
Pyramid Supervision, A New Framework To Power Pixel-Wise Supervision In The Area Of Facial Spoofing Detection.
3 main points
✔️ Provides a comprehensive review of existing Pixel-Wise Supervision in the field of face spoofing detectionWe provide a comprehensive review of existing Pixel-Wise Supervision in
✔️ for fine-grained learning and more Utilization We propose a new Pyramid Supervision that can provide informative multi-scale spatial context and can be easily integrated into existing methods.
✔️ Achieves better performance than existing Pixel-Wise Supervision frameworks and improves model interpretability
Revisiting Pixel-Wise Supervision for Face Anti-Spoofing
written by Zitong Yu, Xiaobai Li, Jingang Shi, Zhaoqiang Xia, Guoying Zhao
(Submitted on 24 Nov 2020)
Comments: submitted to IEEE Transactions on Biometrics, Behavior and Identity Science
Subjects: Computer Vision and Pattern Recognition (cs.CV)
outline
In recent years, facial recognition technology has become increasingly popular. It is used as a matter of course in unlocking smartphones and entering and leaving airports. Facial recognition is also expected to be used to manage the personnel involved in this year's Olympic Games. At the same time, however, concerns about face spoofing are growing, and the field of Face Anti-Spoofing (FAS), a technology to prevent this, is attracting attention.
Spoofing technology is evolving every year. As new types of spoofing become more realistic, there is a need for robust algorithms that can detect spoofing in scenarios that have not been trained by existing models. Traditional models based on binary classification (e.g., "0" for real and "1" for spoofing) are relatively easy to build and achieve high performance, but have the weakness of being difficult to learn intrinsic and discriminative spoofing patterns.
Therefore, Pixel-Wise Supervision, which aims to learn more fine-grained pixel/patch level features that are more useful for discrimination, has recently been proposed in the FAS task.
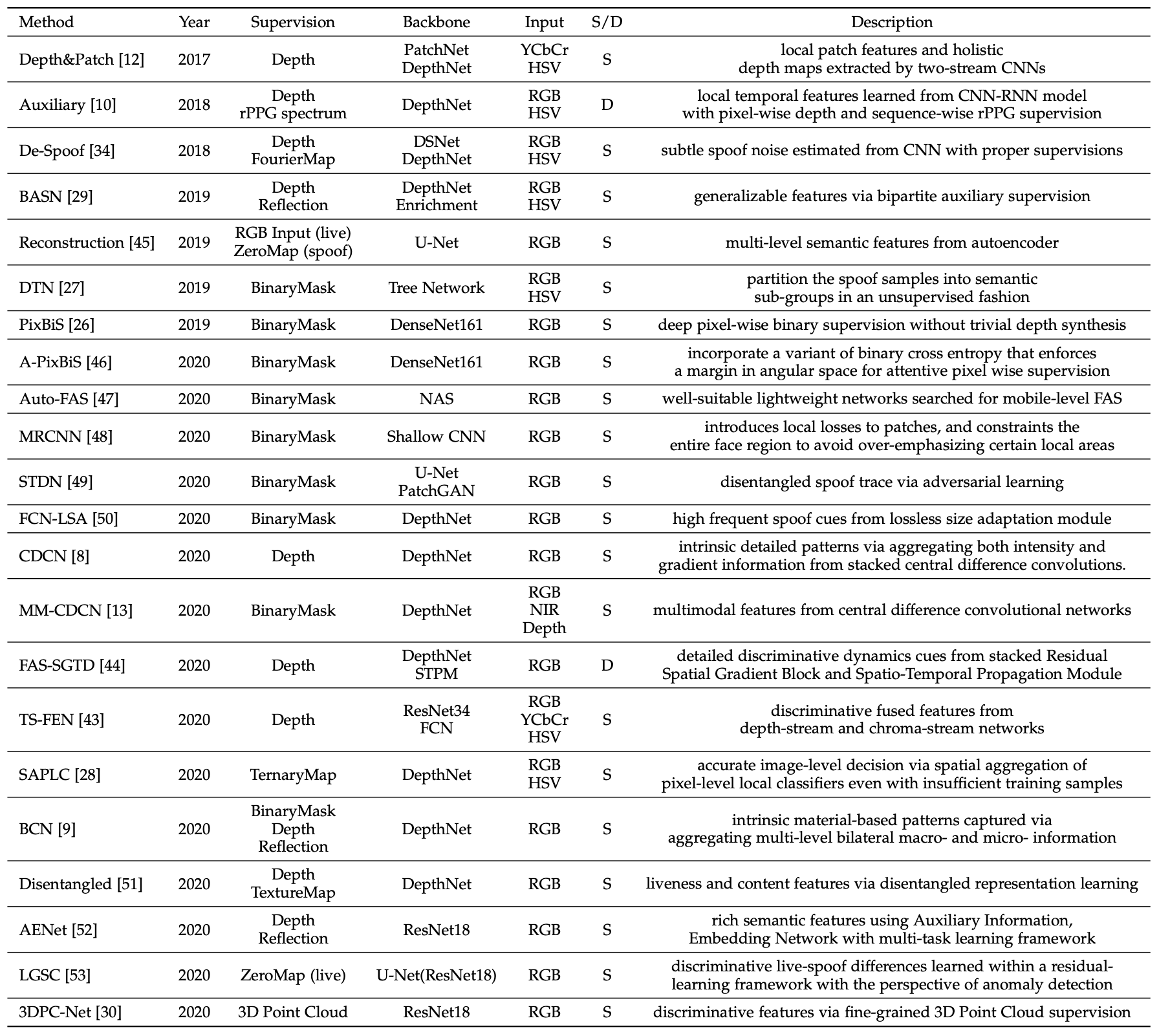
In this paper, after a comprehensive review of previous methods as shown in the table above, we propose a new framework called Pyramid Supervision that learns both local details and global semantics information from a multi-scale spatial context. In this article, we present the framework and its performance.
We conducted extensive experiments on five FAS benchmark datasets and found that Pyramid Supervision not only improves the performance of the existing Pixel-Wise Supervision, but also identifies the traces of spoofing at the patch level and improves the interpretability of the model. interpretability.
New framework "Pyramid Supervision
Pyramid Supervision can be easily introduced into existing methods to improve their performance. In this paper, we show an example of introducing Pyramid Supervision into two typical methods Binary Mask Supervision and Depth Map Supervision.
First, the figure of Pyramid Binary Mask Supervision, which applies Pyramid Supervision to Binary Mask Supervision, is shown below.
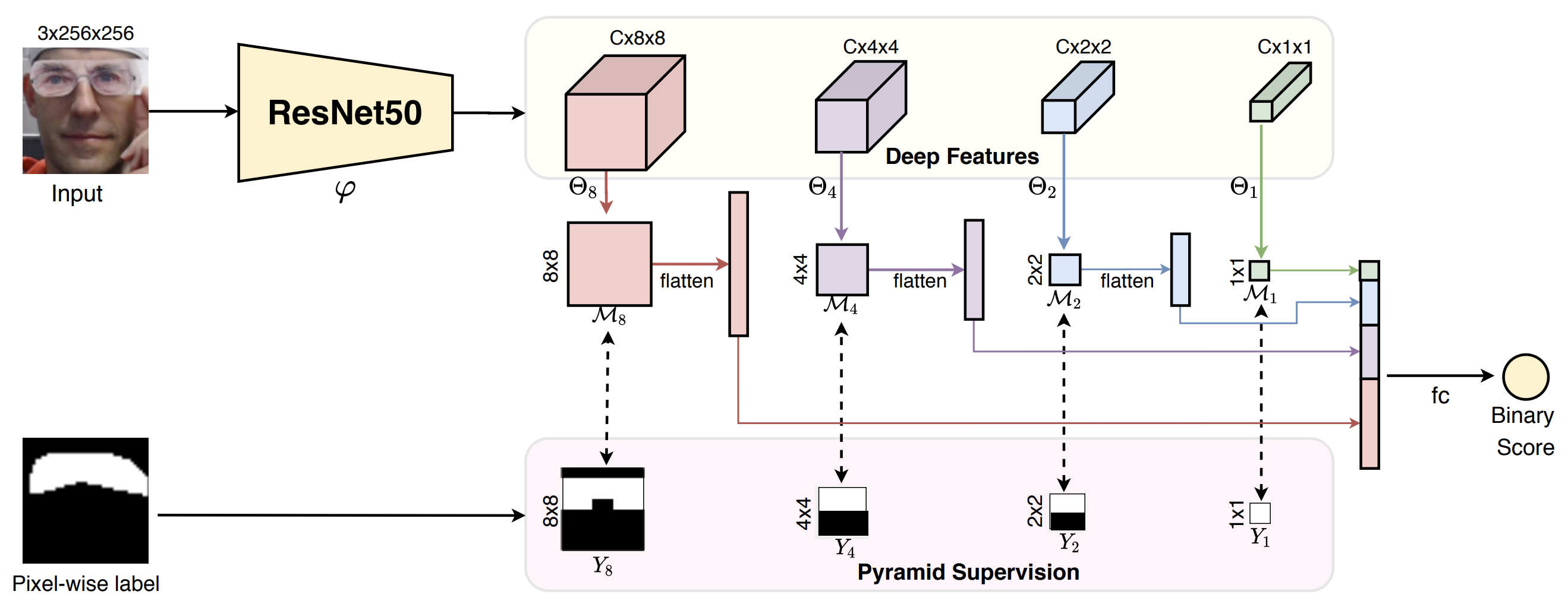
Multi-scale features (F8,F4,F2,F1)are extracted from RGB input image (3×256×256) and Average Pooling is applied after extracting each feature. Furthermore, each feature(F8,F4,F2,F1), a feature-to-mask mapping with 1x1 Conv is performed to obtain a multiscale binary mask (Θ8、Θ4、Θ2、Θ1). The multiscale binary mask prediction can be formulated as follows can be formulated as follows.
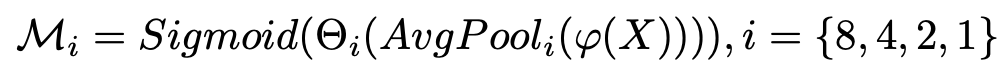
Each of the generated multi-scale binary masks is transformed and concatenated to one dimension, and finally a binary classification is applied. For the per-pixel Ground Truth ( Y ), the already annotated binary mask labels can be used directly or the generated coarse binary masks can be used converted to the same multi-scale mask labels (Y8、Y4、Y2、Y1)as the input image.
The predicted multiscale binary mask and Ground Truth are of the same size and the loss function(Lpyramid) is computed by accumulating the Binary Cross-Entropy (BCE) at each position of each scale.
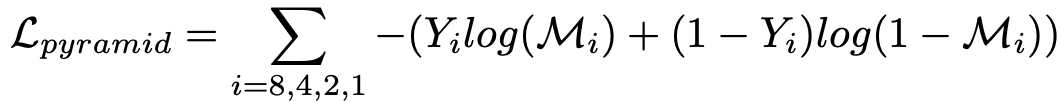
During training, the overall loss function (Loverall) of the network can be formulated as follows Lbinary will be the BCE of the last binary classification. During testing, only the final binary score is used.
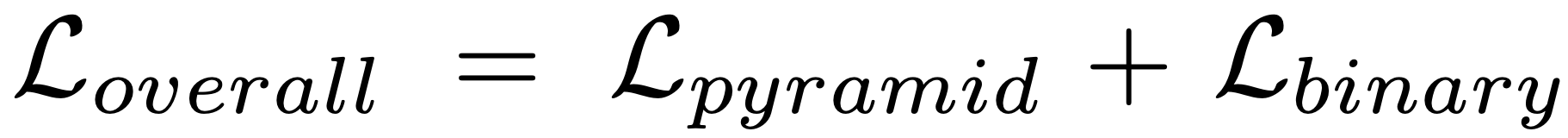
Next, Pyramid Depth Map Supervision is applied to Depth Map Supervision as shown below.
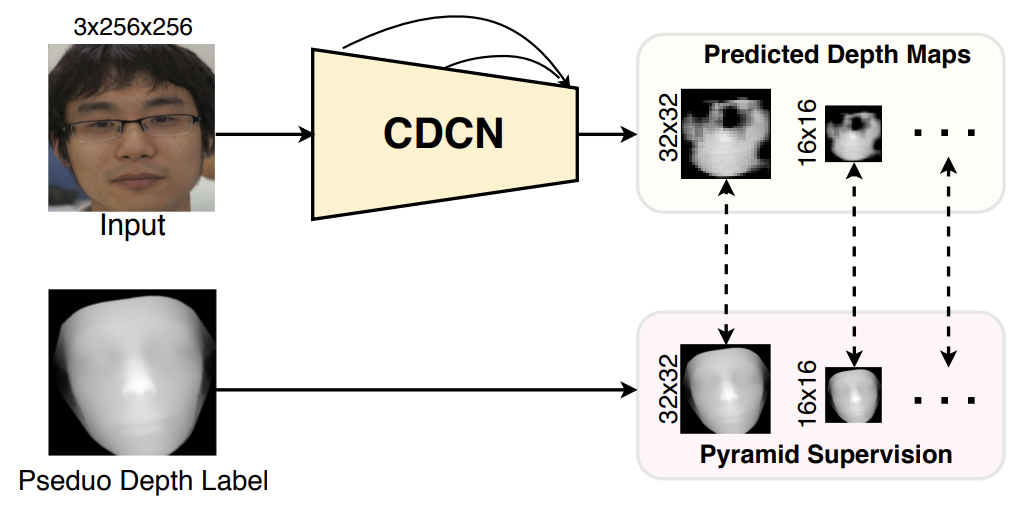
As shown in the figure, CDCN extracts multi-level features from the input image (3 × 256 × 256) and predicts a gray-scale Depth Map (32 × 32). Similar to Pyramid Binary Mask Supervision, both the predicted Depth Map D32 (32×32) and the generated Pseduo depth are downsampled and resized to the same scale (32×32, 16×16, etc.).
Pyramid Depth Loss (LdepthPyramid) can be formulated as follows.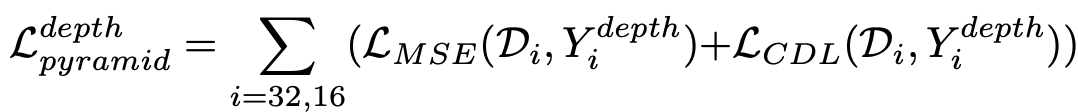
Here, Di represents the scale i of the predicted Depth Map. Also, LMSE and LCDL represent Mean Square Error (MSE) and Contrastive Depth Loss (CDL), respectively. Contrastive Depth Loss (CDL) is a loss function proposed in CVPR2020 and is formulated as follows.
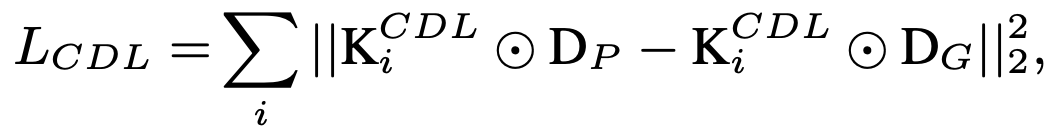
This is a newly introduced loss because the commonly used Contrasive Loss using Euclidean distance does not take into account the neighboring pixel information and the detailed information is lost, which affects the generalization performance.
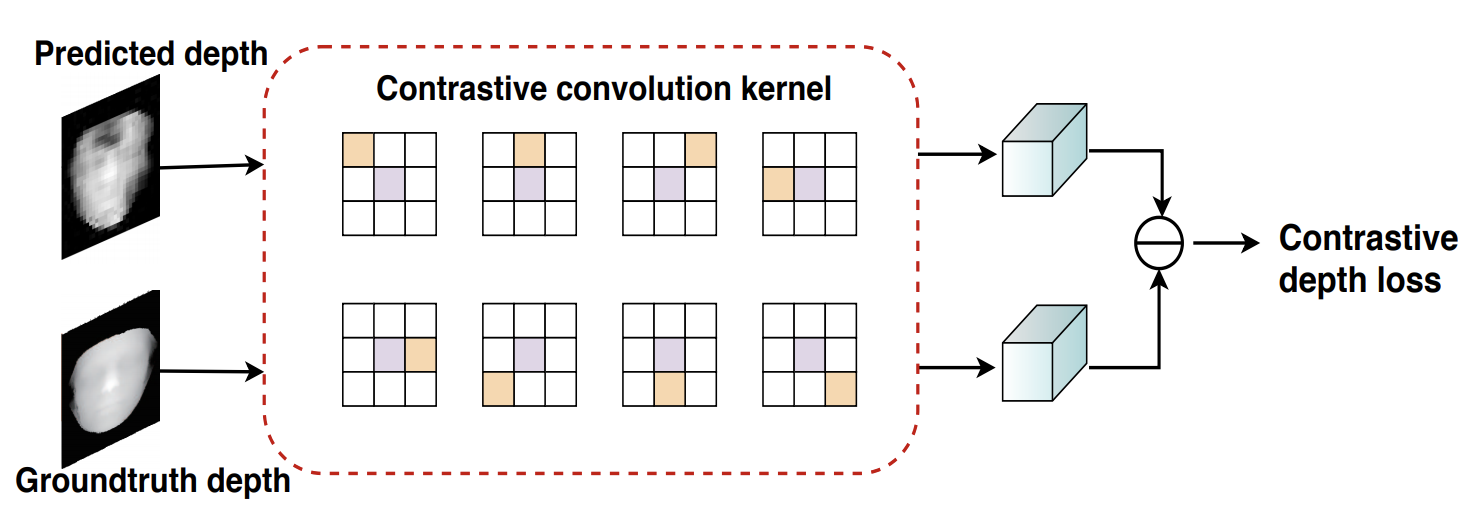
(出典:Deep Spatial Gradient and Temporal Depth Learning for Face Anti-spoofing)
During training, only the LdepthPyramid is used, and during testing, the average of the Depth Map predicted from all scales is computed as the final score.
experiment
As briefly mentioned above, in Pixel-Wise Supervision-based FAS, the mainstream Backbone can be divided into two categories.
1) Binary Mask Supervision based networks (such as ResNet and DenseNet)
2) Pseudo Depth Supervision based networks (such as DepthNet)
Here, we use the representative ResNet50 and CDCN as baselines, respectively, and compare them with the model with Pyramid Supervision.
Intra-Dataset Intra-Type testing ( OULU-NPU)
The Intra-database test is a performance evaluation on a specific dataset. We use a representative data set, OULU-NPU, to evaluate the performance. For a fair comparison we use the original protocol and metrics, the metrics are Attack Presentation Classification Error Rate (APCER), Presentation Classification Error Rate (BPCER) and ACER calculated by the average of these We use ACER, which is calculated by APCER is the percentage of spoofing that is misclassified as genuine, and PCER is the percentage of spoofing that is misclassified as PCER is the percentage of spoofed and misclassified authentic.
The table below shows the results of the Intra-Dataset test using OULU-NPU, where Prot. represents the four protocols provided by OULU-NPU.
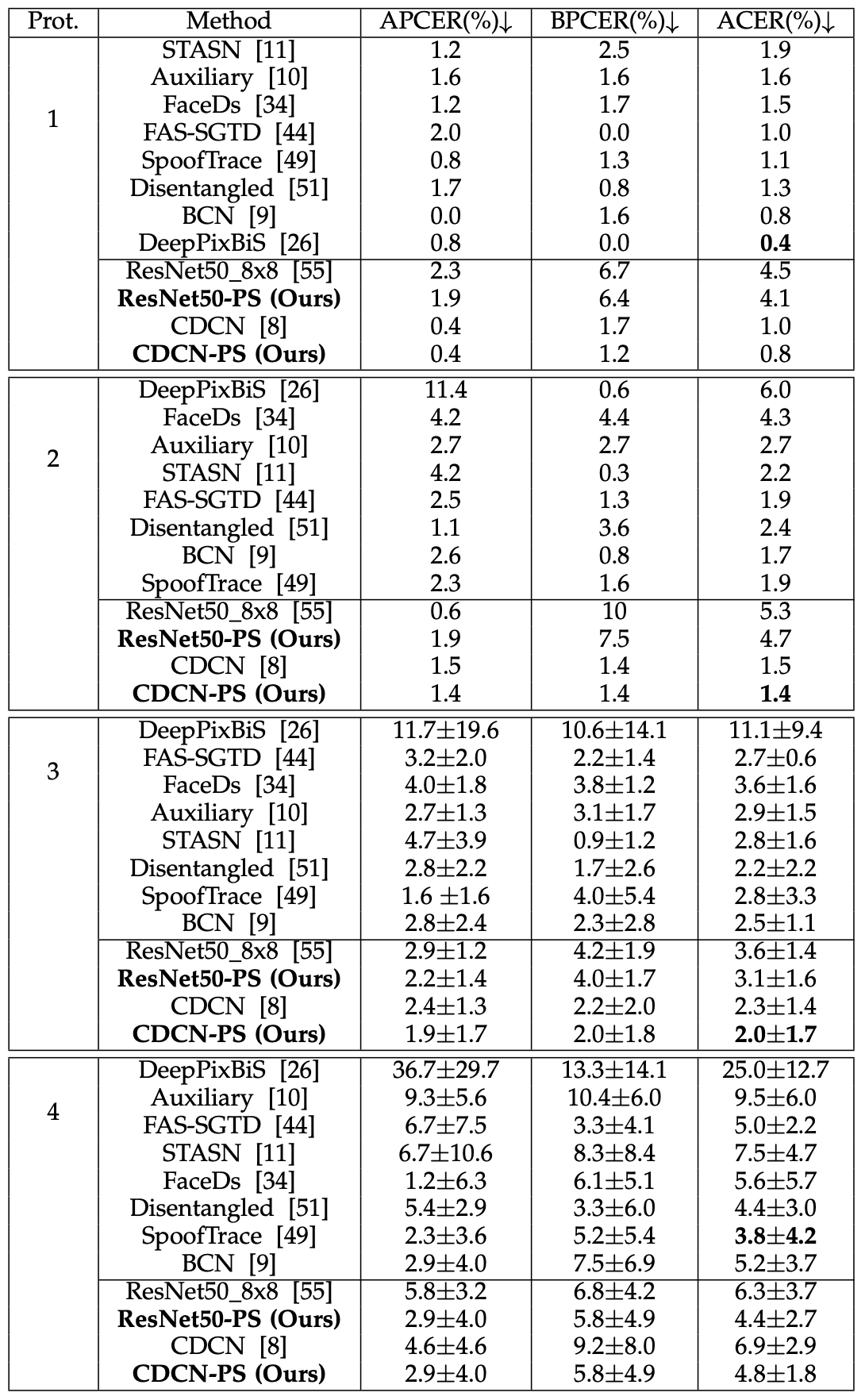
Looking at the ACER, focusing on the proposed Pyramid Supervision (PS), we can see that it consistently decreases and improves the performance across the four protocols. In other words, it shows improved generalization performance with respect to external environment such as lighting, attack medium and input camera.
Looking at the model by model, CDCN-PS achieves better or comparable performance to the model than SOTA's in four protocols. ResNet50-PS shows very good results, performing better than CDCN-PS in protocol 4, where it is hardest to achieve high performance, even though the performance of the first three protocols is not so high. This indicates that Pyramid Supervision is highly effective even with limited training data.
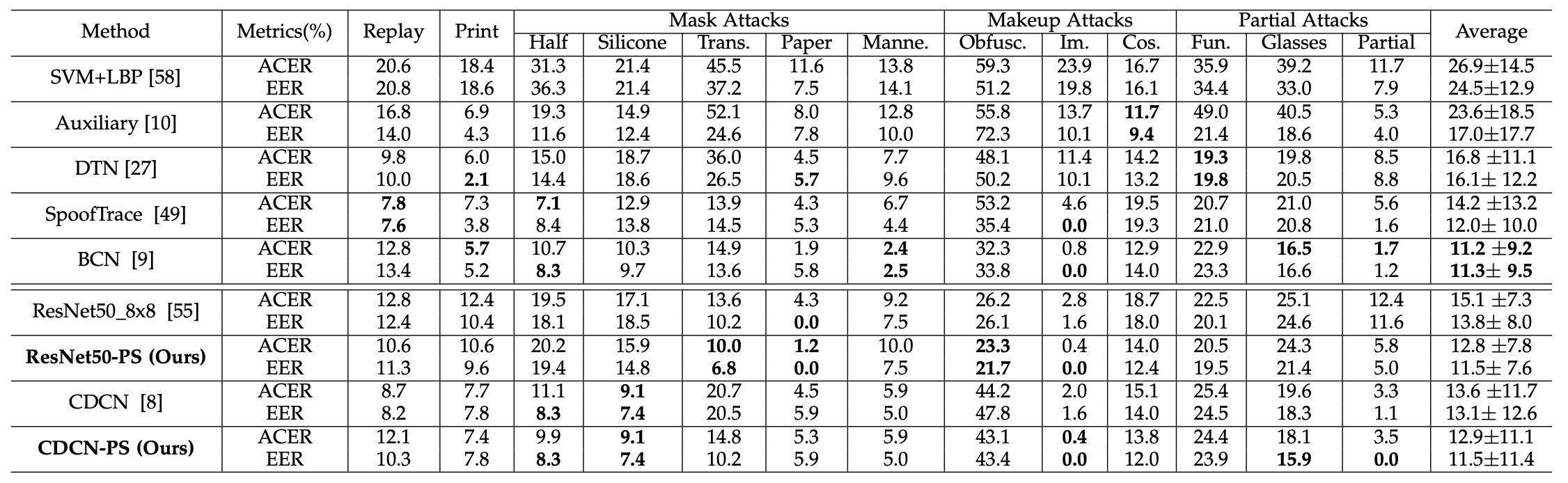
Intra-Dataset Cross-Type Test (SiW-M)
We verify the generalization performance of unknown attacks by cross-type testing with SiW-M. As shown in the table below, compared to traditional Pixel-Wise Supervision, ResNet50-PS and CDCN-PS achieve an overall better EER with 17% and 12% improvement, respectively.
Cross-Dataset Intra-Type Testing
We use four datasets, OULU-NPU (O), CASIA-MFSD (C), Idiap Replay-Attack (I), and MSU-MFSD (M). Out of these, three datasets are randomly selected for training and the remaining one dataset is used for testing. The table below shows the results.
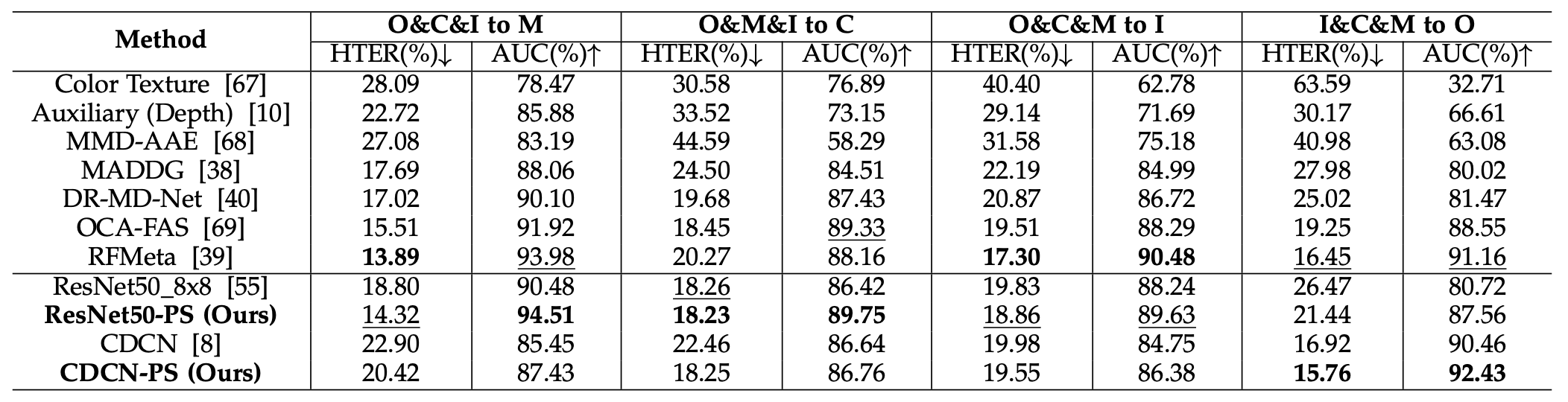
It can be seen that the implementation of Pyramid Supervision significantly improves the performance (HTER) of ResNet50-PS by -4.48% and -5.03%, especially for "O&C & I to M" and "I&C & M to O".
Similarly, CDCN-PS has improved its performance (HTER) in "O & C & I to M", "O & M & I to C", and "I & C & M to O" by -2.48%, -4.21%, and -1.16%, respectively. We show that Pyramid Supervision also helps to provide rich multi-scale guidance on multiple source domains.
visualization
The figure below shows the predicted binary maps for real and fake in the Cross-Type test by SiW-M.
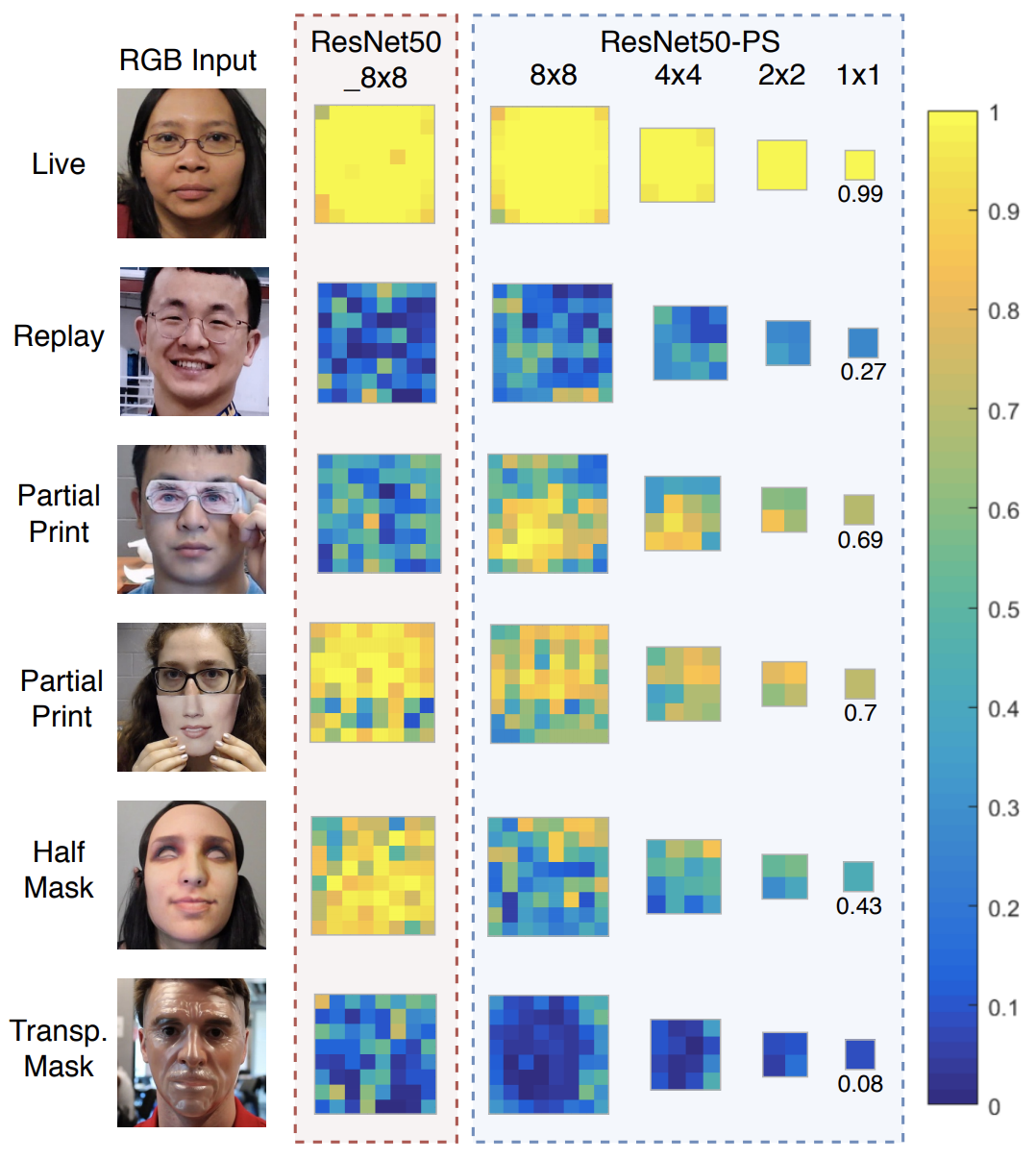
The prediction results for "Live," "Replay," and "Transp. Mask" show that both ResNet50 8x8 and ResNet50-PS perform well and show high confidence in identification. On the other hand, the predictions for unknown attack methods, such as Partial Print and Half Mask, show a decrease in confidence.
From the ResNet50 8x8 results, we can see that in row 3, column 2, in addition to the Print region of the eye region, other facial regions are predicted to have low confidence. On the other hand, the use of Pyramid Supervision significantly improves the interpretability with respect to spoof localization. The predicted 8x8 and 4x4 maps reveal the locations of high (real) and low (fake) scores in the facial skin region and the impersonation medium, respectively.
With the evolution of spoofing attacks, the interpretability of the network will become increasingly important in the localization and understanding of spoofing.
summary
In this paper, we propose a new Pyramid Supervision that provides a richer multi-scale spatial context for fine-grained learning.
It can be easily introduced into traditional methods. Experimental results also show its high effectiveness on both generalization and interpretation performance. High generalization performance and high interpretability are indispensable to realize a safe and secure face recognition system.
In the future, it is expected that the performance will be further improved by incorporating more advanced architectures and pixel-based labels.
To read more,
Please register with AI-SCHOLAR.
OR


Categories related to this article




