Introducing HyperCLOVA: The Korean GPT-3
3 main points
✔️ A GPT3-scale language model for the Korean Language called HyperCLOVA.
✔️ Experiments using HyperCLOVA of different sizes on various NLP tasks.
✔️ HyperCLOVA Studio, a platform to distribute services provided by HyperCLOVA.
What Changes Can Large-scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-scale Korean Generative Pretrained Transformers
written by Boseop Kim, HyoungSeok Kim, Sang-Woo Lee, Gichang Lee, Donghyun Kwak, Dong Hyeon Jeon, Sunghyun Park, Sungju Kim, Seonhoon Kim, Dongpil Seo, Heungsub Lee, Minyoung Jeong, Sungjae Lee, Minsub Kim, Suk Hyun Ko, Seokhun Kim, Taeyong Park, Jinuk Kim, Soyoung Kang, Na-Hyeon Ryu, Kang Min Yoo, Minsuk Chang, Soobin Suh, Sookyo In, Jinseong Park, Kyungduk Kim, Hiun Kim, Jisu Jeong, Yong Goo Yeo, Donghoon Ham, Dongju Park, Min Young Lee, Jaewook Kang, Inho Kang, Jung-Woo Ha, Woomyoung Park, Nako Sung
(Submitted on 10 Sep 2021)
Comments: Accepted to EMNLP2021.
Subjects: Computation and Language (cs.CL)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
GPT-3 is a large and powerful language model that has gained significant attention from inside and outside the AI community. GPT-3 uses in-context information (discrete prompts that consist of a task description and few-shot examples) to infer predictions for the target task. However, we think that there are still a number of issues that need proper investigation. GPT-3's training data is heavily skewed towards English(92.7%) which makes it difficult to apply and test on other languages. So, we train a Korean in-context large-scale model called HyperCLOVA. Currently, there are models with up to 13B parameters and GPT-3 has 175B parameters, but thorough analysis of models in between 13-175B does not exist. So, we also train 39B, 82B models to be able to perform analysis on a mid-range(relatively) model. We also investigate the effect of language-specific tokenization, zero-shot, and few-shot capabilities of hyperCLOVA and much more. Finally, we experiment with advanced prompt-based learning methods that require backward gradients of inputs on our large-scale language model.
HyperCLOVA
Training datasets and models
GPT-3's training data consists of just 0.02% Korean data by character count. So, we built a large corpus of training data from the Internet including user-generated content and content provided by external partners. That sums to about 561B tokens of Korean language data. We use the same architecture as GPT-3 with several configurations as shown below. We are interested in analyzing the mid-range models because, despite the lack of studies being conducted about them, they have more plausible sizes for real-world applications.
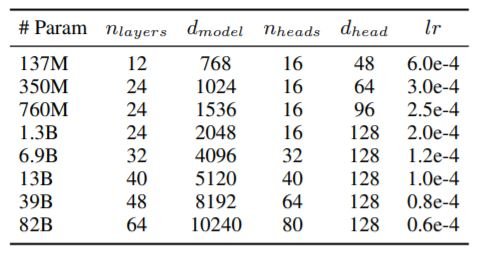
We use Megatron-LM and trained our models on the NVIDIA Superpod, which includes 128 strongly clustered DGX servers with 1,024 A100 GPUs. We use AdamW with cosine learning rate and weight decay as optimizers and mini-batch size of 1024.
Korean Tokenization
Korean is an agglutinative language where the noun is followed by a particle, and the stem of the verb or adjective is followed by endings, expressing various grammatical properties. It has been shown that using English-like tokenization for Korean degrades the performance of Korean language models. So, we use a morpheme-aware byte-level BPE as our tokenization method.
We tested our tokenization methods on KorQuAD and two AI Hub translation tasks considering Korean linguistic characteristics. We compare our method to byte-level BPE and char-level BPE tokenization which are also widely used for Korean tokenization. Char-level tokenization sometimes yields out-of-vocabulary(OOV), and omits some Korean characters. Except for Korean to English translation, where our morpheme analyzers make the performance worse, our method is superior to byte-level and char-level BPE in all other tasks. This shows the importance of language-specific tokenization in large language models.
Experiment and Evaluation
We use five different datasets for evaluating our models: NSMC is a movie review dataset, KorQuAD 1.0 is a Korean machine reading comprehension dataset, AI Hub Korean-English corpus consists of Korean-English parallel sentences from various sources, YNAT is a topic classification problem with seven classes, KLUE-STS is a sentence similarity prediction dataset.
In-Context Few-Shot Learning
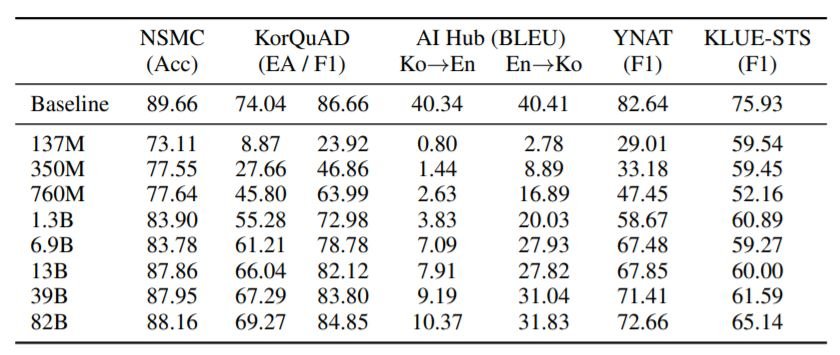
The above table shows the results on various in-context learning tasks. As expected, the performance improves monotonically with the model size. However, the performance on KLUE-STS and translation tasks is much lower than baseline. We hope that more sophisticated prompt engineering from future works can improve these results.
Prompt-Based Tuning (p-tuning)
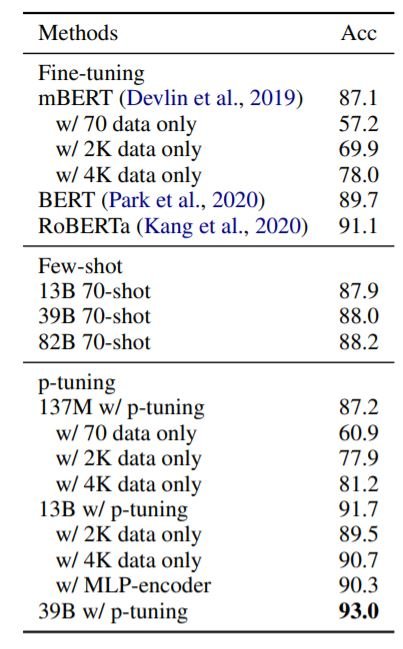
The above table shows the results of p-tuning on NSMC. p-tuning allows HyperCLOVA to outperform all other models without any change in the model parameters. p-tuning with only 4K instances is enough to outperform RoBERTa fine-tuned with 150K instances.
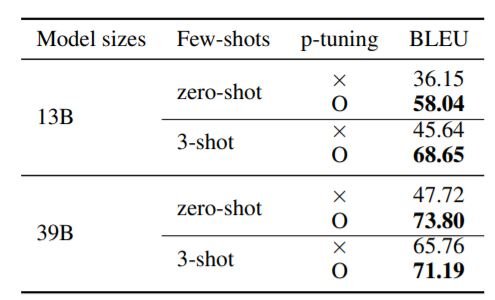
The above table shows how p-tuning significantly improves the zero-shot and 3-shot performance on our in-house query modification. This suggests that having access to the backward gradients on the input data from GPT3-scale models, allows us to improve the representation power of the model for the task at hand. This can be really useful for researchers without resources to train GPT3-scale models.
HyperCLOVA Studio
We introduce HyperCLOVA Studio to distribute our powerful model. HyperCLOVA Studio is a place for building and communicating the shared artifacts generated by HyperCLOVA. It allows rapid prototyping of AI services with minimum involvement of AI engineers. Next, we discuss a few use-case scenarios of HyperCLOVA.

Character bot: We found that HyperCLOVA allows us to create ChatBOTs with specific personalities that can be specified just by a few lines of description, and a few dialog examples. The above image (a) shows an example (prompts in italics, output in normal font).
Zero-shot transfer data augmentation: The objective here is to build utterances tailored to user intent. For example: for the intent “reservation query with one person”, the output sentences like “Is it OK for reservation with one person?”. The intent can be of varying complexity, even something short like "reservation inquiry".
Event-title generation: HyperCLOVA works extremely well for event-title generation tasks. Ex: for a product promotion event, it takes in five product examples including event date and keywords as the prompt and outputs an appropriate event name(Jewelry for you who shines brightly). HyperCLOVA can also be adapted to other domains like the advertisement headline generation task with minimum effort.
Besides these, HyperCLOVA provides the input gradient API, which helps you to enhance the performance of your local downstream tasks using p-tuning. We also provide filters for the input and output in order to prevent misuse of HyperCLOVA.
We believe that large-scale models like HyperCLOVA can be beneficial in accelerating the NLP operation life cycle. Developing and monitoring ML systems is an iterative process that currently requires experts to do certain tasks again and again. This is costly and prevents companies from integrating their products with AI. Although it is currently a challenge, HyperCLOVA could help in the Low/No Code AI paradigm and radically reduce the cost of developing ML systems by making development accessible to non-experts.
Summary
This paper gives valuable insights for developing language-specific large-scale models by highlighting the importance of language-specific tokenization, p-tuning, and more. The objective behind HyperCLOVA (Studio) is to democratize the development of AI in Korea by allowing non-experts to build their own AI models. At the same time, it is necessary to be aware of problems such as misuse of these models, fairness, biases, etc, and make constant strides to move in a positive direction.



Categories related to this article






