BERTのfine-tuning不安定性はどのように解決できるか?
3つの要点
✔️ BERT等のTransformerベース事前学習モデルのfine-tuningの不安定性を分析
✔️ 勾配消失による学習初期の最適化の難しさ、一般化の違いを不安定性の原因として特定
✔️ fine-tuningの安定性を高める新たなベースラインを提案
On the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselines
written by Marius Mosbach, Maksym Andriushchenko, Dietrich Klakow
(Submitted on 8 Jun 2020 (v1), last revised 6 Oct 2020 (this version, v2))
Comments: Accepted to ICLR2021.
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)

code:


はじめに
BERTを始めとした、Transformerベースの事前学習モデルは、fine-tuningを行うことで様々なタスクにて優れた性能を発揮できることが示されています。このような優れた性能に反し、BERTのfine-tuningは不安定です。つまり、様々なランダムシードに応じて、タスクの性能に大きなばらつきが生じる可能性があります。
このようなfine-tuningの不安定性の理由として、破局的忘却・データセットサイズの小ささが仮説として挙げられていました。本記事で紹介する論文では、これらの仮説がfine-tuningの不安定性を説明出来ないことを示しました。
さらに、BERT、RoBERTa、ALBERTを解析し、fine-tuningの不安定性が最適化と一般化という二つの側面に起因していることを示しました。加えて、分析結果に基づき、fine-tuningを安定して行うことができる新たなベースラインを提案しました。
実験
データセット
fine-tuningの分析のため、以下に示す四つのデータセットを利用します。
- CoLA(Corpus of Linguistic Acceptability):与えられた文の文法の正誤を識別します。
- MRPC(Microsoft Research Paraphrase Corpus):二つの文が与えられたとき、それらが同義であるかどうかを識別します。
- RTE(Recognizing Textual Entailment:含意関係認識):二つの文が与えられたとき、一方が正しければもう一方も正しいと推論できるかどうかを識別します。
- QNLI(Question-answering Natural Language Inference):質問と文が与えられたとき、文が正しい回答となっているかどうかを識別します(SQuADデータセットの二値分類版)。
データセットの統計は以下の通りです。
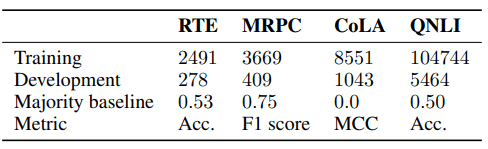
これらはどれもGLUEタスクの中に含まれるベンチマークです。この四つのうち、CoLAはfine-tuningが特に安定していること、RTEは特に不安定であることが過去の研究でわかっています。
・ハイパーパラメータ等の設定
fine-tuning時のハイパーパラメータ・モデル等の設定は以下の通りです。
- モデル:uncased BERT-LARGE(またはRoBERTa-LARGE、ALBERT-LARGE)
- バッチサイズ:16
- 学習率:2e-5(イテレーションの最初の10%で0から2e-5まで線形に増加し、その後0まで線形に減少)
- ドロップアウト率:$p=0.1$(ALBERTでは0)
- 重み減衰(weight decay):$\lambda=0.01$(RoBERTaでは0.1、勾配クリッピングなし)
- optimizer:AdamW(バイアス補正なし)
モデルはLARGEが利用されていますが、これはBERT-BASEのfine-tuning時には不安定性が生じないことによります。
・fine-tuningの安定性について
fine-tuningの安定性は、アルゴリズムのランダム性に対するfine-tuning時の性能(F1スコアや精度など)の標準偏差の大きさをもとに判定されます。
・実行の失敗判定について
訓練終了時の精度が、それぞれのデータセットに対応する多数の分類器の精度以下であった場合、そのfine-tuningは「失敗した」と判定されます。
fine-tuning不安定性の原因の仮説について
以前の研究では、fine-tuningの不安定性の理由として、破局的忘却・データセットサイズの小ささが仮説として提示されていました。
実験では、はじめにこれらの仮説についての検証を行います。
・破局的忘却はfine-tuning不安定性を引き起こすか?
破局的忘却とは、学習済みのモデルを更に別のタスクで学習させた時、以前のタスクに対する性能が低下する現象を指します。この実験の設定では、BERT等の事前学習時におけるタスク(MLMなど)を、fine-tuning後には適切に実行できなくなることに該当します。
この破局的忘却と不安定性との関連性を調べるため、以下のような実験を行います。
- RTEデータセット上でBERTのfine-tuningを行います。
- 学習に成功した試行・失敗した試行それぞれ三つずつ選択します。
- それらについて、WikiText-2言語モデリングベンチマークのテストセットをもとに、MLM(Masked Language Modeling)のperplexityを測定し評価します。
- 24層のうち上位$k$層($0 \leq k \leq 24$)を事前学習モデルと置き換えることで、破局的忘却と不安定性の関連性を調査します。($k=0$のときは全ての層がfine-tuning済みモデル、$k=24$のときは全ての層が事前学習モデルとなります。)
この実験の結果は以下のようになります。
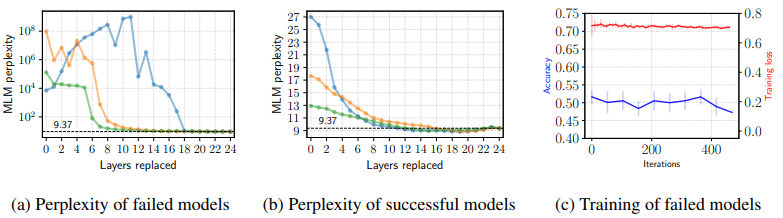
失敗したモデル(左図)では確かに破局的忘却が生じていることがわかります(縦軸の値に注意)。水色を除き、上位10層程度を置き換えるとperplexityが改善されていることから、破局的忘却は上位10層程度が主に影響していると考えられます。また、破局的忘却は通常、新たなタスクに適応することにより生じるはずです。
しかしfine-tuningに失敗した場合は、精度は低いものの、訓練損失はある程度小さく($\simeq -ln(\frac{1}{2})$)なっています(右図)。これは、fine-tuningの失敗が最適化の問題により生じていることを示唆していると論文で指摘されています。
・データセットの小ささはfine-tuning不安定性を引き起こすか?
次に、データセットサイズとfine-tuning不安定性の関係性について調べるため、以下のような実験を行います。
- CoLA、MRPC、QNLIの訓練セットから1000例をランダムにサンプリングします。
- データセットごとに25回、異なるランダムシードを用いてBERTのfine-tuningを行います。
- 通常と同じエポック数(3エポック)学習した場合、通常と同じイテレーション数学習した場合、それぞれの設定で実験し比較します。
この時の結果は以下の通りです。
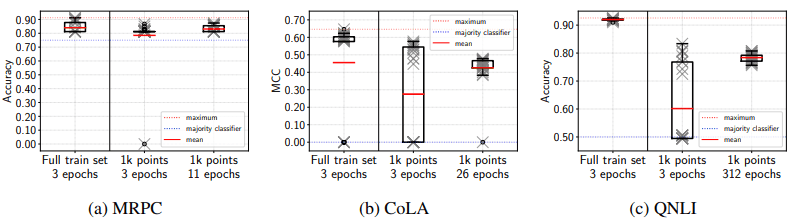
図の通り、通常と同じエポック数学習した場合(1k points 3 epochs)、CoLAやQNLIでは失敗することが多くなり、分散が大きくなります。しかし、イテレーション数を通常と同じにした場合、分散は十分に小さくなっています。また、失敗した試行の回数も、MRPCとQNLIでは0回、CoLAでは1回と抑えられており、完全な訓練セットで学習した場合と同様の安定性を示しています。
このことから、fine-tuningの不安定性は訓練データサイズの不足というより、むしろイテレーション回数の不足に起因していると考えることが出来ます。
fine-tuningの不安定性の原因は何か?
これまでの実験から、破局的忘却とデータセットサイズは、fine-tuningの不安定性と相関はしているものの、その要因とは言い難いことが示されました。以降ではさらに、fine-tuningの不安定性の要因が何なのかについて探っていきます。
具体的には、(i)最適化について、(ii)一般化について、それぞれ調査を行います。
(i)最適化について
・勾配消失問題
fine-tuningに失敗した場合、勾配消失が生じていることを以下に示します。
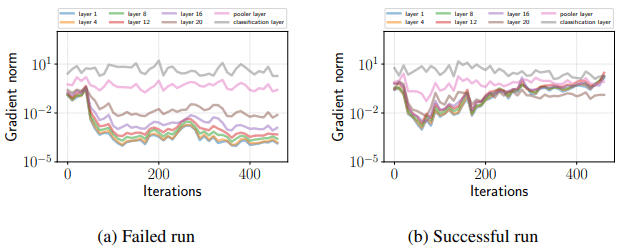
図の通り、失敗した試行では最上層(classification layer)を除き、学習の初期で勾配が非常に小さくなり、そのまま元に戻らないことがわかります。一方成功した試行では、最初の70イテレーション程度は勾配が小さくなっているものの、それ以降では勾配が大きくなっており、勾配消失は起きていません。
また、RoBERTa、ALBERTの場合も、次図の通り同様の勾配消失が発生します。
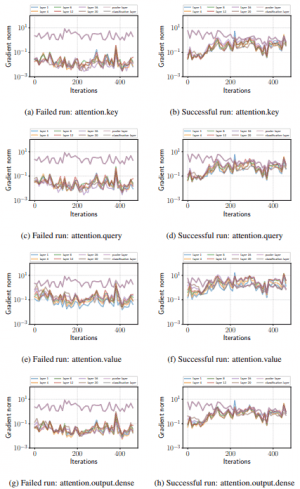
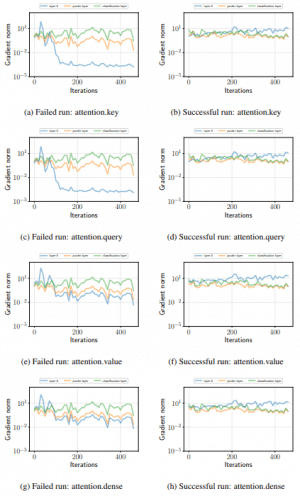
(左:RoBERTa 右:ALBERT)
このことから、fine-tuningの不安定性には、勾配消失のような最適化の失敗が強く関わっていることが予想できます。
・ADAMのバイアス補正
BERTのfine-tuning時にADAMバイアス補正を利用した場合の結果は以下のようになります。
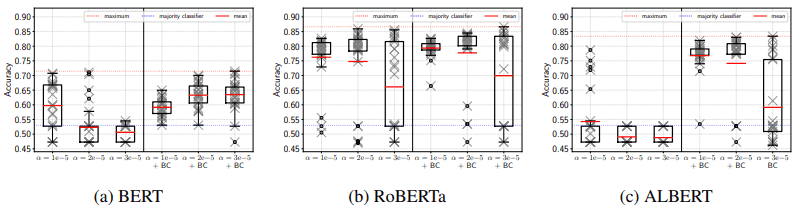
$\alpha$は学習率を、BCはバイアス補正(Bias Correction)を示しています。
図の通り、BERTとALBERTでは大きな性能向上が生じており、RoBERTaでも多少の改善がみられることがわかります。このように、ADAMのバイアス補正はfine-tuning時の性能向上につながることがわかりました。
・損失面の可視化
fine-tuning時の損失を二次元面に可視化したものを以下に示します。
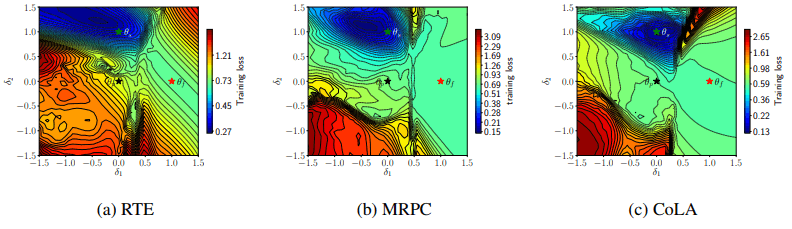
図の$\theta_p,\theta_f,\theta_s$は、それぞれ事前学習モデル、fine-tuningに失敗したモデル、成功したモデルを示しています。線は等高(等値)線を表します。この図を見ると、失敗したモデルは損失が小さい領域(青色部分)に位置しており、成功時や事前学習時とは大きく異なる位置(深い谷のような場所)に収束していることがわかります。
また、勾配ノルムを可視化した場合は以下のようになります。
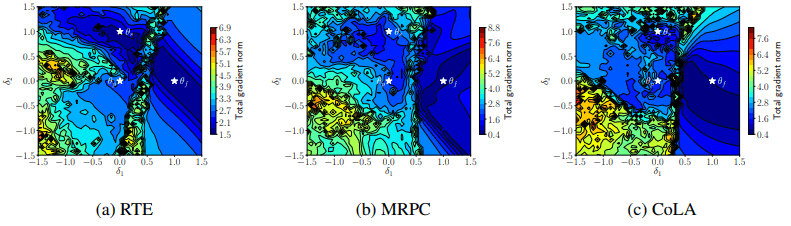
このとき、失敗したモデル$\theta_f$とその他の間に、等高線が密集した山のような障壁が存在しており、これらが分離されている状態になっています(これは三つのデータセット全てで同様になっています)。
これらの結果(勾配消失の確認、ADAMのバイアス補正による性能の向上、損失や勾配の可視化からの定性的分析)から、fine-tuningの不安定性は最適化の失敗によるのではないかと予想することができます。
(ii)一般化について
次に、fine-tuningの不安定性と一般化の関連性に着目します。
はじめに、RTE上でBERTのfine-tuningを行った場合について、成功した試行(10回)のdevelopmentセットに対する精度を以下に示します。
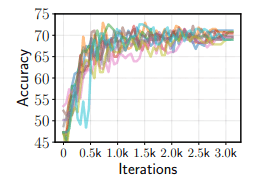
さらに、異なる設定で行われた450回の試行結果について、developmentセットに対する精度と訓練損失は以下のようになりました。
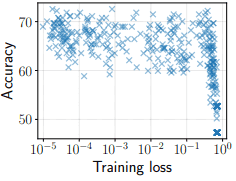
この図のうち、訓練損失が$10^{-5}~10^{-1}$までの範囲で、精度はほぼ変化していません。つまり、fine-tuning時にオーバーフィッティング(訓練データに対する過剰適合)は生じていないことがわかりました。そのため、訓練損失が非常に小さくなるまで(多いイテレーション数で)学習を行ったとしても、オーバーフィッティングによる性能の低下は問題とならないと予想することができます。
安定したfine-tuningのためのシンプルなベースライン
fine-tuningの不安定性と最適化・一般化との関連性についての調査を踏まえると、(小規模なデータセット上での)安定性を高めるための単純な方策として、以下のようなものが考えられます。
- 学習の初期で勾配消失が生じるのを防ぐため、バイアス補正を利用した小さい学習率を用いる
- イテレーション数を大きく増やし、訓練損失がほぼゼロになるよう訓練を行う
これらに従い、以下のようなシンプルなベースラインが提案されました。
- バイアス補正あり、学習率を2e-5に設定したADAMを利用
- 訓練は20エポック行われ、学習率は最初の10%は線形に増加し、以降はゼロに減衰
- その他のハイパーパラメータは変更しない
結果
上記のベースラインに基づいた実行結果は以下の通りです。
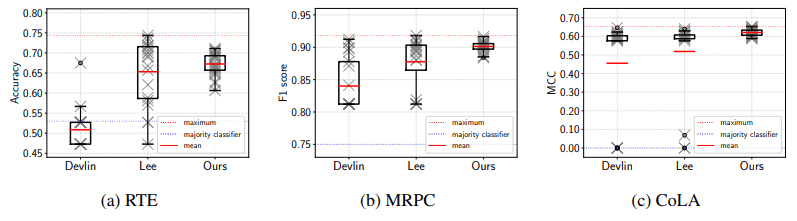
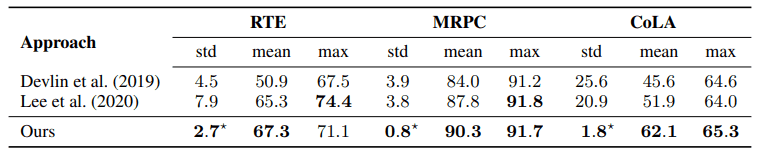
提案手法は、BERT論文で提案されたデフォルト設定、最近の改善手法であるMixoutと比較し、最終的な性能及び標準偏差の面で、より安定したfine-tuningをもたらすことが示されました。
まとめ
本記事で紹介した論文では、BERTのfine-tuningの不安定性が、最適化と一般化という二つの側面に起因していることを示しました。さらに、これらの分析結果に基づき、fine-tuningを安定させるシンプルなベースラインを提案しました。
BERTを始めとしたTransformerベースの事前学習モデルは、非常に優れた性能を発揮しています。これらのモデルのfine-tuningの安定性を高めることは重大な課題です。そのため、fine-tuningの不安定性の原因を分析し、学習を安定させる効果的な手法を示したこの研究は、非常に重要であると言えるでしょう。





この記事に関するカテゴリー






