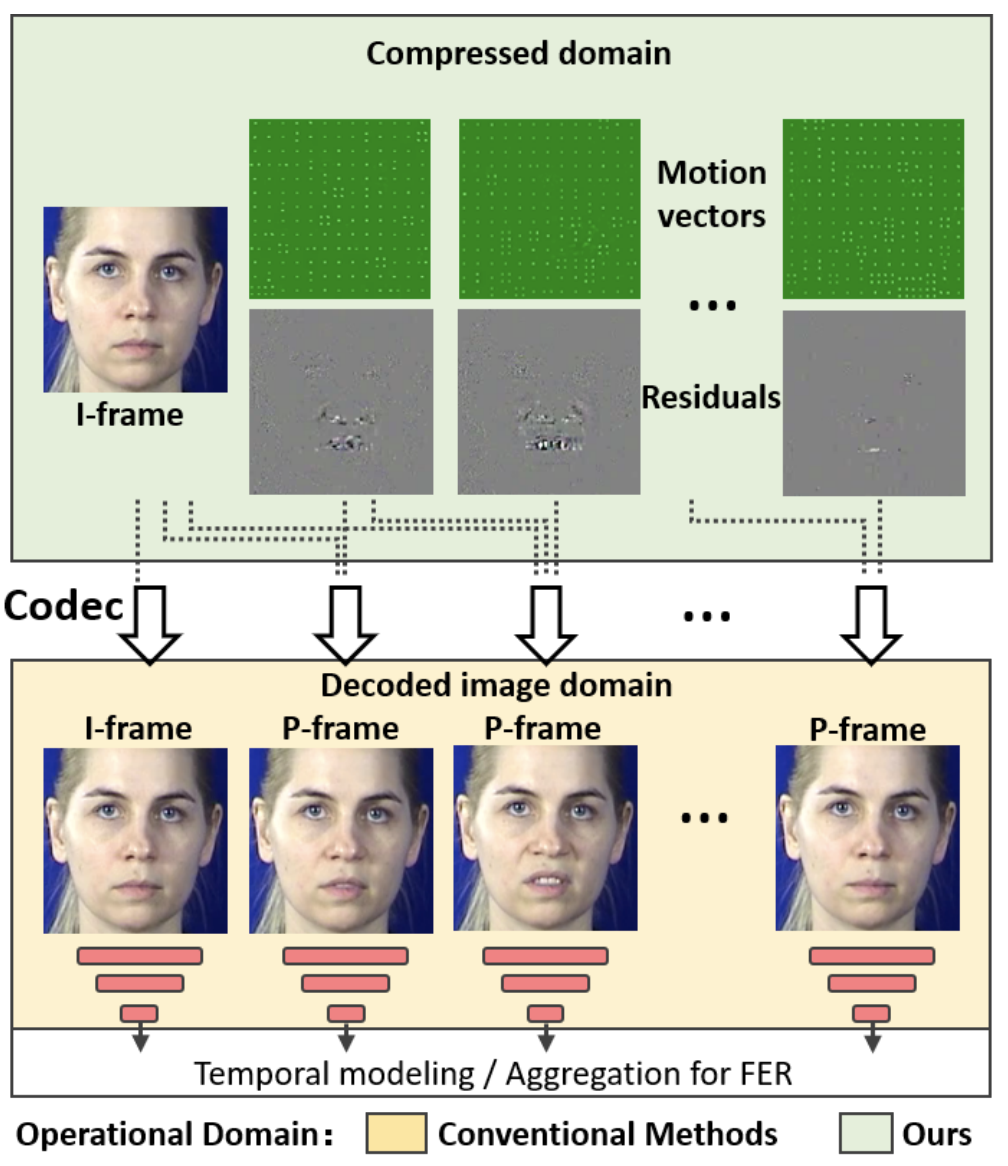
A video generally consists of I-frames and P-frames. An I-frame (Intra-coded Frame), also called a key frame, is a key frame where no prediction is made between frames. Also. P-frame (Predicted Frame) is a frame that takes into account the differences (Residuals) between the image and the predicted image from the previous frame in time. At this time, Motion Vectors, which are the correction information for the motion of objects in the frame, are also embedded.
In compressed video, the original frame information is not retained, but the reference I-frame and Differences (Residuals) and and Motion Vectors (Motion Vectors). and Motion Vectors. In this paper, they focus on this differences (Residuals) In this paper, we directly recognize facial expressions from these differences (Residuals). The outline is as follows.
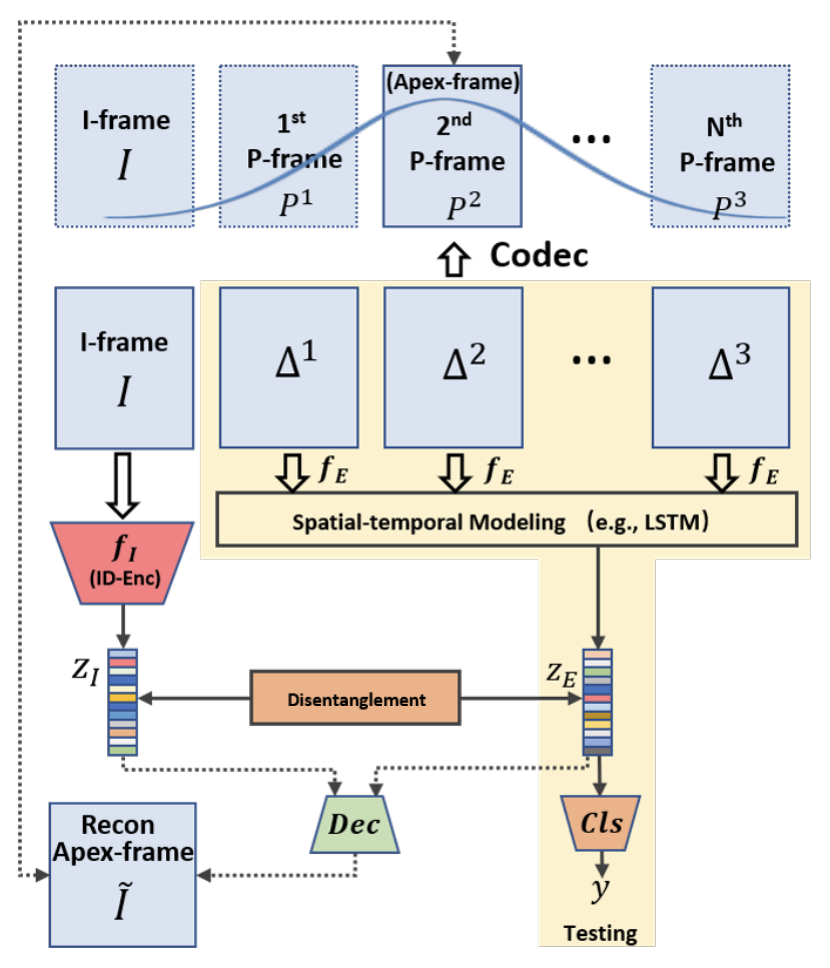
The I-frame and P-frame are respectivelyI and P respectively, and the difference and motion vector are ΔT and T are represented by P and I represent the time elapsed since the I represent the time elapsed since the frame. In this method, in order to facilitate the learning of facial expression changes, we choose a frame of a reference true face as the I-frame and use the learned FaceNet (fI ) is used to extract the features of a real face (ZI ) are extracted using the learned FaceNet ( ).
Next, in order to extract features related to facial expression changes Δt we use a typical CNN-LSTM for A series ofΔt For the CNN (fE ), and then apply the By LSTMfE by LSTM, then the features extracted from fE are aggregated into one, and finally feature set of facial expression change.ZE is extracted. Since the difference data, Δ, is much less informative than a typical frame, we can use a simpler and faster CNN than the one used in conventional facial expression recognition. As a result, the computational load becomes much smaller.
Furthermore, they also use Disentanglment Learning to extract more essential facial feature information and build robust models by clearly separating ZI and ZE into two categories, "real face" and "face with expression". Specifically, we decode the I-frames corresponding to the Apex-frames from ZI and ZE, which are the frames with the most pronounced expression changes. We separate ZI and ZE into two types: "real faces" and "faces with expressions".
Since most datasets for facial expression recognition (CK+, MMI, etc.) are designed to show the change from a true face to an expressive face, we can choose between a true face and the face with the most expression change (Apex-frame).
Experimental results
Here we compare the model and performance of SOTA using two datasets, CK+ and AFEW. CK+ (Extended Cohn-Kanade) is a widely used benchmark for facial expression recognition tasks. The subject is photographed facing the camera with a blank background. In other words, it is a dataset of videos shot in a somewhat prepared environment. Each video consists of 593 image sequences that change from expressionless to expressive, with the last being the frame with the largest change in expression. There are six labels for facial expressions: Anger, Disgust, Fear, Happiness, Sadness, and Surprise. The number of subjects is 123.
AFEW (Acted Facial Expressions in the Wild) consists of video clips from the film. Therefore, unlike CK+, it is a dataset of videos that were shot in a more realistic environment without any shooting conditions. As in CK+, there are six labels for facial expressions: Anger, Disgust, Fear, Happiness, Sadness, and Surprise. The subject is unknown, but the number of videos is 1,809.
Experimental results of CK+
First of all, the results of performance comparison with conventional models by CK+ are shown in the table below. In order to compare each model fairly, image-based and ensemble models are not included here.
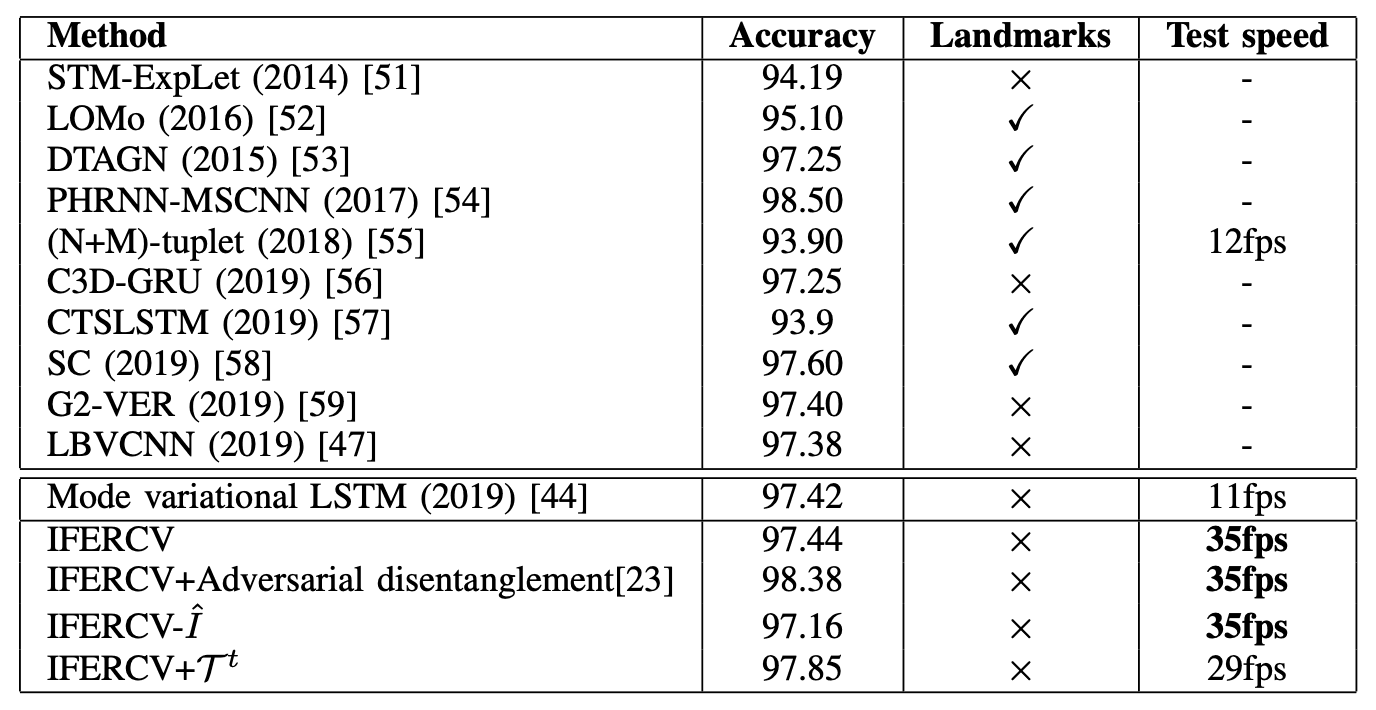
Many models that have achieved high performance (e.g., LOMo, DTAGN, PHRNN-MSCNN, CTSLSTM, SC) use face landmark information. They rely heavily on a highly accurate Face Landmark detection model. This Face L andmark itself is a difficult task and computationally expensive.
On the other hand, our proposed IFERCV is based on Mode variational LSTM and achieves SOTA accuracy without using complementary information such as Face Landmark, 3D Face Model, and Optical Flow. Also. IFERCV, which is a compression-based process, can IFERCV, which is based on compression, does not need to decode the video, so it is about three times faster than the base Mode variational LSTM and achieves higher accuracy.
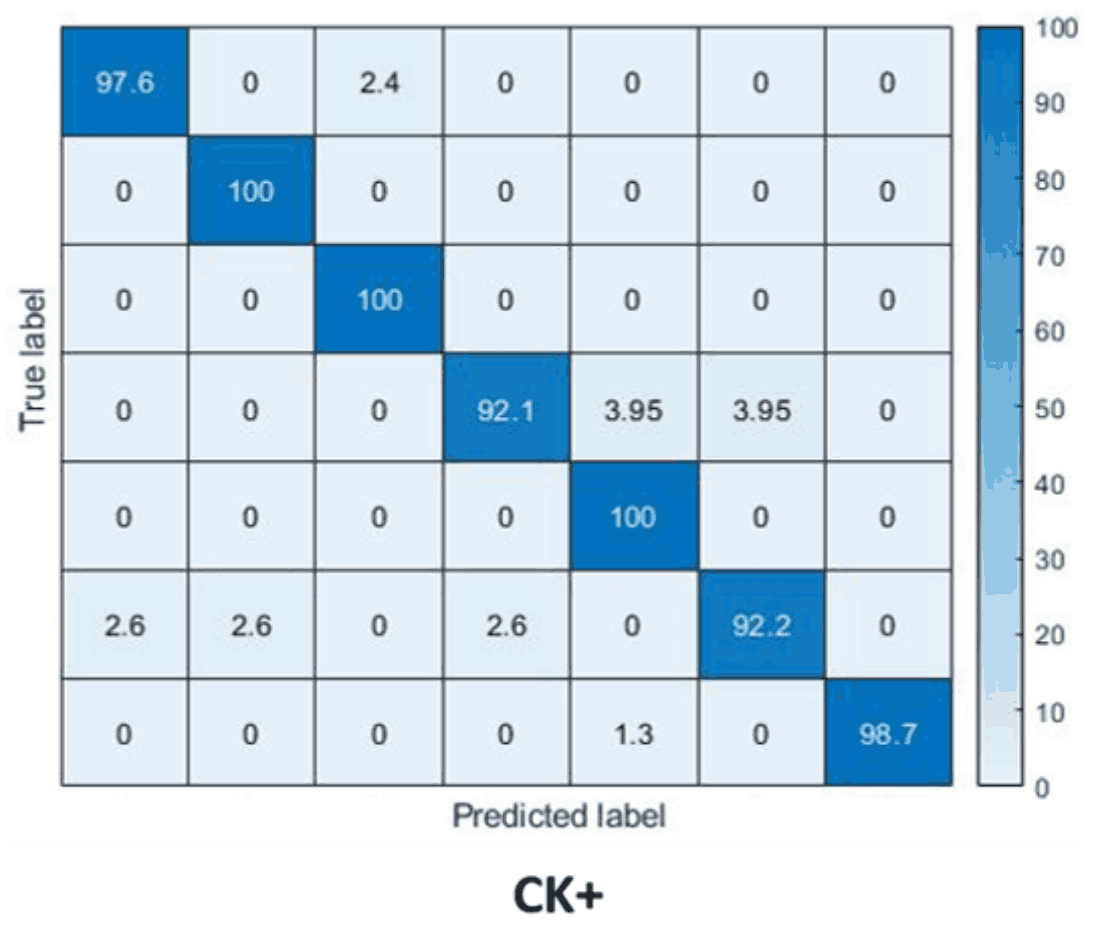
The Confusion Matrix looks like this Each row and column represents, from top/left, Anger, Disgust, Fear, Happiness, Neutral, Sadness, and Surprise, and it can be seen that high accuracy is achieved in all cases.
Experimental results of AFEW
Next, the results of the performance comparison with conventional models by AFEW are shown in the table below. Again, in order to compare each model fairly, the ensemble models are not included. (The table is from the paper but the names of the items for Model type and Accuracy seem to be reversed).
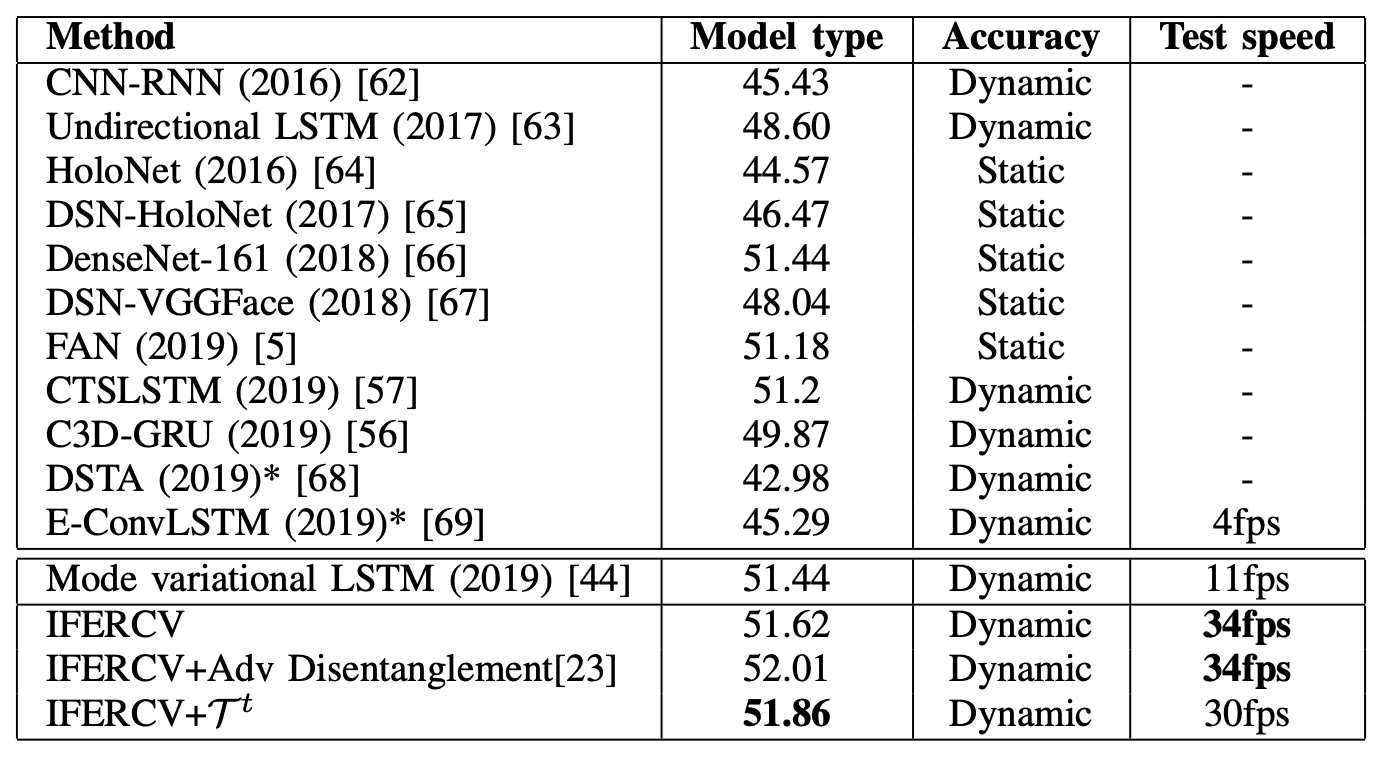
AFEW is not as well filmed as CK+, so Accuracy is lower overall. Also, no audio data is used here. IFERCV achieves comparable or better recognition performance than the SOTA method on a compressed basis. It also achieves 3 times faster processing speed compared to Mode variation LSTM used as a base here.
Although the recognition accuracy is not sufficient, the compression-based processing shows the possibility of recognizing facial expressions at near real-time speed even in a realistic shooting environment.
Conventional models need to decode the video and also need complex data processing such as using complementary information. On the other hand, the proposed IFERCV can eliminate these processes. We also see that it significantly improves the Test speed and achieves the same accuracy as the previous model. In this work, they have focused only on image compression for validation, but there is a possibility to improve the accuracy further by trying multimodal using audio data.
Summary
In this paper, we propose a method for facial expression recognition directly from compressed video data. It is based on the idea that the movements of facial muscles are well encoded as differential data in the compressed image data, which provides the essential features of facial expressions and allows us to build a robust model. By utilizing the difference data, we can also expect to eliminate redundant data such as the background, which hardly changes in the video, and learn with less computational cost.
In IFERCV, we also apply Disentanglment to the features extracted from the I-frame and difference data to separate the face identification information from the expression information and extract the essential expression information.
By applying these methods, IFERCV is compared with a typical video-based FER benchmark, and the accuracy of SOTA is achieved without applying any complementary information. Moreover Moreover, the processing speed is also significantly improved, showing promising results for real-time FER.



Categories related to this article


![[Swin Transformer] T](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



