
FiLMが時系列予測モデルでのノイズ除去と変動検出のトレードオフを解決
3つの要点
✔️ NeurIPS 2022採択論文です。時系列予測の頻出する課題であるノイズと信号の分離について、深層学習手法の特徴を有効に生かしています
✔️ 具体的には、履歴情報を近似するためにレジェンドル多項式投影を適用し、ノイズを除去するためにフーリエ投影を使用し、計算を高速化するために低ランク近似を追加したFiLMを提案しています
✔️ 多変量および単変量の長期予測において、最新モデルの精度をそれぞれ(20.3%、22.6%)大幅に向上しています。他の深層学習モジュールにプラグインとして利用できることも特筆できます
FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting
written by Tian Zhou, Ziqing Ma, Xue wang, Qingsong Wen, Liang Sun, Tao Yao, Wotao Yin, Rong Jin
(Submitted on 18 May 2022 (v1), last revised 16 Sep 2022 (this version, v4))
Comments: Accepted by The Thirty-Sixth Annual Conference on Neural Information Processing Systems (NeurIPS 2022)
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
最近の研究では、RNNやTransformerなどの深層学習モデルは、履歴情報を有効に活用することで、時系列の長期予測に大きな性能向上をもたらすことが示されています。しかし、ニューラルネットワークにおいて、履歴に現れるノイズへのオーバーフィッティングを回避しつつ、履歴情報を保存する方法には、まだ大きな改善の余地があることがわかりました。この問題を解決することで、深層学習モデルの能力をより有効に活用することができます。
この目的のために、この論文では周波数改良型レジェンドル記憶モデル(FiLM:Frequency improved Legendre Memory)を設計しました。これは、履歴情報を近似するためにレジェンドル多項式投影を適用し、ノイズを除去するためにフーリエ投影を使用し、計算を高速化するために低ランク近似を追加するものです。
実証研究によると、提案したFiLMは、多変量および単変量の長期予測において、最新モデルの精度をそれぞれ(20.3%、22.6%)大幅に向上させることが示された。また、本研究で開発した表現モジュールは、他の深層学習モジュールの長期予測性能を向上させるための一般的なプラグインとして利用できることを実証しています。
はじめに
長期予測とは、短期予測とは異なり、将来の長い範囲の履歴に基づいて予測を行うことを指します。長期時系列予測は、エネルギー、気象、経済、交通など、多くの重要なアプリケーションがあります。通常の時系列予測よりも難易度が高いです。課題には、長期の時間依存性、誤差伝播のしやすさ、複雑なパターン、非線形ダイナミクスなどがあります。これらの課題により、ARIMAのような従来の学習方法では、正確な予測が一般的に不可能となります。
RNNのような深層学習法は、時系列予測においてブレークスルーを起こしていますが、Rangapuramら(2018); Salinasら(2020)、Pascanuら(2013)はしばしば勾配消失/爆発などの問題に悩まされており、実用性能が限られています。NLPとCVのコミュニティにおけるTransformer Vaswaniら(2017)の成功に続き、Wenら(2022b)、Zhouら(2022)、Wuら(2021)、Zhouら(2021)では、時系列予測のための長期依存性の捕捉で有望な性能を示しています。
正確な予測を実現するために、多くの深層学習研究者たちは、重要で複雑な歴史的情報を捉えることを期待して、モデルの複雑さを増しています。しかし、これらの方法では、目的を達成することができていません。Fig. 1は、実世界のETTm1データセットのグランドトゥルース時系列と、バニラトランスフォーマーモデルVaswaniら(2017)およびLSTMモデルHochreiter & Schmidhuber(1997a)の予測値を比較しています。予測値がグランドトゥルースの分布から完全に外れていることがわかります。このような誤差は、これらのモデルが真の信号を保存しようとする一方でノイズを誤捕捉していることに由来すると考えます。
著者らは、正確な予測における2つの鍵があると結論付けています:
1)重要な過去の情報をできるだけ完全に捕捉する方法
2)ノイズを効果的に除去する方法
したがって、予測の脱線を避けるためには、単にモデルを複雑化することで改善することはできず、その代わりに、Wenら(2022a)の時系列の重要なパターンをノイズなく捉えることができるロバストな表現を考えることにしました。
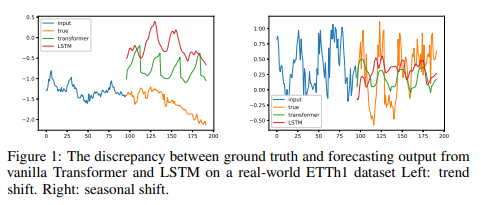
この観察は、長期時系列予測から長期配列圧縮に視点を切り替える動機となりました。再帰的記憶モデルは関数近似タスクで印象的な結果を達成しています。Legendre投影を用いた再帰的記憶装置(LMU)は、長い時系列に対して良好な表現を提供しています。S4モデルは、データ表現のための別の再帰的メモリ設計を考え出し、長距離予測ベンチマーク(LRA)の最先端結果を大幅に改善しました。しかし、長期時系列予測になると、これらのアプローチはTransformerベースの手法の最先端性能に及んでいません。
注意深く検証すると、Fig.2で明らかになったように、これらのデータ圧縮法は、LSTM/Transformerモデルと比較して、過去データの詳細を回復するのに強力であることがわかります。しかし、過去のすべてのスパイクをオーバーフィットする傾向があるため、ノイズの多い信号には弱く、長期的な予測性能に限界があることがわかります。LMPで採用されているLegendre Polynomialsは、直交多項式(OPs)ファミリーの中の特別なケースに過ぎないことは注目に値します。OP(Legendre、Laguerre、Chebyshevなどを含む)および他の直交基底(FourierおよびMultiwavelets)は、数多くの分野で広く研究されており、最近では深層学習で適用されました。
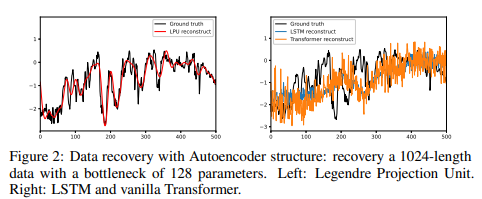
以上の観察から、将来予測、特に長期予測のために、時系列データを正確かつ頑健に表現する手法を開発することが必要であることがわかりました。提案手法は、それらの表現を強力な予測モデルと統合することで、複数のベンチマークデータセットにおいて、既存の長期予測手法を大幅に上回る性能を発揮します。
この目標に向けた最初のステップとして、LMU Voelkerら(2019)が固定サイズのベクトルを持つ時系列の表現を動的に更新するために用いているLegendre投影を直接利用します。そして、この投影層をさまざまな深層学習モジュールと組み合わせて、予測性能を向上させます。この表現を直接利用する際の主な課題は、情報の保存とデータのオーバーフィッティングの間のジレンマであり、すなわち、Legendre投影の数が大きくなるほど、過去のデータは保存されるが、ノイズの多いデータはオーバーフィッティングされやすくなることです。
そこで、第二段階として、ノイズの多い信号がLegendre投影に与える影響を軽減するために、フーリエ解析と低ランク行列近似を組み合わせた次元削減のレイヤーを導入します。具体的には、レジェンドル射影から大きな次元の表現を残し、過去のデータの重要な詳細がすべて保存されるようにします。次に、フーリエ解析と低ランク近似を組み合わせて、低周波のフーリエ成分に関連する表現の部分と、ノイズの影響を除去するための上位固有空間を残すように適用します。
したがって、長期の時間依存性を捉えるだけでなく、長期予測におけるノイズを効果的に低減することができます。著者らは、提案手法を長期時系列予測のためのFrequency improved Legendre Memory model、略してFiLMと名付けました。
本研究の主要な貢献は以下のようにまとめられます:
1. ロバストなマルチスケール時系列特徴抽出のために、専門家の混合による周波数改善レジェンドル記憶モデル(FiLM)アーキテクチャを提案する
2. レジェンド投影ユニット(LPU)を再設計し、時系列予測モデルが履歴情報保存問題を解決するために利用できるデータ表現のための一般的なツールにする
3. フーリエ解析と低ランク行列近似を組み合わせて次元を削減し、時系列からのノイズ信号の影響を最小化し、オーバーフィッティング問題を緩和する周波数拡張レイヤー(FEL)を提案する
4. 複数のドメイン(エネルギー、交通、経済、天候、病気)にまたがる6つのベンチマークデータセットで大規模な実験を行う。
実証研究の結果、提案モデルは多変量予測、単変量予測において、それぞれ19.2%、26.1%最新手法の性能を向上させることがわかりました。さらに、実証研究により、次元削減による計算効率の劇的な向上も明らかにしました。
Legendre-Fourier領域における時系列表現
Legendre 投影
レジェンド多項式投影を用いると、長時間のデータ列を有界次元の部分空間に投影することができ、進化する履歴データの圧縮、あるいは特徴表現につながります。形式的には、オンラインで観測された滑らかな関数fが与えられたとき、その履歴![]() の固定サイズの圧縮表現を維持することを目的とし、ここでθはウィンドウサイズを指定します。各時点tにおいて、近似関数g(t)(x)は、尺度
の固定サイズの圧縮表現を維持することを目的とし、ここでθはウィンドウサイズを指定します。各時点tにおいて、近似関数g(t)(x)は、尺度![]() に関して定義されています。本論文では、関数g(t)(x)を構築するために、最大でN 1次のレジェンド多項式を使用します。
に関して定義されています。本論文では、関数g(t)(x)を構築するために、最大でN 1次のレジェンド多項式を使用します。
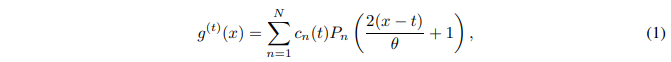
ここで、Pn(・)はn次のLegendre 多項式です。係数cn(t)は以下の動的方程式で捉えられます:
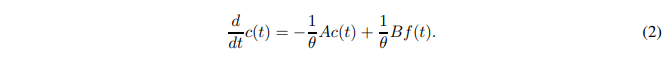
ここで、A と B の定義は Voelker et al. (2019) に記載されています。基底としてLegendre多項式を使うことで、以下の定理で示されるように、滑らかな関数を正確に近似することができます。
・定理1
f (x)がL-Lipschitzであれば、
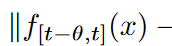
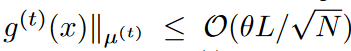
となる。さらに、f (x) がk次の有界導関数を持つ場合、
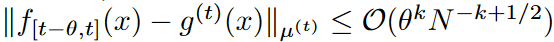
となる。
定理1によれば、当然のことながら、レジェンドル多項式の基底数が多いほど近似精度が高くなり、残念ながら履歴のノイズ信号のオーバーフィッティングにつながる可能性があります。前記のように、MLP、RNN、バニラアテンションなどの深層学習モジュールに上記の特徴をそのまま与えても、主に履歴のノイズ信号が原因で、最先端の性能は得られません。そのため、次に、特徴選択のためにフーリエ変換を用いたFrequency Enhanced Layerを導入します。
・定理2
Aをユニタリー行列、![]() を2サブガウス型ランダムノイズとする。
を2サブガウス型ランダムノイズとする。
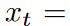
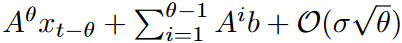
とする。
フーリエ変換
ホワイトノイズは完全にフラットなパワースペクトルを持つため、時系列データは特定のスペクトルの偏りを享受していると一般的に考えられており、スペクトル全体では一般的にランダムに分布しているわけではありません。確率的な遷移環境のため、予測タスクの実際の出力軌道は大きな揮発性を含み、人々は通常、それらの平均経路を予測するだけです。そのため、比較的滑らかな解が好まれます。
式(1)によれば、近似関数g(t)(x)は、係数cn(t)をtとnの両方で平滑化することにより安定化することができます。この観察は、データ駆動で係数cn(t)を調整する効率の良い方法を設計するのに役立ちます。nの平滑化は各チャンネルに学習可能なスカラーを乗算することで簡単に実装できるので、ここでは主にフーリエ変換によるtのcn(t)の平滑化を議論します。
スペクトルの偏りは、cn(t)のスペクトルが主に低周波領域に位置し、高周波領域での信号強度が弱いことを意味します。解析を簡単にするために、cn(t)のフーリエ係数をan(t)と仮定することにします。スペクトルバイアスにつき、すべてのnについて![]() を満たすようなs, amin > 0が存在すると仮定します。係数をサンプリングするアイデアとして、完全にランダムなサンプリング戦略の代わりに、最初のk次元を維持し、残りの次元をランダムにサンプリングすることが挙げられます。著者らは、以下の定理によって近似品質を特徴付けます:
を満たすようなs, amin > 0が存在すると仮定します。係数をサンプリングするアイデアとして、完全にランダムなサンプリング戦略の代わりに、最初のk次元を維持し、残りの次元をランダムにサンプリングすることが挙げられます。著者らは、以下の定理によって近似品質を特徴付けます:
・定理3
![]() を入力行列
を入力行列![]() のフーリエ係数行列とし、行列Aのコヒーレンス尺度であるμ(A)をΩ(k/n)とする。Aの最後のd-s列の要素がaminより小さくなるようなsと正のaminが存在すると仮定する。最初のs列を選択したまま、残りの部分からO(k2/ε2 -s)列をランダムに選択すると、高確率で
のフーリエ係数行列とし、行列Aのコヒーレンス尺度であるμ(A)をΩ(k/n)とする。Aの最後のd-s列の要素がaminより小さくなるようなsと正のaminが存在すると仮定する。最初のs列を選択したまま、残りの部分からO(k2/ε2 -s)列をランダムに選択すると、高確率で
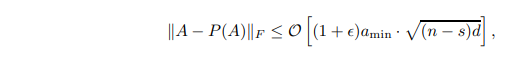
ここで、P(A)は、Aを列選択列空間に投影した行列を表す。
定理3は、aminが十分に小さいとき、選択された空間は元の空間とほとんど同じとみなすことができることを意味しています。
モデル構造
FiLM: Frequency improved Legendre Memory Model
FiLMの全体構造をFig. 3に示します。 FiLMは、![]() というシーケンスを主に2つのサブレイヤーを利用することでマッピングします。ここで
というシーケンスを主に2つのサブレイヤーを利用することでマッピングします。ここで![]() 。すなわち、 LPU(Legendre Projection Unit)層とFEL(Fourier Enhanced Layer)層の2つのサブレイヤーを主に利用します。また、異なるスケールの履歴情報を取り込むため、LPU層には異なるスケールの専門家が混在して実装されています。オプションのアドオンデータ正規化層RevIN Kim et al.(2021)が導入され、モデルの頑健性をさらに高めています。FiLMは、LPUとFELのそれぞれ1層のみのシンプルなモデルです。
。すなわち、 LPU(Legendre Projection Unit)層とFEL(Fourier Enhanced Layer)層の2つのサブレイヤーを主に利用します。また、異なるスケールの履歴情報を取り込むため、LPU層には異なるスケールの専門家が混在して実装されています。オプションのアドオンデータ正規化層RevIN Kim et al.(2021)が導入され、モデルの頑健性をさらに高めています。FiLMは、LPUとFELのそれぞれ1層のみのシンプルなモデルです。
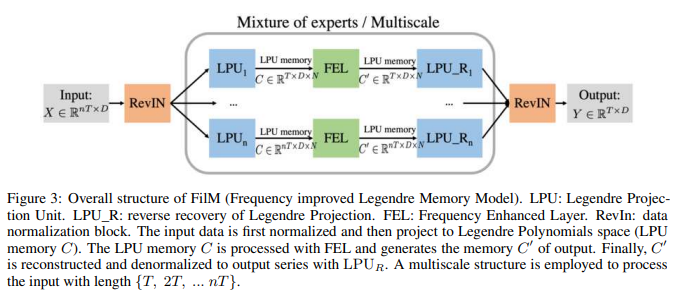
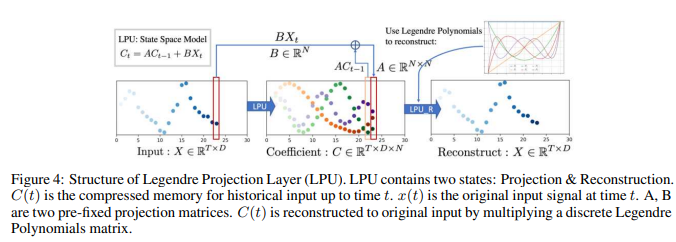
LPU: Legendre Projection Unit
LPUは状態空間モデルです: Ct = ACt-1 + Bxt、ここで![]() は入力信号、
は入力信号、![]() はメモリユニット、Nはレジェンド多項式の数です。LPUは、以下のように定義された2つの訓練不可能な前置行列AおよびBを含みます:
はメモリユニット、Nはレジェンド多項式の数です。LPUは、以下のように定義された2つの訓練不可能な前置行列AおよびBを含みます:
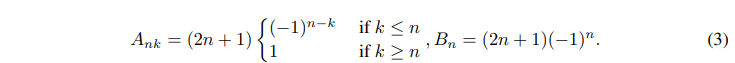
LPUには、投影と再構成という2つのステージがあります。前者のステージでは、元の信号をメモリユニットに投影する: C=LPU(X)となります。後段は、メモリユニットから信号を再構成します: Xre = LPU_R(C)。入力信号がメモリCへ/メモリCから投影/再構成される全体のプロセスを、Fig. 4に示します。
FEL: Frequency Enhanced Layer
・低位近似
FELは、データから学習するのに必要な、単一の学習可能な重み行列(![]() )を持っています。しかし、この重みは大きくなる可能性があります。Wを3つの行列
)を持っています。しかし、この重みは大きくなる可能性があります。Wを3つの行列![]() ,
, ![]() に分解して低ランク近似(N '<< N )することができます。レジェンド多項式数N = 256をデフォルトとすると、本モデルの学習可能な重みはN' =4で0.4%と大幅に減少し、精度の劣化は少ないです。計算の仕組みはFig. 5に示す通りです。
に分解して低ランク近似(N '<< N )することができます。レジェンド多項式数N = 256をデフォルトとすると、本モデルの学習可能な重みはN' =4で0.4%と大幅に減少し、精度の劣化は少ないです。計算の仕組みはFig. 5に示す通りです。
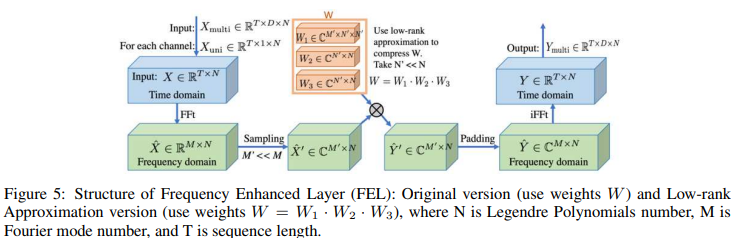
・モード選択
ノイズを減らし、トレーニング速度を高めるために、フーリエ変換後に周波数モードのサブセットを選択します。デフォルトの選択方針は、最も低いMモードを選択します。実験では、様々な選択方針を検討しました。その結果、いくつかのデータセットにおいて、ランダムな高周波数モードを追加することで、さらなる改善が得られることが示されました(定理3における理論的研究により裏付けられた)。
マルチスケールエキスパートの混合メカニズム
マルチスケール現象は、時系列予測に特有の重要なデータの偏りです。著者らは、履歴シーケンスのポイントを一様に重要視しているので、本論文のモデルはそのような事前分布を欠いているかもしれません。このモデルは、Fig. 3に示すように、様々な時間地平{T, 2T, ... nT}を持つ入力シーケンスを利用して、予測地平Tを予測し、各エキスパート予測を線形層でマージする単純な混合エキスパート戦略を実装しました。このメカニズムにより、Table 7に示すように、すべてのデータセットで一貫してモデルの性能が向上しました。
データ正規化
Wu et al. (2021); Zhou et al. (2022)が指摘するように、時系列の季節トレンド分解は、長期時系列予測において重要なデータ正規化デザインです。著者らは、このLMU投影が、ほとんどのデータセットにおいて、本質的に正規化の役割を果たすことができることを見つけたが、明確な正規化設計がないため、場合によっては、性能の頑健性を損なうことがあります。単純な可逆的インスタンス正規化(RevIN)Kimら(2021)は、アドオンの説明的なデータ正規化ブロックとして機能するように適応されます。平均と標準偏差は、![]() と
と![]() 。x(i) を
。x(i) を![]() として入力データのすべてのインスタンス
として入力データのすべてのインスタンス![]() について計算されます。
について計算されます。
そして、正規化された入力データは、予測のためにモデルに送られます。最後に、最初に行った正規化の逆数を適用することで、モデル出力を非正規化します。
RevINは学習プロセスを2~5倍遅らせるが、RevInを適用することですべてのデータセットで一貫した改善が観察されるわけでもありません。したがって、RevInはモデル学習におけるオプションのスタビライザーとみなすことができます。その詳細な性能は、Table 7の切り分け研究において示されています。
実験
FiLMを評価するために、交通、エネルギー、経済、天候、病気など、長期予測に人気のある実世界の6つのベンチマークデータセットで大規模な実験を行いました。著者らは主に5つの最先端の(SOTA)Transformerベースのモデル、すなわち、 FEDformer、Autoformer Wuら(2021)、Informer Zhouら(2021)、LogTrans Liら(2019)、Reformer Kitaevら(2020)、再帰的メモリを持つ最近の状態空間モデルS4 Guら(2021a)を比較対象にします。FEDformerは、ほとんどの設定でSOTAの結果を達成するため、主なベースラインとして選択されています。
主要結果
より良い比較のために、Informer Zhouら(2021)の実験設定に従って、入力長を最良の予測性能になるように調整し、訓練と評価の両方の予測長をそれぞれ96、192、336、720に固定しました。
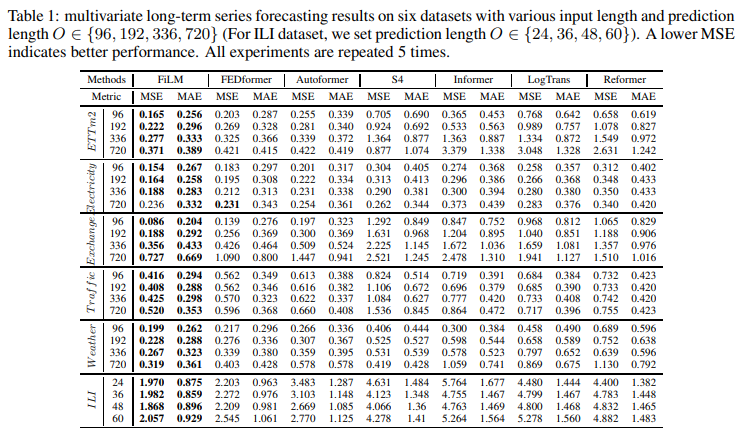
・多変量
多変量予測タスクでは、Table 1に示すように、FiLMは6つのベンチマークデータセットすべてにおいて、すべての範囲において最高の性能を達成しました。SOTA作品(FEDformer)と比較して、提案するFiLMは、全体として20.3%の相対的なMSEの削減をもたらすことができました。注目すべきは、Exchangeのようないくつかのデータセットでは、さらに大きな改善が見られたことです(30%以上)。Exchangeデータセットでは、明らかな周期性は見られないが、FiLMは依然として優れた性能を達成しています。FiLMによる改善は、様々な水平軸で一貫しており、長期予測におけるFiLMの強みを示しています。
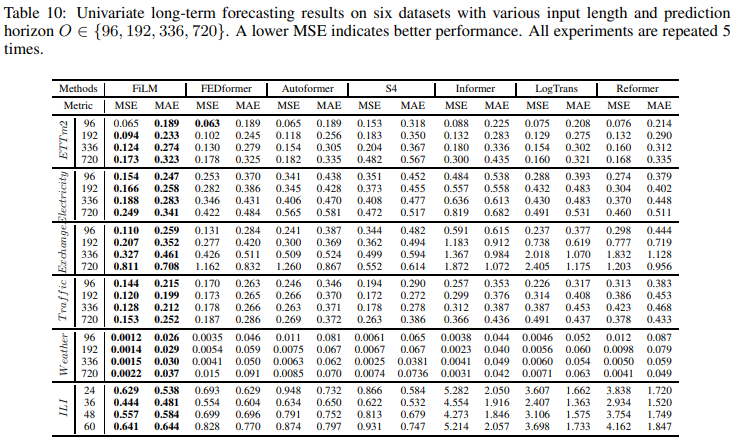
・単変量
単変量時系列予測のベンチマーク結果は、Table 10にまとめられています。SOTA作品(FEDformer)と比較して、FiLMは全体として22.6%の相対的なMSEの削減を実現しました。また、天候や電気需要のようないくつかのデータセットでは、40%以上の改善に達することができました。これは、長期予測におけるFiLMの有効性を再び証明するものです。
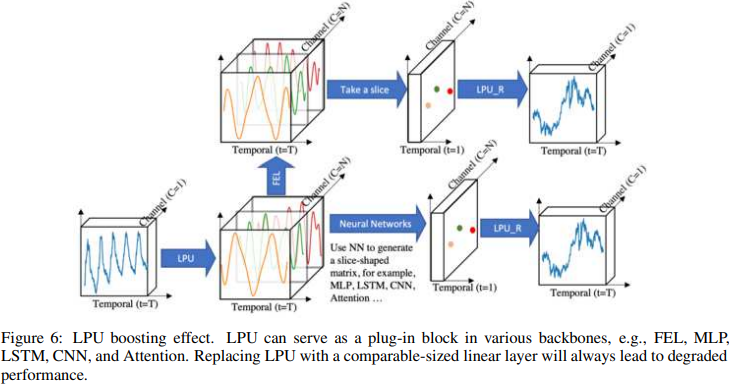
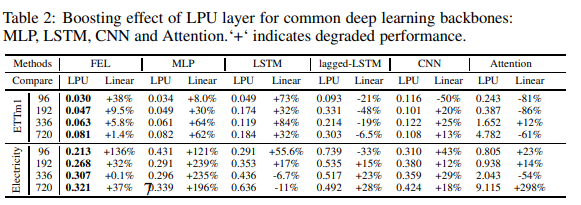
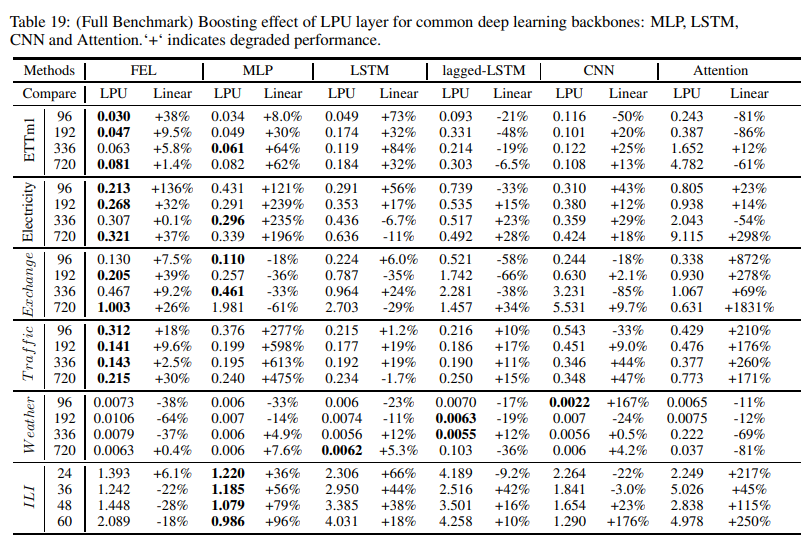
・LPUブースティング結果
Fig. 6に示すように、LPUを様々な一般的な深層学習モジュール(MLP、LSTM、CNN、Attention)と組み合わせた場合のブースト効果を測定するために、一連の実験が実施されました。この実験では、LPUと同サイズの線形層を比較しています。LPUには学習可能なパラメータが含まれていないことは特筆に値する。結果はTable 19に示す通りです。すべてのモジュールにおいて、LPUは長期予測における平均性能を大幅に向上させました: mlp: 119.4%, lstm: 97.0%, cnn: 13.8%, Attention: 8.2%です。Vanilla AttentionはLPUを組み合わせた場合、相対的にパフォーマンスが低下しており、さらに掘り下げる価値があります。
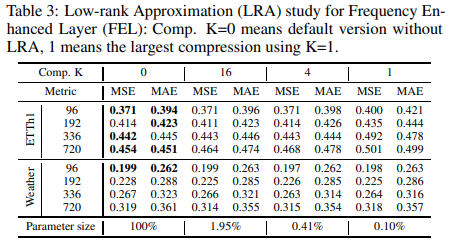
・FELの低位近似
周波数拡張層で学習可能な行列を低ランクで近似することで、わずかな精度劣化でパラメータサイズを0.1%⇠0.4%に大幅に削減できます。実験の詳細はTable 3に示す通りです。Transformerベースのベースラインと比較して、FiLMは学習可能なパラメータを80%削減し、メモリ使用量を50%削減することができます。
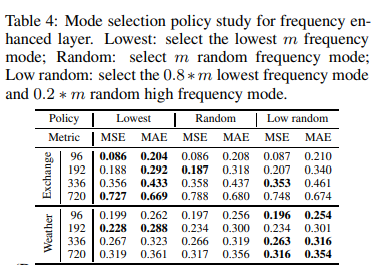
・FELのモード選択方針
周波数モード選択方針はTable 4で検討しました。Lowestモード選択法は、最も頑健な性能を示します。Low randomの列の結果は、定理3での理論的研究が裏付けるように、いくつかの高周波信号をランダムに追加することで、いくつかのデータセットで特別な改善が得られることを示しています。
切り分け分析
ここでは、採用した2つの主要ブロック(FEL & LPU)の切り分け研究、マルチスケール機構、およびデータの正規化(RevIN)について紹介します。
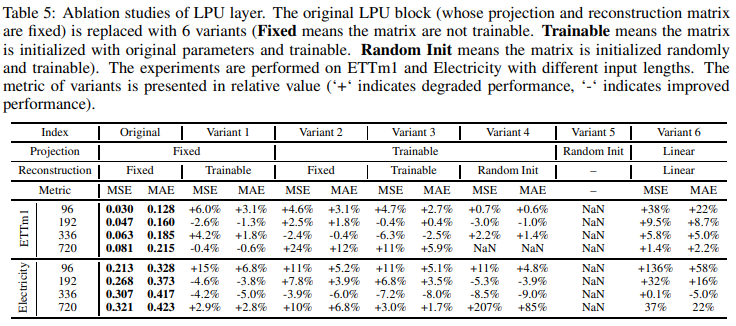
・LPUの切り分け
LPU層の有効性を証明するために、Table 5では、オリジナルのLPU層と6つのバリエーションを比較しています。LPU層は、2組の行列(投影行列と再構成行列)から構成されています。それぞれ3つのバリエーションがあります: 固定、訓練可能、ランダムイニシャルの3種類です。
バリエーション6では、LPUレイヤーを置き換えるために、同等の大きさの線形レイヤーを使用します。変形6では、平均32.5%の劣化をもたらし、Legendre投影の有効性を確認することができました。LPUの射影行列は、N回再帰的に呼び出されます(Nは入力の長さです)。そのため、射影行列をランダムに初期化した場合(変形5)、出力は指数関数的な爆発という問題に直面することになります。投影行列が学習可能な場合(変形2、3、4)、モデルも同様に指数関数爆発に悩まされるため、小さな学習率で学習する必要があり、学習速度が遅く、収束までに多くのエポックを要します。このように、速度と性能のトレードオフを考慮すると、学習可能な投影バージョンは推奨されません。学習可能な再構成行列を持つ変形版(変形1)は、同等の性能を持ち、収束の難易度も低いです。
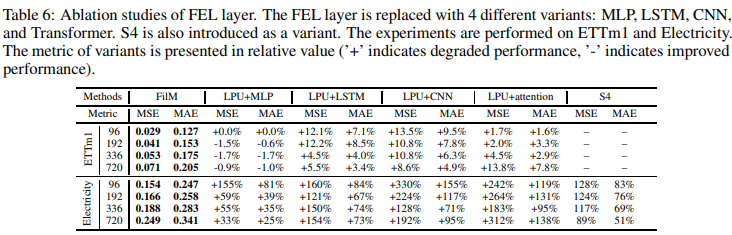
・FELの切り分け
FELの有効性を証明するために、FELを複数の変種(MLP、LSTM、CNN、Transformer)に置き換えています。また、S4はLegendre投影メモリを搭載したバージョンもあるため、変種として導入しました。実験結果はTable 6にまとめられています。FELは、LSTN、CNN、Attentionと比較して最高の性能を達成しました。MLPは、入力長が192、336、720の場合に同等の性能を発揮します。しかし、MLPはメモリ使用量がN 2L(FELはN 2)であり、耐えられないという問題があります。S4では、LPU+MLPと同様の結果を得ることができました。また、LPU+CNNは最も悪い結果となりました。
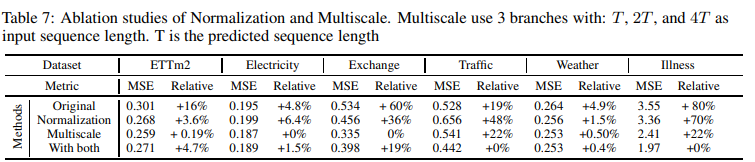
・マルチスケールとデータ正規化 (RevIN)の切り分け
マルチスケールモジュールは、すべてのデータセットで一貫して大きな改善をもたらします。しかし、データ正規化によって、「交通」と「病気」については性能が向上したが、それ以外についてはわずかな改善にとどまるという、複雑な性能が確認されました。RevINデータ正規化とマルチスケールエキスパートの混合を採用したアブレーション研究をTable 7に示します。
まとめ
長期予測では、正確で頑健な予測を行うために、履歴情報の保存とノイズ除去のトレードオフが重要な課題となっています。この課題に対処するため、著者らは、履歴情報を正確に保存し、ノイズ信号を除去する周波数改良型レジェンドルメモリモデル(FiLM)を提案しました。さらに、本モデルで採用したレジェンドルとフーリエの投影の有効性を理論的・実証的に証明しました。
広範な実験により、提案モデルが6つのベンチマークデータセットでSOTA精度を大幅に向上させることが示されました。特に、提案のフレームワークはかなり一般的であり、将来の研究において長期予測のためのビルディングブロックとして使用できるのは重要です。また、異なるシナリオのために修正することも可能です。例えば、Legendre Projection Unitは、Fourier、Wavelets、Laguerre Polynomials、Chebyshev Polynomialsなどの他の直交関数に置き換えることができます。
また、ノイズの特性に基づき、Fourier Enhanced Layerが本フレームワークの最良の候補の1つであることが証明されました。著者らは、今後、このフレームワークのさらなる変形を検討する予定としています。




この記事に関するカテゴリー






