The Latest VAE-based Method For Fully Unsupervised Object Detection And Background Segmentation, "SPACE"
3 main points
✔️ Completely unsupervised object detection is possible
✔️ Completely unsupervised and separable for each component of the background
✔️ Potential to be applied to reinforcement learning as a downstream task
SPACE: Unsupervised Object-Oriented Scene Representation via Spatial Attention and Decomposition
written by Zhixuan Lin, Yi-Fu Wu, Skand Vishwanath Peri, Weihao Sun, Gautam Singh, Fei Deng, Jindong Jiang, Sungjin Ahn
(Submitted on 8 Jan 2020 (v1), last revised 15 Mar 2020 (this version, v3))
Comments: In proceeding of ICLR2020
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV); Machine Learning (stat.ML)
overview
In recent years, the field of Object-oriented Representation Learning (OORL) has been the subject of much research*1. Unsupervised object-wise separation in OORL is based on object detection (Spatial Attention-based) using Variational AutoEncoder (VAE) and object-wise separation of images using VAE (Scene Mixture-based).
However, while the object detection base was able to detect and separate foreground objects, it could only be used if the background was known. Also, the per-object separation base had a very blurry separation image and did not work well when there were a large number of foreground objects.
As the title of the paper suggests, SPACE, the latest OORL method introduced here, combines object detection-based (Spatial Attention-based) and object-wise decomposition-based (Scene Mixture-based) techniques to produce a large number of foreground objects that are It also worked in some cases and achieved the separation performance of State of the Art objects.
We also proved that it works effectively in the Atari dataset, which is a standard dataset in reinforcement learning, and we can see its potential for application to reinforcement learning as a downstream task*2.
So let's take a look.
1 OORL is a field of object-focused learning of some kind, but in this article, we will define OORL as a field of object separation.
2 A downstream task refers to task B that utilizes a model to solve task A. For example, object detection falls under a downstream task if the recognition model trained in classifications is used for object detection.
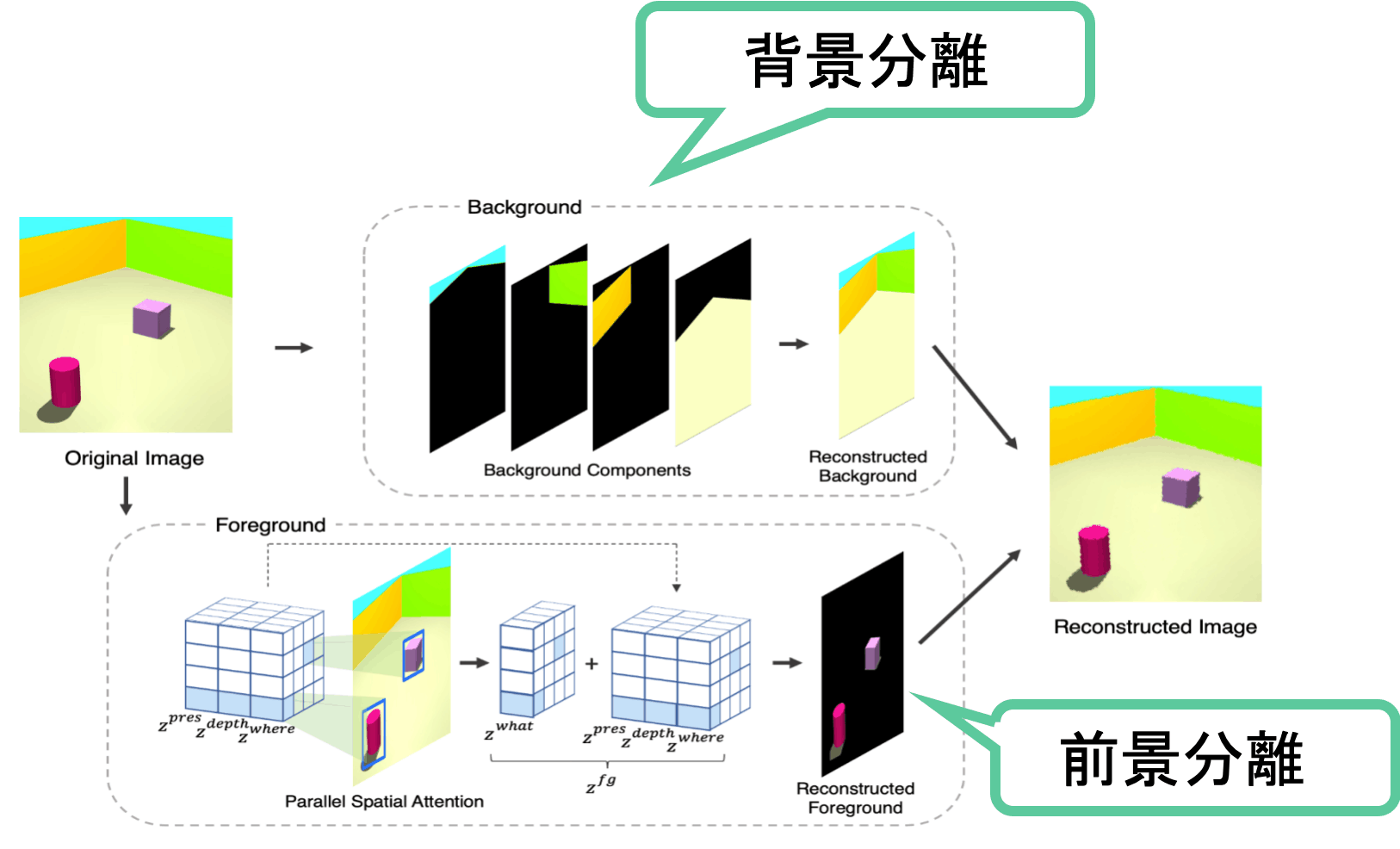
Figure 1: Overview of SPACE.
The main idea and contribution of this paper
Main Idea.
The main idea of this paper is simple. It's a very reasonable idea.
In order to understand this paper, it is necessary to understand VAE and Spatial Attention-based and Scene Mixture-based methods.
3 SPACE has been designed to overcome the sluggishness of the Spatial Attention-based method, but since it is not related to the main idea of SPACE, I will only briefly mention it in this article. If you are interested in the technique, please refer to the article titled Boundary Loss in the SPACE paper.
To read more,
Please register with AI-SCHOLAR.
OR


Categories related to this article
