![[SCoRe] Reinforcement Learning To Enhance LLM's Ability To Self-correct! Identify And Correct Errors In A Multi-step Process](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/score.png)
[SCoRe] Reinforcement Learning To Enhance LLM's Ability To Self-correct! Identify And Correct Errors In A Multi-step Process
3 main points
✔️ Proposes a new method called SCoRe using reinforcement learning to improve self-correction capabilities
✔️ Improves accuracy over previous methods, especially in math and coding tasks
✔️ SCoRe learns based on self-generated data and can self-correct without external feedback
Training Language Models to Self-Correct via Reinforcement Learning
written by Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, Aleksandra Faust
(Submitted on 19 Sep 2024)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Background
Traditional language models have difficulty correcting their own errors, especially "intrinsic self-correction," in which the model corrects itself without external feedback, with little success. To solve this problem, SCoRe uses reinforcement learning with self-generated data to train the model to sequentially correct its own answers.
While traditional methods require multiple models and outside mentors to help models correct errors, SCoRe aims to achieve self-correction with a single model. The approach is based on the fact that existing learning methods force models to follow only certain correction patterns, which prevents effective self-correction at test time. SCoRe addresses this problem by performing online reinforcement learning based on data generated by the models themselves, and is designed to help models learn to self-correct more SCoRe is designed to address this issue by performing online reinforcement learning based on data generated by the model itself, allowing the model to learn self-correction more effectively.
Proposed Method
The innovation of SCoRe is that the model learns how to identify and correct errors through multiple trials using self-generated data
- First, the base model is initialized, and the first stage maintains the accuracy of the first response while enhancing the modifications in the second response.
- Then, in the second phase, the model learns to self-correct effectively with reward bonuses to further encourage modification.
This two-step approach allows the model to accurately correct its own errors even during testing.
For example, for a math or programming problem, even if SCoRe's initial solution is incorrect, the model itself will detect the error and produce a more accurate solution on the next attempt. This process requires correcting only the errors while maintaining the correct parts; SCoRe learns this self-correction process through reinforcement learning and ultimately succeeds in significantly improving accuracy after correction.
This method significantly improves self-correction capability, especially in environments without external feedback, and achieves a 15.6% improvement in accuracy over conventional methods.
Experiment
The experiments in this paper examine how effectively Self-Correction via Reinforcement Learning (SCoRe) performs self-correction compared to other methods. The experiments were conducted primarily on two different tasks: solving mathematical problems and generating program code.
For the math problem, we first evaluated the performance of the base model using the MATH dataset. Next, we applied SCoRe and compared the first and second responses to see if the model could self-correct. Results showed that SCoRe improved first-time response accuracy from 60.0% to 64.4%, confirming that self-correction increases accuracy. In particular, the percentage of incorrect first-time responses being corrected to the correct answer increased, and the number of cases of incorrect corrections decreased.
For program code generation, we also checked whether SCoRe could self-correct in the coding task using the HumanEval evaluation criterion. In this task, SCoRe successfully improved its accuracy by 12.2% on the second attempt when the first solution was incorrect. This confirmed a significant improvement in the program's ability to correct errors, particularly its ability to correct errors while retaining portions of the program.
Furthermore, SCoRe was able to use computational resources more efficiently and obtain superior results with fewer trials. This indicates that the model can effectively learn to self-correct and achieve higher accuracy with fewer computational resources compared to traditional methods.
Thus, SCoRe has proven to be highly effective in learning models with self-correcting capabilities in multiple areas.
Conclusion
The paper concludes that Self-Correction via Reinforcement Learning (SCoRe) is an effective approach for large-scale language models (LLMs) to have self-correction capabilities.
Furthermore, SCoRe not only corrects errors, but also avoids unnecessary changes while maintaining the correct solution. In this way, the model has gained the ability to make modifications and increase accuracy to the extent appropriate, rather than being overly conservative in its modifications. Future research is expected to devise ways to increase the effectiveness of more multiple self-correction and further reinforcement learning.
Explanation of Figures and Tables
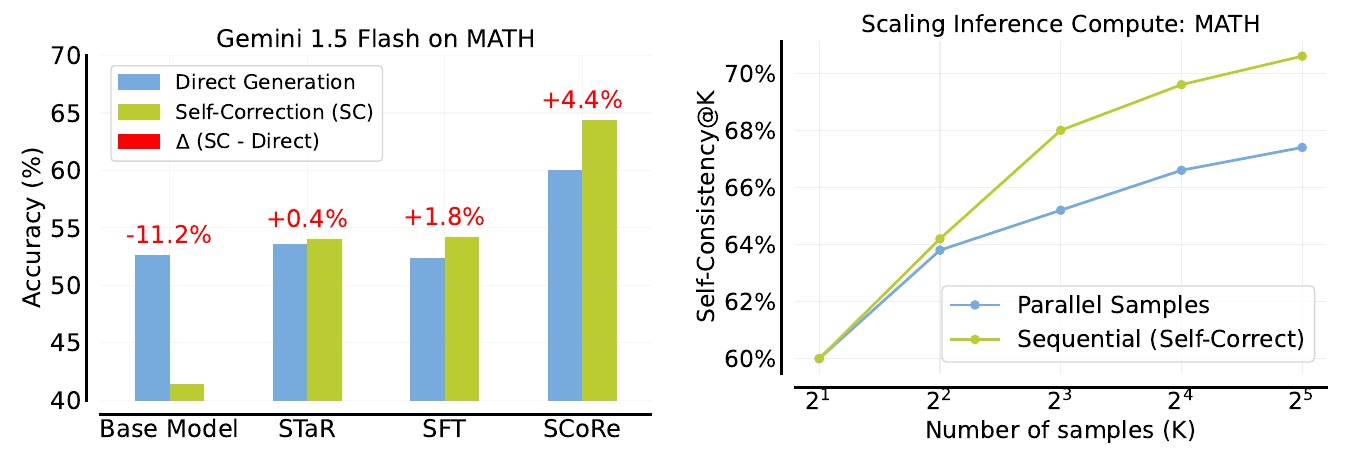
This chart shows the results of an experiment to evaluate the self-correcting ability of language models. Specifically, it compares the performance of the models in tests with mathematical problems.
The graph on the left shows the percent correct (Accuracy) for four different methods: Base Model, STaR, SFT, and SCoRe, where the Base Model is the original model while the others are models that we tried to improve using different learning methods. The blue bars indicate the percentage of correct responses for direct problem solving, while the green bars indicate the percentage of correct responses after self-correction. The numbers in red indicate the degree to which self-correction improved the model, with SCoRe showing the highest improvement (+4.4%); SCoRe also shows a higher percentage of correct responses than the other methods.
The graph on the right compares the performance of parallel sampling and sequential sampling with self-correction in terms of consistency (Self-Consistency) with increasing number of samples. The vertical axis shows the percentage of consistency, and the horizontal axis represents the number of samples. The green line indicates sequential sampling with self-correction while the blue line indicates parallel sampling. As the number of samples increases, sequential sampling is shown to be more consistent.
The results suggest that the ability of language models to self-correct is effective in solving mathematical problems and in processing large data sets.
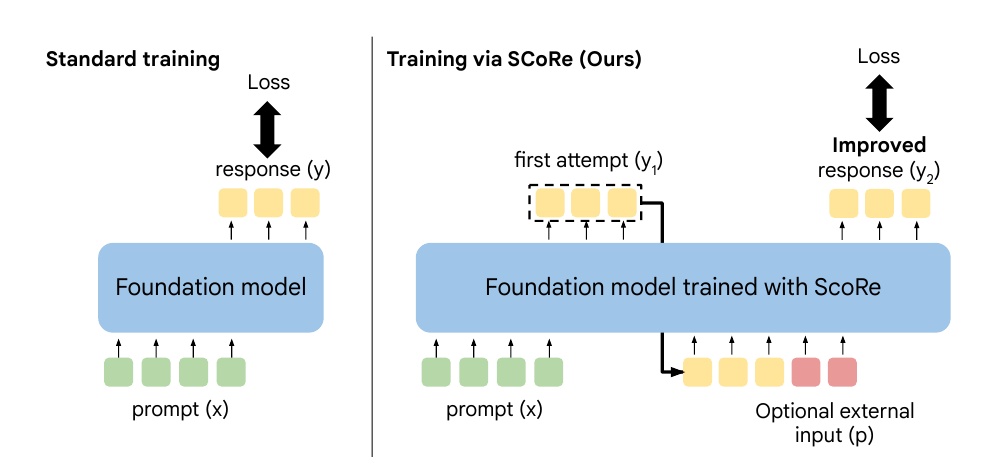
This figure shows how two different machine learning models are trained.
The left side shows the "standard training method. Here, the underlying model receives "prompt (x)" as input and generates "response (y)" in the process. Losses are calculated based on the generated responses, and the model is improved based on this information.
The right side shows the "Training Method with SCoRe. In this method, the model first generates a response (y₁) as the first trial, then the model self-corrects using "optional external input (p)" to generate an improved response (y₂). Based on this, losses are computed to improve the model. This process allows the model to self-correct the initial response while aiming for a better result.
SCoRe's approach aims to improve response accuracy through self-correction, making training more effective than standard methods.
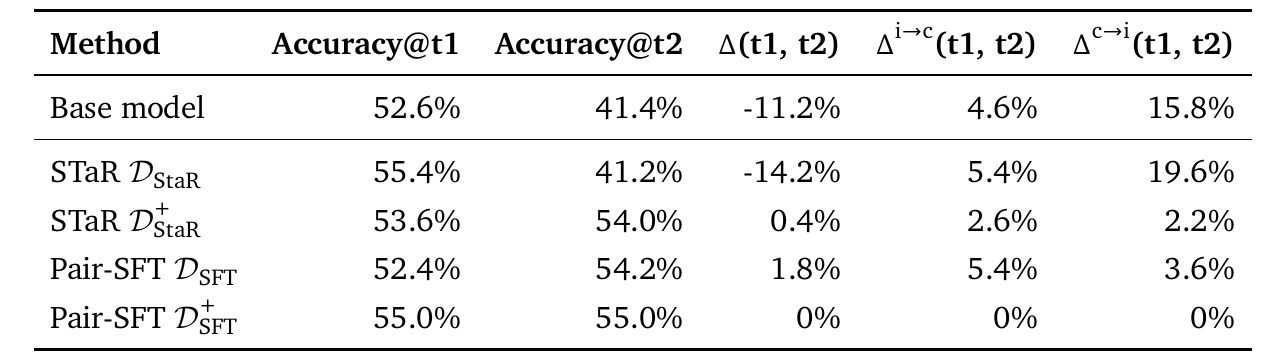
This table compares the performance of different models with respect to self-correction capability. Of particular note are the following
First, "Accuracy@t1" and "Accuracy@t2" indicate the accuracy of the model on the first and second attempts. For example, the first correct response rate for the base model is 52.6%, but this drops to 41.4% on the second attempt. This indicates that there is no improvement from the first response.
Next, "Δ(t1, t2)" represents the change in accuracy from the first to the second attempt, with higher values indicating greater improvement. The base model is -11.2%, with a drop in performance on the second attempt.
In addition, "Δi→c(t1, t2)" indicates the percentage of questions that are answered correctly the second time after the first error; the higher this value, the more successful self-correction is. For example, Pair-SFT D_SFT is 5.4%, indicating a certain degree of successful self-correction.
On the other hand, "Δc→i(t1, t2)" indicates the percentage of questions that are correct the first time and wrong the second time. The lower the value, the more desirable the result. The base model is 15.8%, indicating a significant loss of accuracy the second time around.
Through this table, it is important to understand the difficulties of self-correction, as well as areas for improvement and issues for each method. It is hoped that comparing the performance of models from various angles using different methods will lead to the development of effective self-correction models.
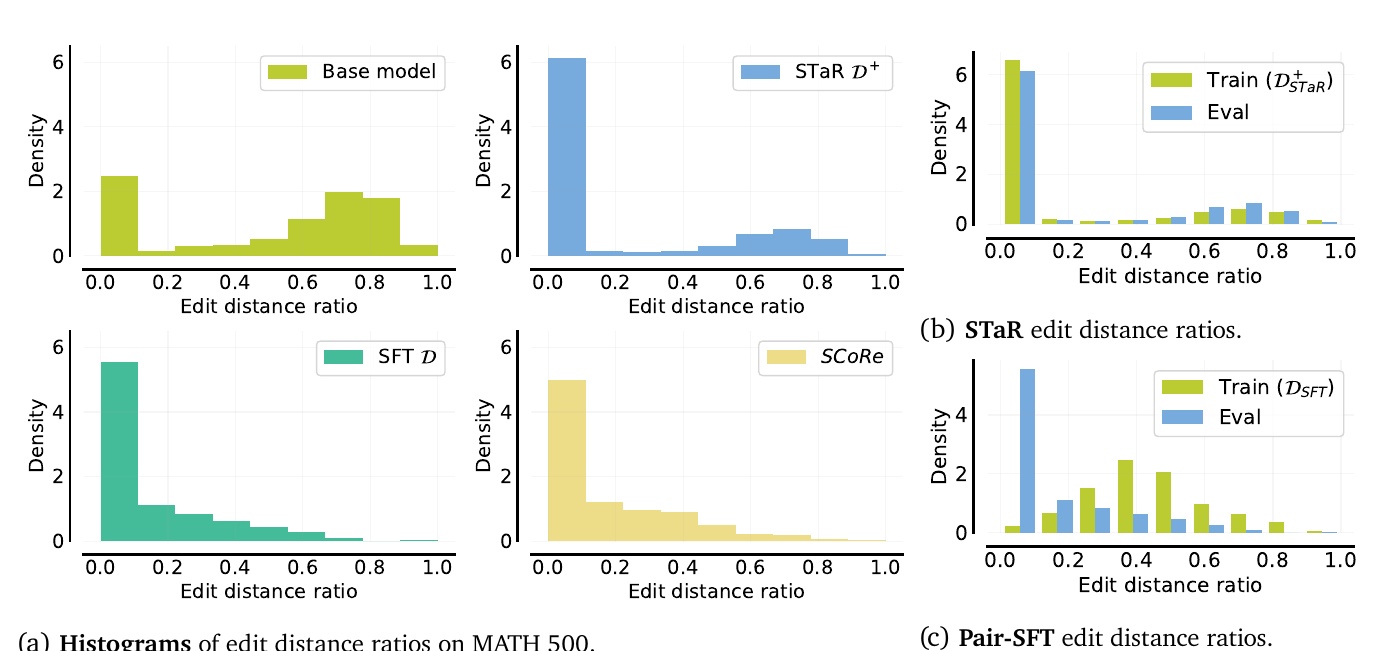
This figure is a histogram showing the percentage of edit distance due to different methods. The percentage of edit distance is a measure of how much the model self-corrects; the closer to zero, the fewer the changes.
The "Base model" figure shown in the upper left corner indicates that the original model underwent a relatively large number of modifications. Overall, you can see that the modifications cover a wide range.
The "STaR D⁺" in the upper right corner indicates little modification and few changes. The model tends not to do much self-correction.
The "SFT D" figure in the lower left-hand corner shows that corrections are slight, and in many cases are minimal.
The lower right "SCoRe" figure shows that moderation has taken place. This may indicate that self-correction has been effective.
The figures "b" and "c" show the percentage of edit distances on different data sets. The differences in edit distances between training and evaluation data are visually shown, with "b" showing the results of STaR and "c" the results of the Pair-SFT method.
Overall, these figures provide a visual comparison of the different self-correcting capabilities of the different models. By grasping the characteristics of each method, it is possible to identify areas for model improvement.
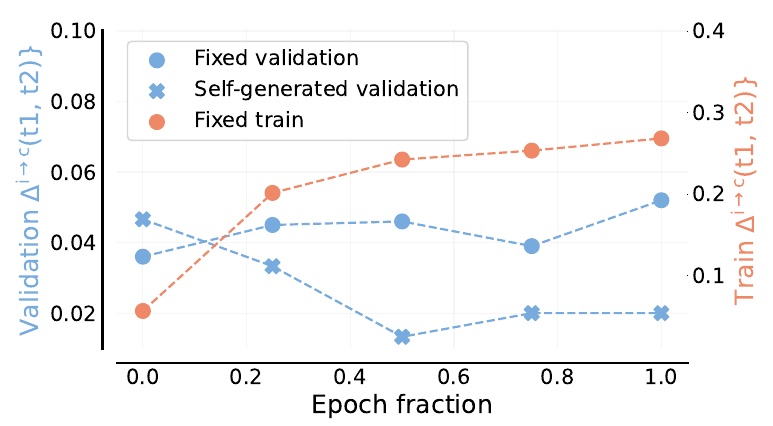
This figure shows the results of evaluating the model's ability to self-correct under different conditions. The vertical axis shows the percentage correct due to correction, and the horizontal axis shows the progression of the epoch. The orange line indicates training on fixed data, while the blue line and the light blue X mark the results on fixed and automatically generated validation data, respectively.
Initially, with training data, the percentage of correctness increases as the epoch progresses. On the other hand, in fixed validation data, we observe an improvement in performance, while in automatically generated validation data it is less constant and the improvement in performance is modest.
As can be seen from the figure, fixed data shows an increase in self-correction ability as training progresses, whereas this effect is less pronounced for automatically generated data. This suggests that there are differences in the model's ability to self-correct depending on the type of data.
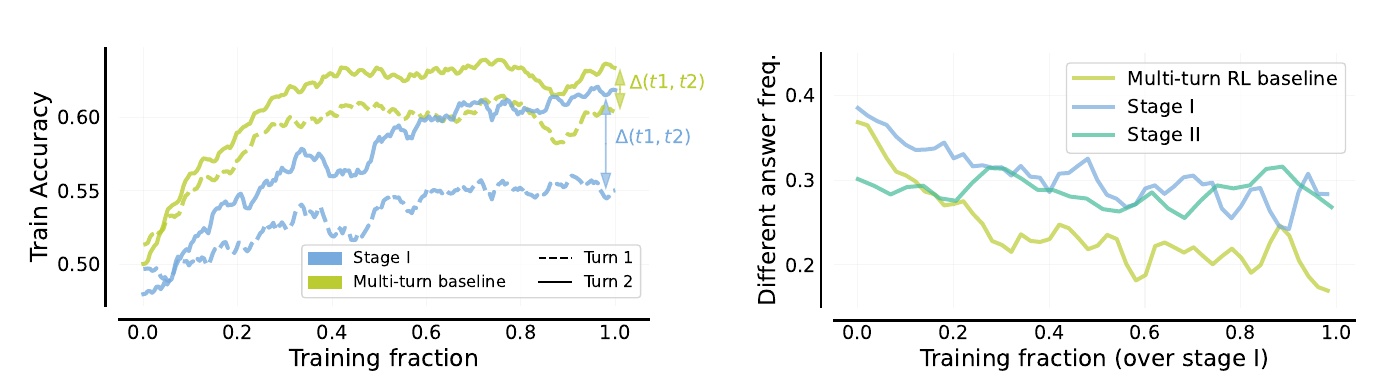
The left side of the figure shows the change in accuracy versus training progression. Stage I" and "Multi-turn baseline" compare accuracy on each trial. In the left graph, the blue line indicates that accuracy improves with training progression in "Stage I." The green line indicates that accuracy improves with training progression in "Multi-Turn Baseline. The green line represents the "multi-turn RL baseline," which also shows an improvement in accuracy, but less consistently than Stage I. In particular, "Turn 2" shows that Stage I is producing better results.
The figure on the right shows the frequency with which different answers are proposed. Comparing "Stage I," "Stage II," and "Multi-turn RL baseline," there is a gradual decrease in the frequency of Stage I and Stage II, indicated by the blue and green lines. This indicates that as training progresses, the model is producing the same answers less frequently, indicating improvement through learning. On the other hand, the green "Multi-turn RL baseline" shows a similar decrease, but tends to eventually fall below Stage II.
These results indicate that a multi-stage training approach is effective in enhancing self-correcting ability, and suggest that a combination of Stage I and Stage II is particularly useful.
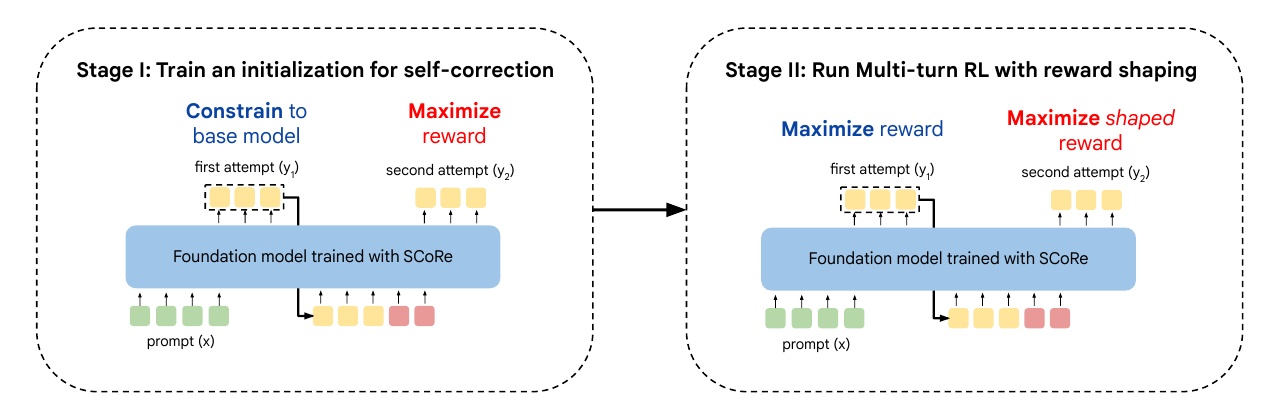
This figure illustrates a learning method for automatic correction called SCoRe, which gives models the ability to correct through a two-stage reinforcement learning (RL) process.
- In Stage I (first stage), initialization is performed on the underlying model. In this stage, the emphasis is on keeping the output of the first attempt close to the underlying model as a first step to allow the model to correct errors. This focuses on maximizing the reward on the next attempt (second attempt) while maintaining the model's original performance.
- Stage II (second stage) uses multi-turn reinforcement learning for further optimization. In this stage, we aim to maximize rewards on the first and next attempts, but especially on the next attempt, we utilize "shaped" (shaping) rewards to facilitate self-correction progress. This serves as guidance to help the model arrive at a better answer.
This step-by-step approach is designed to allow the model to self-correct effectively.
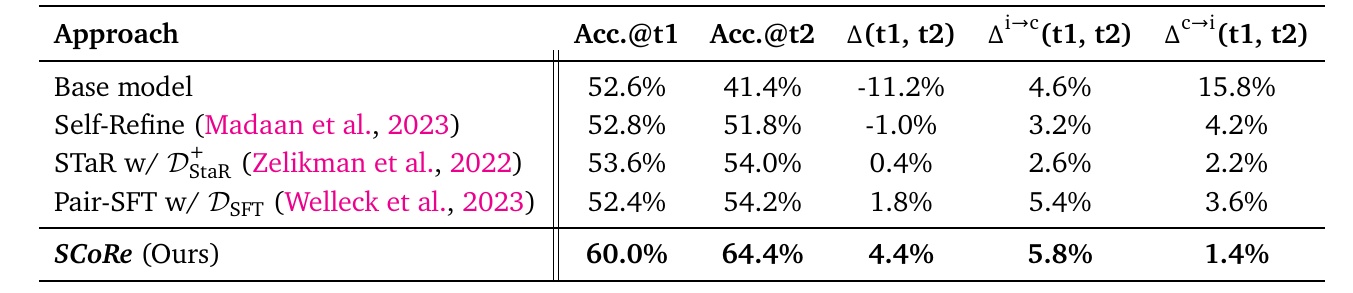
The figures and tables in the paper show a comparison of the model self-correction performance of different methods. Here, the four different methods of model training are first presented, along with five indicators of their respective self-correction performance.
Accuracy@t1 and Accuracy@t2 indicate the accuracy at the time of the first and second attempts, respectively.
2. delta(t1, t2) is a measure of how much accuracy was improved on the second trial.
3. Δi→c(t1, t2) shows the percentage of the second time that what was wrong the first time is correct.
4. Δc→i(t1, t2) shows the percentage of correct in the first time that is wrong in the second time.
The results show that the "SCoRe" method has the highest self-correction performance. Specifically, it achieved higher performance than the other methods for both Accuracy@t1 and Accuracy@t2, especially for Delta(t1, t2), showing a 4.4% improvement. This is significantly higher than the other methods, implying an improvement in corrective ability. The value of Δi→c is also the highest at 5.8%, indicating excellent self-correction capability in this respect as well. On the other hand, Δc→i is low at 1.4%, indicating a low percentage of wrong overwriting.
Overall, this chart shows that "SCoRe" is a model with superior self-correction compared to other methods.
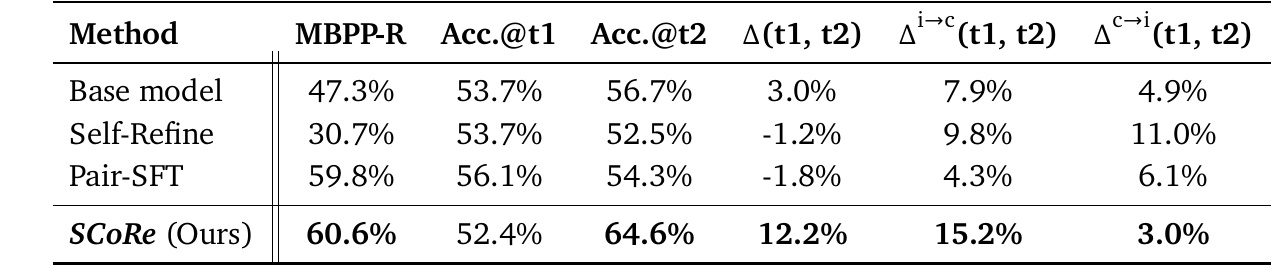
This table shows how well several models perform on specific tasks. Evaluation criteria include accuracy (Accuracy) on the first and second attempts, as well as the rate of improvement.
1. MBPP-R shows the percentage of accuracy achieved by each model in a particular code generation task. Here, SCoRe shows the highest performance at 60.6%.
2. Acc.@t1 and Acc.@t2 represent the accuracy at the first (t1) and second (t2) attempts, respectively. SCoRe outperforms the other models with 64.6% at the second attempt.
3. Δ(t1, t2) is the improvement rate from the first to the second trial. Again, SCoRe shows the highest improvement at 12.2%.
4. Δi→c(t1, t2) shows the percentage of questions answered correctly the second time that were answered incorrectly the first time. 15.2% for SCoRe, a higher improvement than the other methods.
5. Δc→i(t1, t2) is the percentage of questions that were answered correctly the first time and incorrectly the second time. Here SCoRe is shown to be 3.0%, which is relatively low compared to the other models, indicating less deterioration in answers.
From this table, we can see that SCoRe performs better overall than the other methods. In particular, it has superior self-correction capabilities, greatly improving results after the first trial.
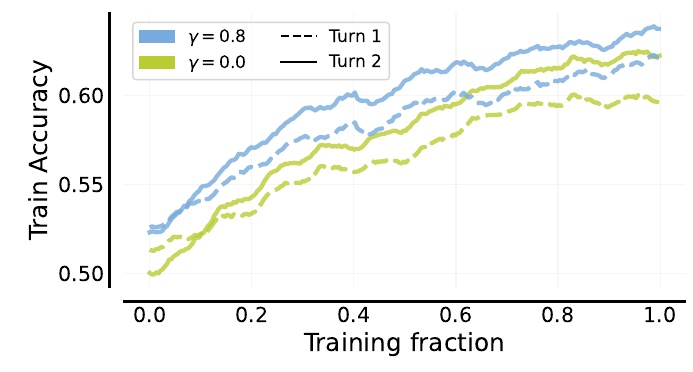
This figure shows how a machine learning model uses training data to improve its accuracy. The legend at the top shows that the model is trained under two different conditions (γ=0.8 and γ=0.0) with a different parameter, γ. This γ can be considered the discount factor in a standard reinforcement learning setting.
The horizontal axis of the figure shows the "training fraction," which represents how much of the total training data was used. In other words, it shows how the data is used in steps ranging from 0.0 to 1.0.
The vertical axis is "Train Accuracy," which represents the training accuracy of the model. The type of line is also important: there are dashed and solid lines labeled "Turn 1" and "Turn 2". These show the accuracy on the first and second trial for each γ setting.
The blue line at γ=0.8 shows relatively high accuracy on the first and second trials, with accuracy improving as training progresses. On the other hand, the yellow line γ=0.0 tends to have slightly lower accuracy.
This allows for a comparison of the impact of the discount factor on training accuracy and provides insight into effective parameter settings.
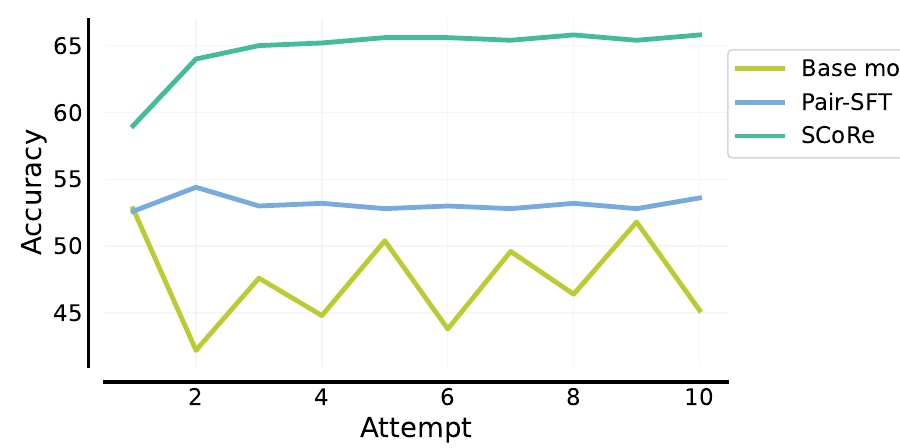
This figure shows how much accuracy (Accuracy) the machine learning model achieved for the number of "trials". The vertical axis represents the accuracy and the horizontal axis represents the number of trials. Specifically, the performance of three different approaches is compared.
First, the green line shows a new approach called SCoRe. This approach maintains high accuracy as the number of trials progresses, and its performance consistency stands out compared to other methods.
Next, represented by the blue line, is Pair-SFT. This method has not reached as high an accuracy as SCoRe, but it is relatively stable.
And the yellow line shows the Base model. We can see that this approach has rather low accuracy and high trial-to-trial variability.
From this figure, it can be understood that SCoRe achieves higher accuracy and more stable results than other methods. In particular, it is remarkable that this trend continues even as the number of trials increases. This indicates that SCoRe has excellent self-correction capability, which represents its effectiveness as a new learning approach.

This chart shows the hyperparameter settings for two different underlying models, Gemini 1.5 Flash and Gemini 1.0 Pro. Hyperparameters are parameters that are set externally to adjust the model's learning.
The table on the left shows information about the Gemini 1.5 Flash model. Adam" is used as the optimization algorithm. The learning rate is "5e-6" and the number of training steps is 3000. The batch size is 512 and the temperature during sampling is set to 1.0. Additionally, the value of α is 10, β1 is 0.01, and β2 is 0.1.
The table on the right shows the settings for the Gemini 1.0 Pro model. The optimization algorithm, sampling temperature, α, and β1 are the same as for the model on the left, but the learning rate is set to "1e-5" and the number of training steps is 1500, which is fewer. The batch size is also set smaller, 128. only β2 is different, this one is 0.25.
These settings have a significant impact on the performance of the model and must be appropriate for the purpose of each model.

This image shows several tasks in Python programming. First, there is a function called `similar_elements`, which finds common elements in two tuples and returns them as a tuple. This function looks for common elements while eliminating duplicates in the list by using `set`.
Next, there is a function called `is_not_prime`. This function determines if a given integer is not prime. It uses a loop up to the square root to see if it is divisible by an integer from 2 to the square root of that number. If it is divisible by either, it returns `True` as not prime. Otherwise, it returns `False`.
These functions are used as examples to illustrate some test cases and to verify that each function works as intended. This provides an example of using your coding skills in Python for different program tasks.

This figure shows the Python code. The code takes two words as input and determines if the second word or any rotation thereof is a substring of the first word.
Specifically, it uses a for loop to generate each rotated version of the second word and checks whether it is contained within the first word. If it is, it returns True; otherwise, it returns False.
The point of this code is the "rotation" operation, which is achieved by cutting and connecting the string at b[i:] + b[:i]. It then judges whether a.find(rotated_b) is not -1 or not. This conditional expression indicates when the rotated string is contained in the first string.

This figure shows a piece of Python code. It represents a function that counts the even and odd digits of a given number and returns it as a tuple.
The structure of the code is briefly described below. First, it takes the absolute value of a number, converts it to a string, and extracts each digit of the string. Next, it converts the digits to integers and determines whether the number is even or odd. If it is even, it increases `even_count`, and if it is odd, it increases `odd_count`.
Finally, it returns even and odd counts in tuple form so that the composition of a given number can be understood in terms of numerical values. This code is useful for numerical analysis and statistics.

This diagram illustrates the process of solving a mathematical problem concerning a matrix. In the problem, the matrix \( A \) is given and the results of the computation of that matrix using two different vectors are shown. The user then needs to find the action of the matrix \( A \) on a new vector.
First, the first answer attempts to represent the vector as a linear combination of two known vectors using the scalars \( a \) and \( b \). However, the first answer contains a computational error and yields incorrect results.
The second solution then uses the same technique to transform this vector again into \( a \) and \( b \) to construct the system of equations. This process involves correctly solving the equations and finding the values of \( a \) and \( b \), respectively. The results are then used to perform matrix calculations to arrive at the correct final answer.
This diagram visually illustrates the flow of solving a problem using the linear combination method in matrix calculations, and clearly depicts the erroneous attempts and the process of correcting them.

This figure is an example to illustrate a self-correcting algorithm called SCoRe.
The first example shows the problem of simplifying a mathematical expression. On the first attempt, the correct answer was not obtained. Specifically, the division and multiplication steps were incorrect in the calculation of fractions. In the subsequent second attempt by SCoRe, the calculation errors were corrected and the correct answer was obtained. Through this process, we show how the model finds the wrong part and leads to the correct conclusion.
In the following example, we are presented with a problem about the roots of a polynomial equation. In the first attempt, the formula was used to compute the numbers, but an error occurred in the part where the smallest absolute value was found; in the second attempt by SCoRe, the computational approach was modified, and by evaluating the roots logically, the correct minimum value was successfully found.
These examples show how SCoRe improves problem-solving skills through self-correction. It detects errors in formulas and logic on its own to help the user visually understand the effectiveness of the algorithm in producing better answers.

This diagram shows how the model derives a solution to a mathematical problem. The problem is to find the minimum value of \((x + 5)(x + 2)/(x + 1)\). In the first attempt, the model expands this equation and attempts a partial simplification, but comes to the wrong conclusion. By transforming the equation, let us assume that the erroneous minimum is 6. This is not the correct value because of the incorrect calculations involved in the derivation. This shows the process by which the model attempts to self-correct and find a solution. This example shows an attempt to rethink and correct the initial answer, even if it is incorrect.

This image shows an example of problem solving using the SCoRe approach. Here, the problem of finding the minimum of the formula (x + 5)(x + 2)/(x + 1) is discussed.
First, the denominator and numerator are considered separately, and this formula is simply changed. The formula (x + 5)(x + 2)/(x + 1) is expanded into (x^2 + 7x + 10)/(x + 1), which is then further divided into the parts (x^2 + x) + (6x + 6) + 4. Based on this decomposition, it was simplified to the form (x + 1)(x + 6) + 4/(x + 1). Finally, the equation becomes x + 6 + 4/(x + 1).
Next, based on the condition that x is greater than 0. This makes x + 1 greater than 1 and 4/(x + 1) less than 4, so we conclude that (x + 5)(x + 2)/(x + 1) is greater than x + 6.
Thus, we see that when x is positive, the minimum value of this equation is greater than 6. As a result, the minimum value of x + 6 + 4/(x + 1) is 6.



Categories related to this article
![Libra] A New Multimo](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




