AI And Its Infinite Ways Of Application -The World Line Made Possible By AI-
Usually I am writing on more technical topics, but this time I want to focus on the explanatory side of AI.
I believe many of you are familiar with pose estimation, or may have heard of it. Simply put, it is a technology that determines the pose of a person. OpenPose, which was presented at the CVPR2017, is the most famous pose estimation technology example that you might have heard of. In this article, I'd like to go into depth about pose estimation.
How is the social need for pose estimation expanding?
The reason why I am writing this article is because in recent years, video social networking sites have exploded in popularity, and as a result, video research has increased. So video data is becoming more and more common. In addition to SNS, security cameras have become a common tool in terms of crime prevention and control measures. In this context, pose estimation has become an important tool for analyzing customer behavior, grasping the condition of patients in nursing care, or monitoring suspicious behavior.
About 10 years ago, pose estimation had a classic tree model, and was said to be difficult to use for business because of its many issues in terms of accuracy and utilization. However, with the emergence of Deep Learning, these issues have been solved, and Deep Learning is now playing a central role in the development of business. So I would like to take a deeper look at the growing business of pose estimation in the following.
Source: a 2019 guide to Human Pose Estimation with Deep Learning
What are the possible applications of pose estimation?
Security staff cannot actively keep an eye on surveillance camera images 24/7 – It is necessary to automate this process. But why pose estimation, you think? Well first of all, videos contain a lot of data. When you are taking videos or pictures of people, body posture is always included. And posture gives important information for whatever a person does or is about to do.
For example: In sports, you could analyze the movement of athletes and use this data to prevent injuries and create coaching practice schedules.
In control and security, you could monitor people who make certain movements. Conventional technology is able to tell you every time when someone is approaching a restricted area, but that would only increase the cost of management by tracking all people who happen to approach. With pose estimation unnecessary tracking can be prevented by detecting the "behavior" of people who intentionally try to enter the restricted area.
By analyzing people's behavior, we can create more value. And that means adding value to your services and differentiating yourself from the competition.
About Pose estimation
Let's take a look at the technical aspects of pose estimation. First of all, there are two types of pose estimation: regression and heatmap detection.
The regression method
With this method, skeletal joint positions are directly predicted as coordinates from the image of a person. In this case, joint positions need to be predicted pixel by pixel, and it is difficult to make exact specifications of the positions.
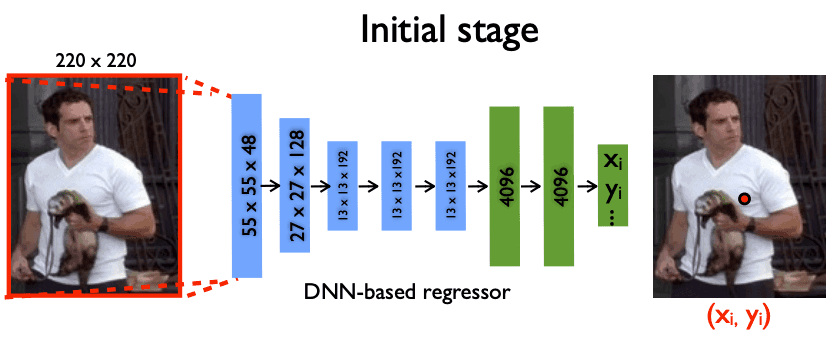
Source: DeepPose: Human Pose Estimation via Deep Neural Networks
The heat map method
Here, the probability of the joint’s positions are calculated in units of one pixel, which allows for misalignment within a certain range. This method is more tolerant of small deviations than the regression method, and thus is currently the most common method for pose estimation models. Most of the models that people are familiar with are based on this method.
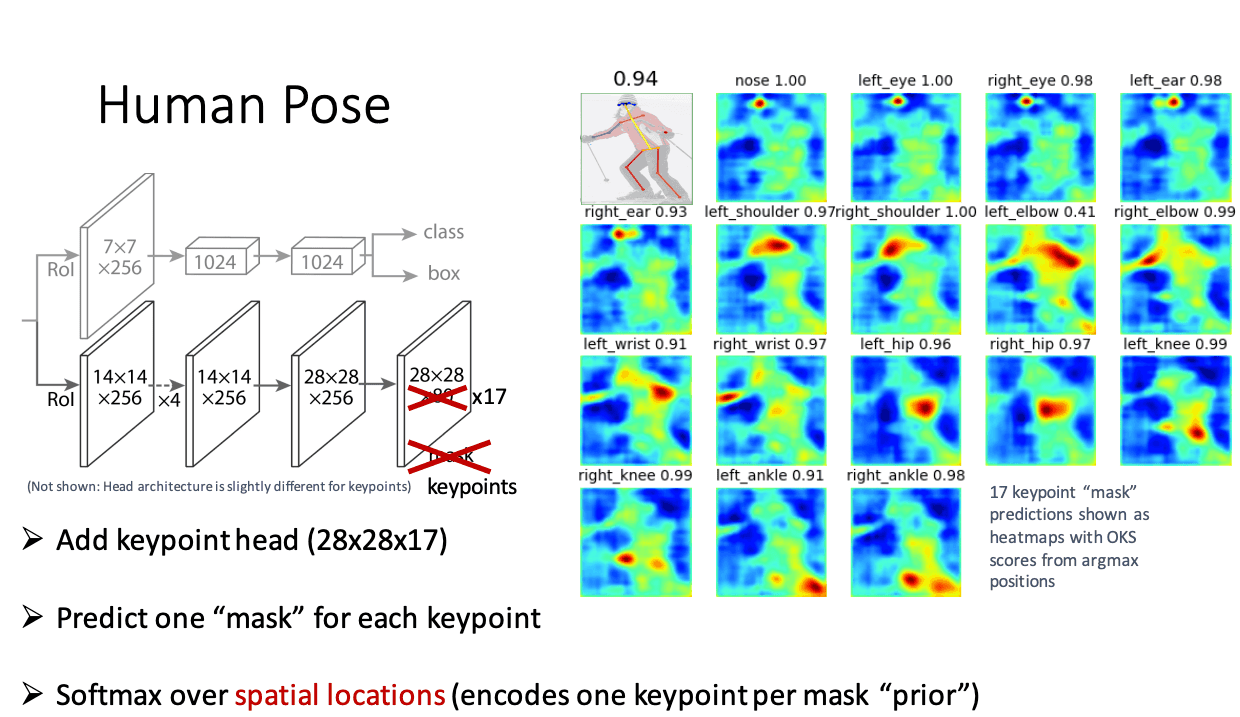
Source: Deep Learning for Instance-level Object Understanding
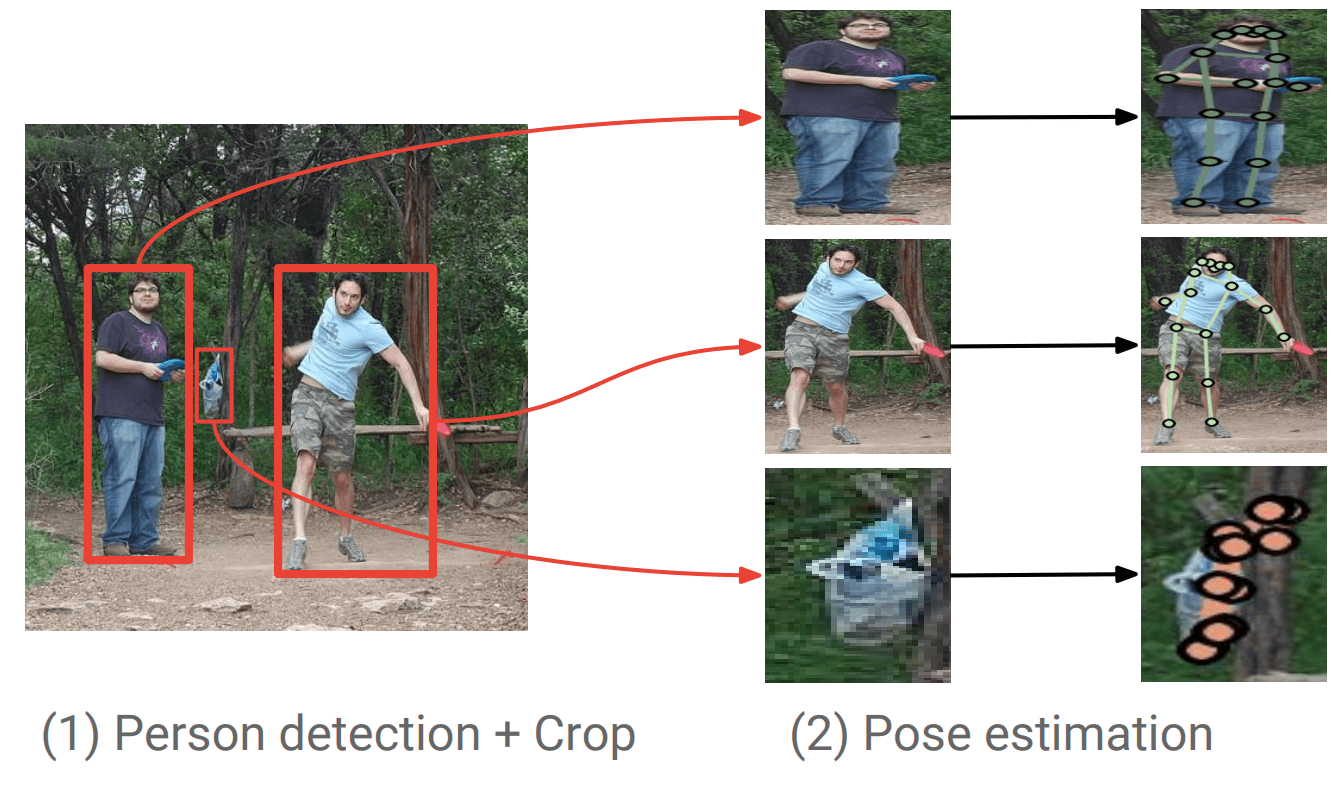
Furthermore, pose estimation is divided into two types, top-down and bottom-up, according to its properties.
Top-Down
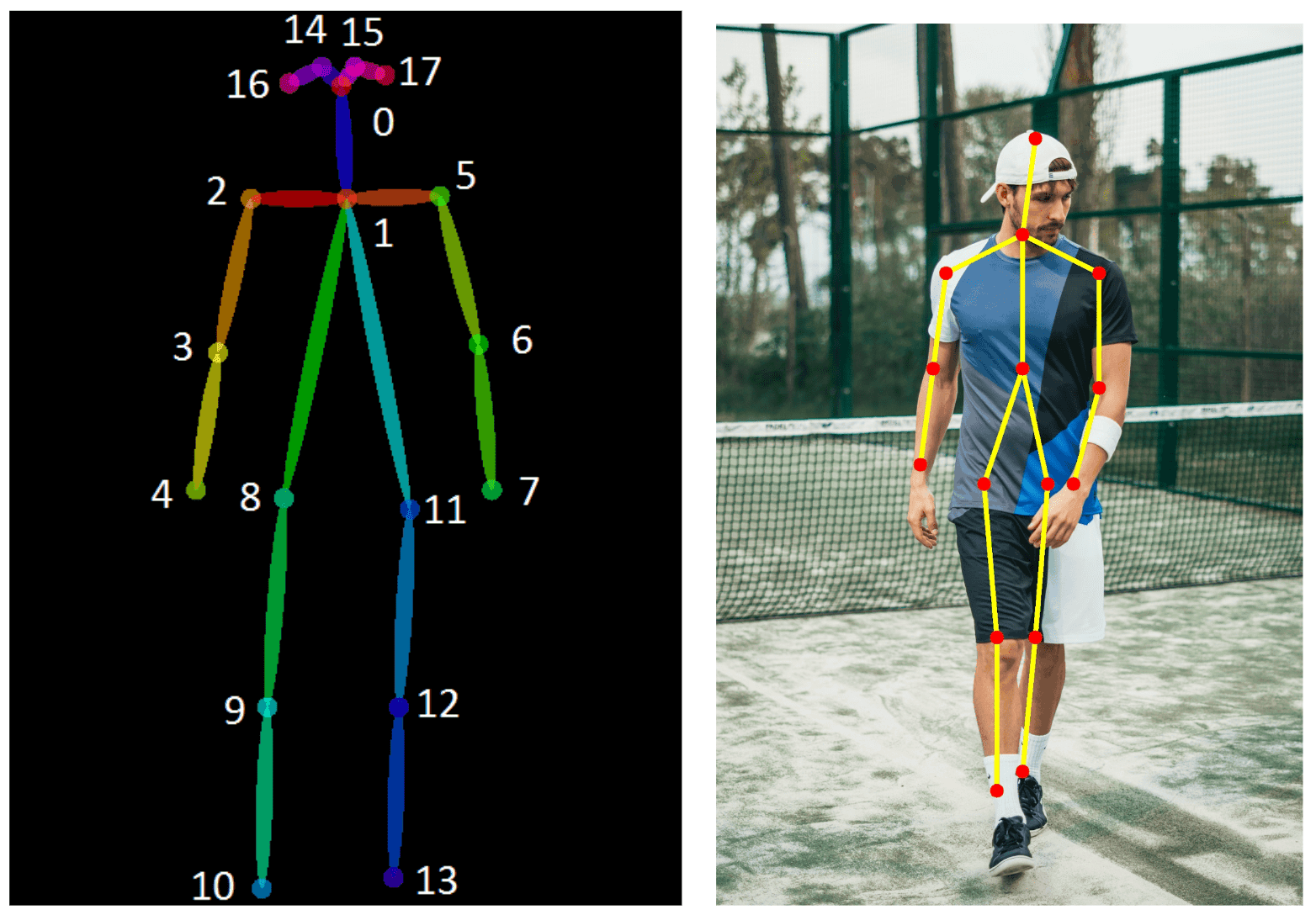
Here, a person is detected first, and then skeletal coordinates for the detected person are predicted.
- Object detection is performed to identify a person.
- The skeletal point coordinates are predicted for the detected person.
Source: Towards Accurate Multi-person Pose Estimation in the Wild
Bottom-Up
First, the skeletal points are detected all at once, and then the detected skeletal points are grouped to form the entire person.
- Detect only the key point coordinates of joints from the image (the object itself is not distinguished)
- Grouping the detected key points to a person by optimizing them based on distance

Source: DeepCut: Joint Subset Partition and Labeling for Multi-Person Pose Estimation
To sum up the above:
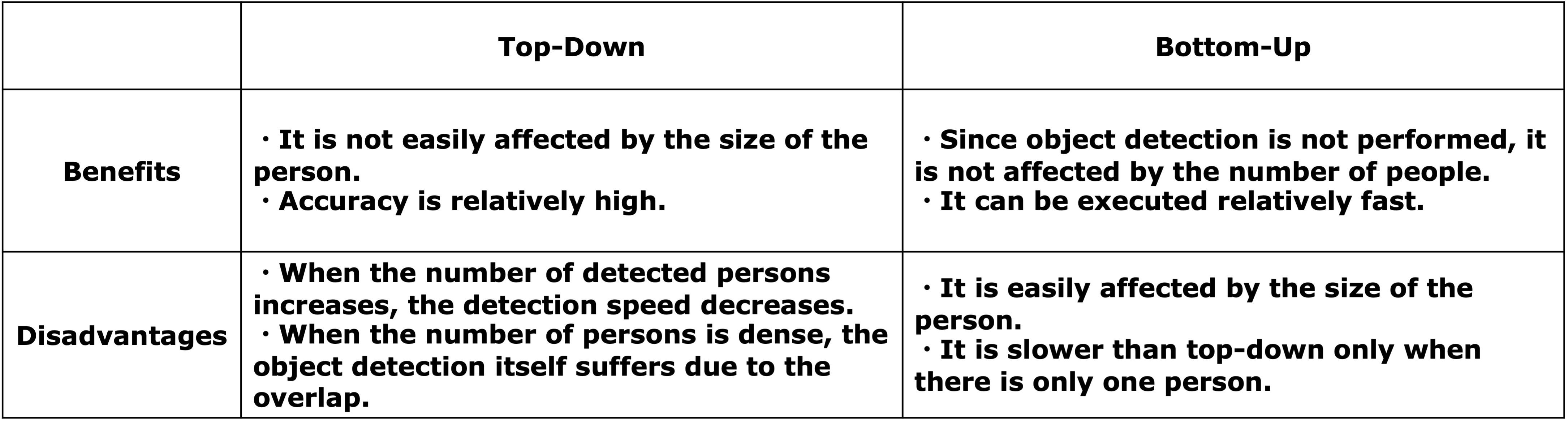
Commonly used technologies today
In the following you will find a list of the main pose estimation systems commonly used around the world today:
Top-Down Approach
- DeepPose
- Mask R-CNN
- SimpleBaseline
- HRNeT
Bottom-Up Approach
- OpenPose
- PoseNet
- Associative Embedding
- HigherHRNeT
Expert Interview
We have asked Mr. Hiroyuki Naka and Mr. Kenji Koyanagi, both experts from the System Development Department of NEXT-SYSTEM Co., Ltd. for a few insights on the pose estimation system they have developed in-house, as well as for a future outlook on pose estimation technology.


Left: System Development Department, Sub-Manager, Mr. Kenji Koyanagi
Right: System Development Department, Expert, Mr. Hiroyuki Naka
What is VisionPose?
VisionPose is our in-house developed AI pose estimation engine that analyzes human skeletons and pose information in 2D/3D without markers. In addition to camera images, detection from still images and videos is also possible. We provide VisionPose as an SDK that can be used for a variety of development purposes, and as an integrated equipment package that can be used for research purposes. Currently, a total of more than 300 units of the series have been sold, mainly by major companies in Japan (as of November 2021). VisionPose WEB-site
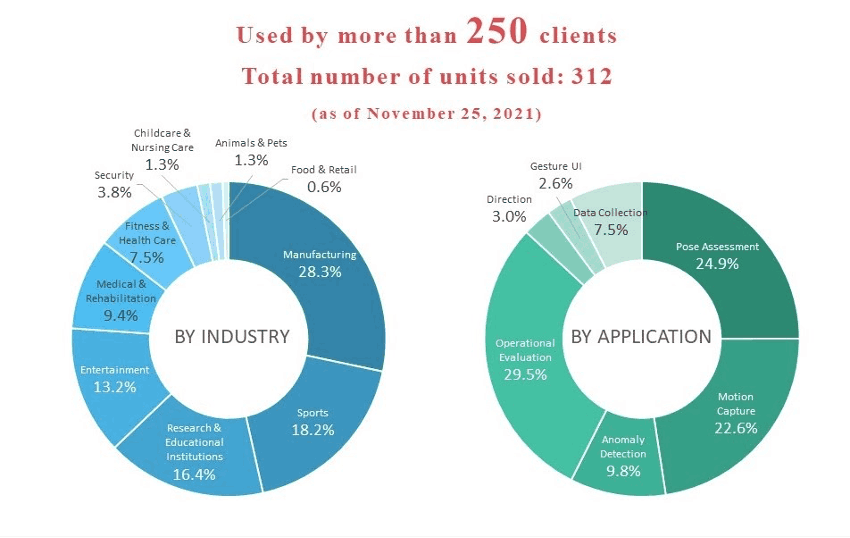
- This graph shows that there is already a wide range of industries using VisionPose, and that there are several ways to apply the AI engine. This information is in line with the expanding social needs for pose estimation I mentioned earlier.
Why did you decide to develop VisionPose?
The initial trigger for the development of VisionPose was the sudden discontinuation of the Kinect V2 motion sensor camera in October 2017. We had used Kinect in our AR signage system Kinesys, which was our main product at the time. Since we couldn’t find a comparable camera to replace Kinect, our company was forced to face a difficult business situation.
Here is a picture of all the Kinect V2 cameras we bought up in panic after the discontinuation was announced:

- The picture itself is funny, but the situation definitely isn’t...so this was the moment when pose estimation came into play for NEXT-SYSTEM.
Because of this situation, we decided to develop a pose estimation system that can detect human motion in real-time by only using normal web cameras without any motion sensors. This was possible by applying image recognition AI technology, which is a field we had accumulated know-how through contract development. Thus VisionPose was born.
In December 2017, we released a simple demo of it on SNS, and it was very well-received, so we started development in earnest, and after about a year of work, we finally started selling VisionPose as a product in November 2018.
What are the features of VisionPose?
VisionPose is capable of detecting skeletal information of up to 30 key points in 2D/3D coordinates, and consists of an SDK and two ready-to-use applications: “BodyAndColor", which detects skeletal information in real-time from camera images, and "VP Analyzer", which detects skeletal information from videos and still images.
VisionPose Standard comes with our trained models that easily recognize common postures in daily life. In more specific fields such as dance and sports, the analysis accuracy can be improved by additional learning and additional detection points can be added as well (additional learning is an optional service).
Since pose estimation technology has a wide range of applications, VisionPose supports a wide range of OS and devices. It also supports edge devices that excel in real-time processing and can be operated in small spaces while reducing terminal costs, making it easy to use on manufacturing sites. VisionPose can be used commercially as well.
- The maximum detection of 30 keypoints is a lot more than what is typically offered from other pose estimation technologies. Also, additional learning seems quite important to answer customers' requirements depending on the application.
When using pose estimation technology from overseas, it is mostly open-source or paper-based, except for attached solutions such as iOS. Integrating pose estimation into your service might be quite difficult since a lot of questions and issues might pop up, but our company can provide additional implementation support, which I believe is a very special feature.
- That's true, some people might help out a lot, but generally there is no fixed support system. And the fact that this is all done by edge computing is amazing.
Because it is a Bottom-Up AI, VisionPose does not analyze each person in the image one by one, but first detects the key points in the entire image without differentiating between people, and in the following groups them by person. So even if the number of detected people increases, the speed does not decrease, which is one of VisionPoses strengths.
Why did you choose Bottom-Up instead of Top-Down?
We chose this method so it would work in real-time, even when there are multiple people in the picture. I thought it might be difficult to use if the FPS drops because there are multiple people in the area scanned by the user. So I decided to use the bottom-up method, to ensure that the speed does not drop even with multiple people detected.
However, while it is an advantage that the speed does not decrease, there was the problem that key points might get mixed up inferring multiple people, depending on the accuracy of the grouping. So to improve the grouping accuracy, we used diverse multi-person data for additional learning.
It's a great advantage to be able to do additional learning in-house. Did you have any difficulties with this?
Yes, the first large dataset we used to develop VisionPose had 17 key points, but since our original goal was to create a replacement for Kinect V2, we increased the number of key points to 30 using in-house learning.
For this study, we took about 7,000 pictures of our employees in all kinds of poses and angles in front of a green screen, and then created tens of thousands of data by adding more patterns, such as synthesizing backgrounds. We also had to input each key point on all of these images by hand, which was a lot of work, but we were able to improve the accuracy immensely, and increased the number of key points to our goal of 30.


(Left) Shooting data for additional learning
(Right) Annotator to synch understanding of the keypoint positions on a skeleton
To make additional learning more efficient, we have developed our own teacher data creation tool, the "VP Annotation Tool", and we have set up a server environment so that multiple people can work on it simultaneously.
A video introduction of the VP ANNOTATION TOOL, a teacher data creation tool
We believe that there is still room for improvement in additional learning, and as an approach to making it easier to create teacher data, we are also aiming to reduce work costs by creating a tool that can produce teacher data by using 3DCG people in various poses and environments.
We had a lot of difficulties, but in the end it helped us to increase our know-how tremendously. For example, up until now we had only trained on human teacher data, but discovered an issue where we couldn't distinguish the human data from the background. So we did additional learning without any person in the picture, only with the background, and the accuracy improved.
What have been the most surprising application requests from customers, or the most interesting industries you have provided your technology for up until now?
I believe the most surprising inquiries were those asking whether VisionPose could be applied to animals, robots, and in other non-human cases.
In recent years, there has been a serious shortage of labor in the domestic livestock sector. The workforce is decreasing and aging, while the number of animals being raised is on the rise due to the increase of farms being supported by the Ministry of Agriculture, Forestry and Fisheries. In cases where it is not possible to devote sufficient time for monitoring due to a lack of manpower, it can lead to delays in disease detection and detection of the rutting season. Conventional wearable devices have been proven to improve production efficiency through projects such as those conducted by the Ministry of Agriculture, Forestry, and Fisheries, but they are expensive to install and place a heavy burden on livestock.
For this reason, our customer hoped to use markerless technology, in combination with an inexpensive and easily available camera. So we made VisionPose learn the posture of livestock, such as cows and horses, and succeeded in detecting the skeletons of multiple livestock in real-time from camera images. By determining the posture and behavior of livestock based on the acquired skeletal data, we can expect to support the breeding season by detecting diseases early as well as detecting riding behavior (behavior of cattle riding on top of each other, indicating estrus).
- There's finally a non-human example! This was not something that came up when I researched your company. So the strengths of VisionPose and additional learning, which are easy to use in edge computing, are adaptable to the needs of society.
Could you give us a few examples of where VisionPose has been applied to up to today?
As an example of additional learning, Avex Management Inc. used VisionPose for their smartphone application that evaluates dance technique through video analysis. VisionPose can detect up to 30 key points, but since the "heel" is important for evaluating dance, additional learning was done to increase the number of points to 32 in this case. We have also supported customers who wanted to add the tip of a racket or bat as a key point by additional learning.
Other uses include the field of sports, where VisionPose is used for form analysis in golf and baseball. It is quite difficult to analyze and improve the form by yourself, but VisionPose can help the player to analyze and improve their form by acquiring the skeletal information in detail and by evaluating it quantitatively. In addition, the Sports Science Laboratory, a general incorporated association, is using VisionPose to predict and avoid injuries of young baseball players by identifying the relationship between certain movements and pitching disorders.
Apart from sports VisionPose is also utilized in the medical rehabilitation field, for example in a robot to support rehabilitation of paralyzed lower limbs, produced by Toyota motor corporation. We can't tell you the details yet, but we are planning to implement it to major companies in the entertainment industry as well.
We also use VisionPose for in-house development, for example our full-body motion capture app "MICHICON-Plus", which allows the user to project their movements on a smartphone camera onto a 3DCG character in real-time. We also developed an AI workout counter app, "IETORE", which automatically counts the number of repetitive training movements such as squats, from the user's smartphone camera. Furthermore, our application “Kinesys” allows users to virtually try on clothes just by standing in front of digital signage.
What updates do you plan in the future?
In the future, we plan to focus on the development of new services based on VisionPose. Currently we are developing a behavior analysis tool using time series data. VisionPose is used to train time series data so that specific actions can be detected.
For example, if you look at a sleeping posture using only static data, it is difficult to determine whether the person is "sleeping" or "lying down" based on their posture alone. If you use time-series data, you can judge based on causal relationships, such as standing → sleeping = lying down.
Specifically, we will be able to obtain new information that was previously unavailable using only posture data, such as people who have fallen down, shoplifters, picked up products, and returned products. By using these technologies, we will be able to analyze behavior in a variety of settings, including retail stores, factory floors, medical facilities, and nursing and childcare facilities.
NEXT-SYSTEM has also opened a global EC site for their AI pose estimation engine VisionPose, as of November of 2021, and we hope that we will be able to accumulate a lot of know-how by having a wider range of customers using our services. We will keep making the greatest effort to deliver innovative services to everyone.
About NEXT-SYSTEM
NEXT-SYSTEM is a Japanese system development company founded in Fukuoka City in 2002, and since then has been focused on the research of behavior analysis through AI technology, ergonomic system development and research, development of cutting-edge xR systems (AR/VR/MR), and the development and sales of their Pose Estimation AI Engine "VisionPose" and AR Signage System "Kinesys", under their slogan "We Make The Future”.
Twitter
Facebook
LinkedIn
Youtube
Website



Categories related to this article


