
気配りのある特徴値融合メカニズムで時系列予測するTSDFNet
3つの要点
✔️ 時系列予測では、精度を上げるためにはドメインナレッジにより注目する特徴量を設定することが求められ多くの労力を必要としました。
✔️ TSDFNetでは、自己分解機構と気配りのある特徴量融合メカニズムを用いて、特徴量エンジニアリングを行うことなく、重要な特徴量を抽出します。
✔️ 十数種類のデータセットで検証したところ、Seq2Seq, LSTM-SAEなど従来手法と比べ際立って優れた予測性能を確認することができました。
Temporal Spatial Decomposition and Fusion Network for Time Series Forecasting
written by Liwang Zhou, Jing Gao
(Submitted on 6 Oct 2022)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
時系列予測でより良い結果を得るためには、特徴量エンジニアリングが必要であり、分解はその重要な一つです。ところが標準的な時系列分解は柔軟性と頑健性に欠けるため、1つの分解アプローチでは多くの予測タスクに使用できないことが多いです。従来の特徴量の選択は、既存のドメイン知識に大きく依存し、汎用的な方法論がなく、多くの労力を必要とします。しかし、深層学習に基づく時系列予測モデルの多くは、一般的に解釈可能性の問題に悩まされており、「ブラックボックス」のような結果は信頼感を得られません。上記の問題に対処することが、本論文の動機です。本論文では、自己分解機構と気配りのある特徴量融合機構を備えたニューラルネットワークとしてTSDFNetを提案します。これは、前処理慣習としての特徴量エンジニアリングを放棄し、深層学習モデルとの内部モジュールとして創造的に統合するものです。自己分解機構は、TSDFNetにあらゆる時系列に対する拡張可能で適応的な分解能力を与え、ユーザーは独自の基底関数を選択して時系列と一般化された空間次元に分解することができます。気配りのある特徴量融合メカニズムは、外部変数の重要性とターゲット変数との因果関係を捕らえる能力を備えています。また、重要でない素性を自動的に抑制し、有効な素性を強化することができるため、ユーザが素性の選択に苦労することはありません。さらに、TSDFNetは特徴の可視化によりディープニューラルネットワークの「ブラックボックス」を覗き、予測結果を分析することが容易です。十数種類のデータセットで既存の広く受け入れられているモデルよりも性能が向上していることを実証し、3つの実験でTSDFNetの解釈可能性を示しています。
はじめに
時系列予測は、経済、金融、交通、気象 などの多くの分野で重要な役割を担っており、人々にチャンスを予見する力を与え、意思決定の指針となります。そのため、時系列モデルの汎用性を高め、性能を維持しながらモデリングの複雑性を低減することが重要です。時系列予測の分野では、多変数・多段階の予測は最も困難な課題の一つを形成しています。現在のところ、多変量・多段階の時系列予測の問題を扱う普遍的な方法はありません。そのため、データ分析者は専門的な背景知識(ドメインナレッジ)を持つ必要があります。
特徴量工学は、通常、モデリングを行う前にデータを前処理するために用いられます。特徴量工学の分野では、時系列分解は複雑な時系列を予測可能な多数の部分系列に分解する古典的な方法であり、季節・トレンド分解のSTL 、アンサンブル経験モード分解のEEMD、経験ウェーブレット変換のEWT などに代表されます。さらに、特徴の選択も重要なステップです。複雑なタスクでは、通常、ターゲット変数の予測を補助するために、いくつかの補助変数が必要となります。冗長な追加特徴の導入は、モデルの性能を低下させる可能性があるため、追加特徴の合理的な選択は、モデルの性能にとって極めて重要です。
冗長な追加特徴の導入は、モデルの性能を低下させる可能性があるからです。また、適切な分解方法と重要な追加特徴をどのように選択するかは、データ解析者にとって困難な問題です。
一方で、数多くのモデルが提唱されているにもかかわらず、それぞれに欠点があります。深層学習ベースのモデルの大半は、理解が難しく、納得のいかない予測結果をもたらします。しかし、ARIMAやxgboostのように、健全な数学的基盤を持ち、解釈可能性を提供するモデルは、性能面で深層学習ベースのモデルに太刀打ちできません。
そのため、従来の慣習を打破し、これらの問題を処理するための新しい方法を考案する必要があります。本研究では、自己分解機構と気配りのある特徴融合機構に基づき、TSDFNetと呼ばれる新しいニューラルネットワークモデルを開発しました。分解と特徴選択は深層モデルの内部モジュールとして統合され、複雑さを軽減し適応性を高めています。データの高次統計的特徴は、このモデルのロバストな特徴表現能力によって捉えられる可能性があり、様々な領域のデータセットに適用可能です。
要約すると、貢献度は以下の通りです。
- 時間分解ネットワーク(Temporal Decomposition Network: TDN)は、時系列を時間軸上で分解し、ユーザが特定のタスクのために基底関数をカスタマイズできる拡張性と適応性を持つネットワークである。
- 空間分解ネットワーク(Spatial Decomposition Network: SDN)は、高次元の外部特徴を分解基底関数として利用し、外部変数と対象変数の関係をモデル化するものである。
- また、特徴量の自動選択機能を持ち、特徴量の重要度や因果関係を捉えることができる Attentive Feature Fusion Network (AFFN)を提案した。これにより、ユーザは特徴選択の手間を省くことができ、無効な特徴の導入によるモデル性能の低下を心配することなく、任意の基底関数を自己分解ネットワークに利用することができる。
- TSDFNetは多方面のデータセットに対して解釈可能な結果を得ており、多くの従来モデルと比較して大幅に性能が向上している。
関連研究
時系列予測の分野は歴史が古く、多くの優れたモデルが開発されてきました。最もよく知られた従来の方法には、ARIMAや指数平滑化があります。ARIMAモデルは、差分によって非定常過程を定常過程に変え、さらに多変量時系列予測の問題に対処するためにVAR へと拡張することができ、その解釈可能性と使いやすさが人気の主な理由となっています。もう一つの有効な予測手法として、指数平滑化があります。これは、時間の経過とともに指数関数的に減少する重みをデータに与えることによって、一変量時系列を平滑化するものです。
時系列予測は基本的に回帰問題であるため、様々な回帰モデルを利用することも可能である。決定木やサポートベクトル回帰(SVR)などの機械学習ベースの手法もあります。
さらに、複数の学習アルゴリズムを採用し、構成する学習アルゴリズムのいずれか1つだけで達成されるよりも優れた予測性能を実現するアンサンブル手法も、配列予測に有効なツールです。このような手法の例として、ランダムフォレストやadaptive lifting algorithm (Adaboost) などがあります。
近年、ディープラーニングが普及し、ニューラルネットワークは多くの分野で成果を上げています。これは、バックプロパゲーションアルゴリズムを用いて、ネットワークパラメータを最適化するものです。LSTM(Long Short-Term Memory)とその派生系は、シーケンシャルなデータで大きな力を発揮し、RNN(Recurrent Neural Network)の勾配消失の欠点を克服し、長期的依存性をよりよくとらえることができます。Deep autoregressive network (DeepAR) はスタック型LSTMを用いて反復的な多段階予測を行い、Deep state-space Models (DSSM) も同様のアプローチで、あらかじめ定義された線形状態空間モデルのパラメータ生成にLSTMを利用するものです。Seq2Seq (Sequence to Sequence) は通常、エンコーダーとデコーダーとして一対のLSTMまたはGRU を使用します。エンコーダは入力データを隠れ空間に固定長の意味ベクトルにマッピングし、デコーダは文脈ベクトルを読み、段階的にターゲット変数を予測しようとします。また、時間畳み込みネットワーク(TCN)は、シーケンス予測問題に効果的に適用することができ、一般的なRNNファミリーの手法の代替手段として使用することができ、RNNベースのモデルと比較してより高速でより少ないパラメータを持っています。
因果的な畳み込みや残差接続を用いたRNNベースのモデルに比べて、高速でパラメータが少ないです。アテンションメカニズムは、エンコーダーデコーダーベースの改良として登場し、さらにTransfomerモデルの中核として自己注意メカニズムに容易に拡張できます。
手法
このネットワークのアーキテクチャをFig. 1 に示す。これは2つの主要な部分からなり、1つ目はTDNとSDNを含む自己分解ネットワークです。特徴量融合ネットワーク(AFFN)が追加要素です。
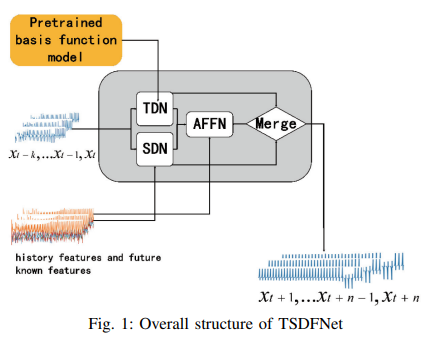
A. 自己分解ネットワーク
自己分解ネットワークの構造は、2つの分解モジュールを含んでいます。1つは時間分解ネットワークTDNで、時間次元でシーケンスを分解するためにカスタム基底関数を採用します。もう一つは空間分解ネットワークSDNであり、外生的特徴を基本関数として、一般化された空間次元でシーケンスを分解します。主な目的は、複雑なシーケンスを単純で予測可能なシーケンスに分解することです。
TDNは、三角基底、多項式基底、ウェーブレット基底など、異なるパラメータで事前に学習した複数の基底関数を用いて、信号の特徴を捉えることができます。
TDN のアーキテクチャをFig. 2 に示します。TDNにはN個の再帰的分解ユニットが存在します。(n+1)番目のユニットは、それぞれの入力Xnを入力として受け入れ、2つの中間成分WnとVnを出力します。各分解ユニットは2つの部分からなり、スタック型完全連結ネットワークLsはデータを隠れ空間にマッピングして意味ベクトルSnを生成し、2組の完全連結ネットワークLpとLqを通して基底展開係数をそれぞれ前方と後方へ予測する。という流れになります。
手順は次の通りです。
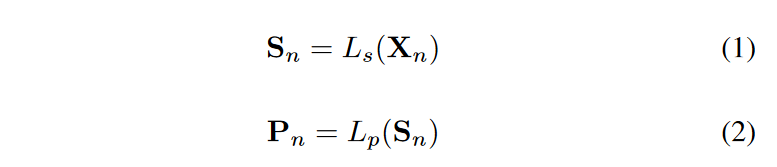
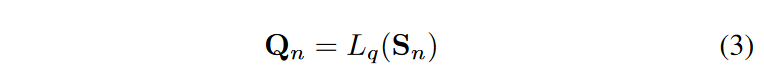
もうひとつは、事前に学習された基底関数モデル群です。これは、-w/L から h/L までの線形空間上で定義された時間ベクトル t = [-w, -w + 1, ...0, h -1, h]/L の関数です。ここで、L = w + h + 1,wはドライブシーケンスの時間履歴窓長、hはターゲットシーケンスの時間窓長です。この時間ベクトルは異なる事前学習されたモデルに供給され、Cn = [sin(-kt), cos(-kt), ..., cos(kt), sin(kt)] で定義される異なる周波数を持つ三角関数、Cn = [t, t2, t3...tk] で定義される異なる次数の多項式関数など、複数の基底関数にマッピングされます。Cn は t = [-w/L...0] のときの Cpn と t = [0...h/L] のときの Cpn に分けられ、それぞれ過去と未来のデータの適合に使われます。それらの係数行列PnとQnは、各基底関数の重要度を決定します。
- n番目のブロックの最終出力は次のように定義されます。

- 次のブロックへの入力は次のように定義されます。

- 原信号X0=[xt-w,xt-w+1・・・,xt-1]は逆方向特徴成分Wnを除去し続け、理想的には残差は特徴情報を持たなくなったランダムノイズになります。

- 各分解ユニットの順方向出力は以下のように積算され、TDN出力となります。

- モデルのハイパーパラメータNは分解層の数として定義され、選択した基底関数の種類に依存し、各基底関数に対して繰り返し可能です。これらの基底関数ネットワークの重みは、多様なシナリオに適応するために、異なるタスクに対してもう一度調整することができます。

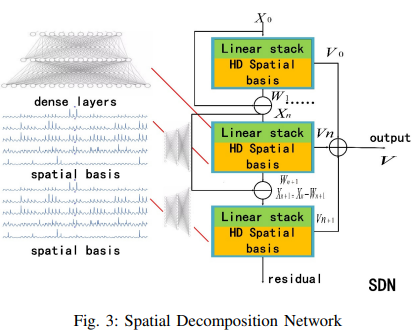
- Fig. 3に空間分解ネットワーク(Spatial Decomposition Network:SDN)を示します。その構造はTDNと同様です。違いは、SDNは高次元にマッピングされた外部特徴を基底ベクトルCpn、Cqnとして採用している点です。詳細は以下の通りです。

- ここで、Epは過去の追加特徴量、Eqは未来の追加特徴量です。Lnはスタック型完全連結モジュールで、過去の付加機能と未来の付加機能をそれぞれ高次元に写像します。いくつかの離散特徴を変換するために埋め込みを採用し、欠落した特徴を埋めるために0を用います。さらに、自己分解モジュールが一変量時系列を扱うための柔軟性を提供することに注目することが重要です。空間分解ネットワーク(SDN)のモジュールは、無効にすることができ、あるいは、SDNを有効にして、EMDなどの他の手法の特徴コンポーネントを入力として受け入れることもできます。
B. 気配りのある特徴融合ネットワーク
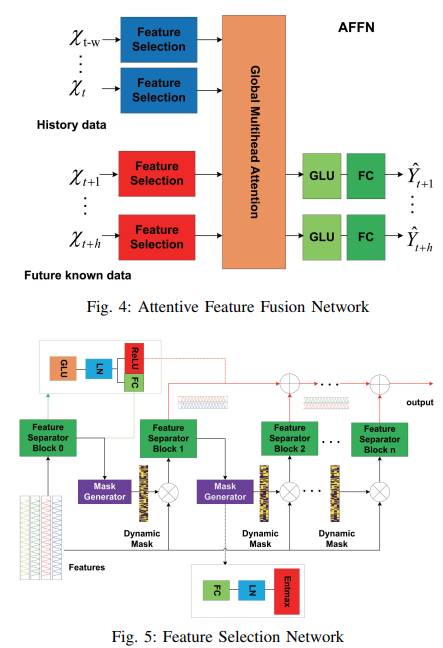
Fig. 4に示すように、特徴選択モジュールはインスタンス単位の変数選択を行うように設計され、決定ユニットのグループは無関係な特徴を繰り返し抑制し、マルチヘッドアテンションブロックは特徴選択モジュールの結果を入力として受け入れ、さらにグローバルな関係をモデル化します。最後に、出力は GLU と FC によって各時間ステップで得られるが、ここで GLU は入力データの無効な部分を抑制しようとします。
Fig. 5 に示すように、マスク生成器と特徴分離器を含む特徴選 択ブロックを設計しました。
学習可能なマスク生成器は、各次元特徴の重要度を示す説明可能性を持つ動的マスクMを生成するために採用されます。決定ステップjのマスクは、ステップj - 1で分離された特徴を入力として受け取ります。Mj = entmax(h(aj-1), h は学習可能な関数、entmax は従来のソフトマックスと同様、ベクトルを疎な確率に対応付ける能力を持ちます。一連の基底関数特徴は、Mによってフィルタリングすることができ、Mj=0の場合、このステップでの特徴入力がこのサンプルとして予測タスクに無関係であることを意味し、フィルタリングされた特徴M - Xは次の決定ステップに供給されます。一般に、どの特徴がターゲット変数に対してより多くの貢献をしているかに興味があります。データセットのバッチサイズを B、時間の長さを T、決定ステップを J とすると、重要度分布は次式で求められます。
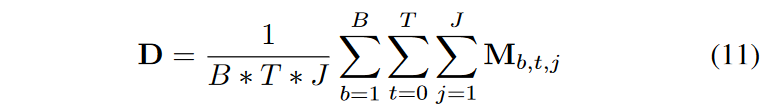
特徴分離器には共有層があり、GLU, LNで構成されています。Layer normalization (LN) は、中間層の分布を正規化する技術です。特徴分離器の共有層 s の出力は、2つの部分 [s1, s2] に分けられ、そのうちの1つ f1(s1) はマスク生成器の入力として、もう1つの f2(s2) はj番目のレベルの決定の出力として使用され、f1 は FC層、f2 は Relu、もし s2 < 0 ならそれは現在の決定出力への寄与はありません。
マルチプルアテンションは良く知られているように以下の通りです。
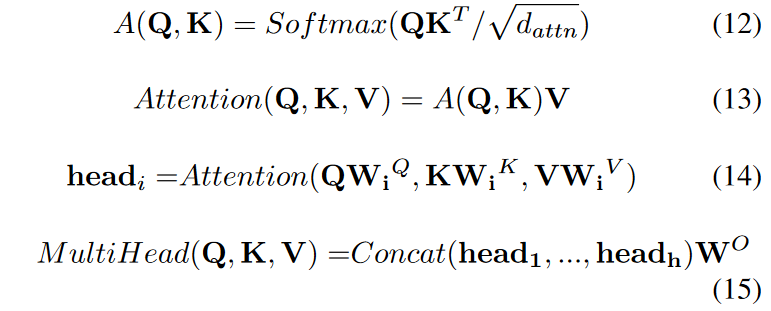
このうち、MultiHead(Q, K, V)はアテンション関数を表します。Softmaxは確率分布関数で、特徴をスケールで正規化するためのパラメータdattn、Kはある時間セグメントのキー、Vは特徴の値です。Q は入力のクエリ特徴量、WO はネットワーク出力の重みです。このモデルはセルフアテンションメカニズムを用いて、様々な時間における各特徴間の相関を学習します。ある対象の要素のクエリに対して、クエリQとKの類似度を計算することで対象に対する各キーの重み係数を求め、対象の重み付け和を行い、最終的なアテンション値を求めます。モデルを複数のヘッドに分割し、異なる部分空間を形成することで、特徴の異なる側面に注目することができます。このモデルでは、Qは特徴選択モジュールから出力される全ての履歴情報の高次元特徴であり、KとVは将来の既知情報の高次元特徴です。
実験
提案したTSDFNetを評価するために、因果畳み込みに基づくTCN、CNNとRNNに基づくLstnet、アテンションとLSTMに基づくSeq2Seq、積層オートエンコーダーに基づくLstm-SAE などの典型的なモデルを選び、様々なタイプのデータセットで徹底的に比較しました。
A. 実装
実験はUbuntuシステムでPytorchフレームワークを使用しています。ハードウェア構成は、Intel(R) Core(TM) I7-6800K CPU @ 3.40 GHZ、64 GBメモリ、GeForce GTX 1080 GPUです。
まず、パラメータkが異なる複数の合成基底関数を構築し、三角関数や多項式関数など、yi = Ci(kt)のモデルに多様性を与えます。これらのモデルは、L2損失で学習した3層完全連結ネットワークです。各データセットには10000学習サンプル、学習期間は100、実験でのバッチサイズは40に設定されています。
第二段階は,ADAMオプティマイザーを用いて,初期学習率0.0001でTSDFNetを学習させます。ドロップアウト率はより良い汎化のために0.1に設定され、バッチサイズは32に設定されています。オーバーフィッティングを避けるため、早期停止を採用し、10エポック以内に損失劣化がなければ学習プロセスを終了させています。評価指標は RAE と SMAPE です。
B. 単変量時系列予測と結果分析
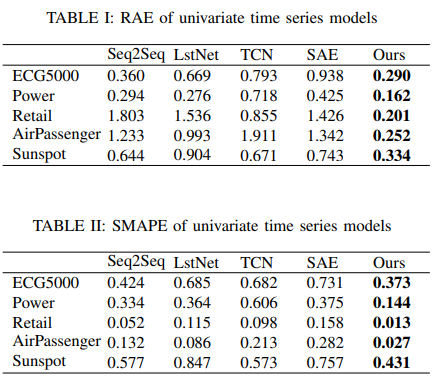
代表的な5つのデータセットの単変量解析結果をTable IとTable IIに列挙します。心電図やエネルギー消費は準周期的であるため、不確実性の山と谷を予測することは困難です。小売店の売上高や航空旅客数のデータでは、学習サンプルが少ないため、周期や傾向を確実に予測することができないのが難点です。一方、太陽黒点の噴火は周期的ですが、時間軸が極めて長いため予測は不可能です。
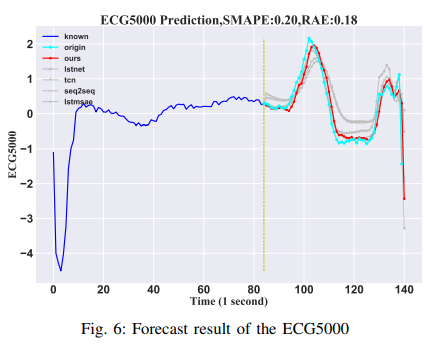
・ECG5000
UCRの時系列データから、学習用4500サンプル、テスト用500サンプルの合計5000個の心電図(ECG)がデータセットとして構成されます。シーケンスの各サンプルは140タイムポイントです。この実験では、最初の84個の時間ステップを入力として使用し、最後の56個の時間ステップを結果として予測します。結果はFig. 6に示す通りです。
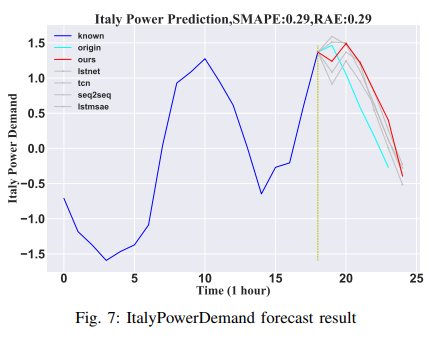
・イタリアの電力需要
データセットはイタリアの電力需要の12ヶ月の時系列から得られたものです。1029個のサンプルが学習された後、67個のサンプルが評価されました。各セットには合計24個のサンプルがあります。この実験では、最初の18時間のデータが、その後の6時間のデータを予測するための入力として利用されます。その結果をFig. 7 に示します。
・小売業
Kaggleのデータセットでは、1992年1月1日から2016年5月1日までのアメリカの月別小売売上高データを提供しています。合計293個のサンプルがあります。本論文では、データの95%をトレーニングセット、5%をテストセットとして使用しました。次の6ヶ月のデータを予測するために、過去12ヶ月のデータを入力として使用しました。その結果をFig. 8に示します。
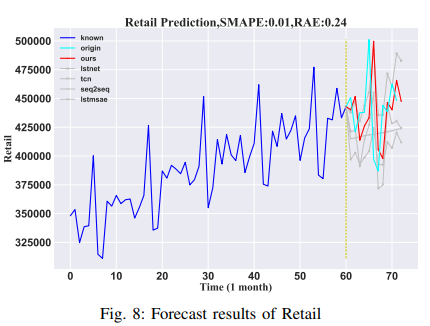
・航空乗客
このデータセットでは、1949年から1960年までのアメリカン航空の外国航空会社における月別の乗客数を提供しています。サンプル数は全部で144です。トレーニングセットは1949年から1959年までのデータ、テストセットは1960年からのデータで構成されています。入力データは60ヶ月にわたるものであり、12ヶ月の予測がなされています。その結果をFig. 9に示します。
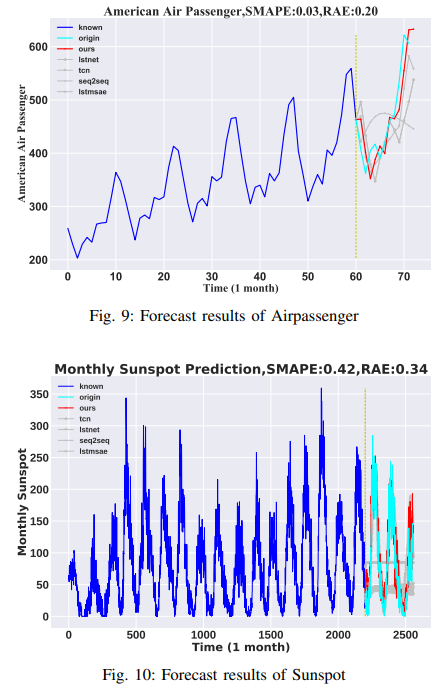
・太陽黒点
データセットは、月別の太陽黒点観測データ(1749-2019)からなり、2820 サンプルです。95%をトレーニングセットとして、最後の5%をテストセットとして使用しました。入力データの長さは2200ヶ月で、360ヶ月分の将来データを予測します。その結果をFig. 10に示します。
C. 多変量時系列
代表的な5つのデータセットの多変量解析の結果をTable IIIとTable IVに示します。気象データセット、交通データセット、実際の観測から得られた風速データセット、そして2つの人工ローレンツデータセットが多変数データセットの例です。これらの多変数データは典型的なカオス系であることが多く、一変量データよりも複雑であるため、予測に役立つ特徴を追加することが必要です。この問題をより効果的に示すため、Lorenz flalign(full length align)では、関連するパラメータを統計的に調整できるLorenzデータセットを作成しました。気象データセットのターゲット変数である気温は、様々なモード周期を持ち、多数の追加要因に影響されるため、モデルの解釈可能性を実証するのに適した選択となりました。交通データセットと風速データセットの不確実性が非常に高いため、風速や他の観測所からの平均車速など、予測に役立つ将来の既知の要素を採用する必要があります。他のモデルも将来の既知の要素を含んでいるが、結果は劣悪であり、この研究のモデルが空間情報の特徴を強く理解していることを実証しています。
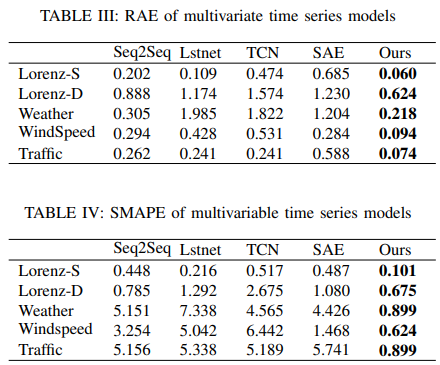
・天気予報
2006年から2016年にわたるデータセットをKaggleから入手しました。この実験の気温予測は、湿度、風速、風向、視界、雲量、気圧など、他の変数に依存します。データには、時間ごとに分割された合計96453個のサンプルが含まれていました。データの95%はトレーニングに、5%はテストに利用されました。モデルは、最初の2200時間のデータを使って、次の360時間の温度を外部特徴量で予測しました。その結果をFig. 11に示します。
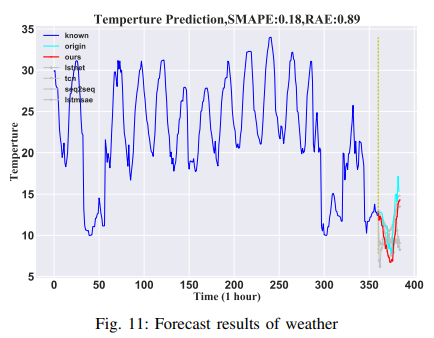
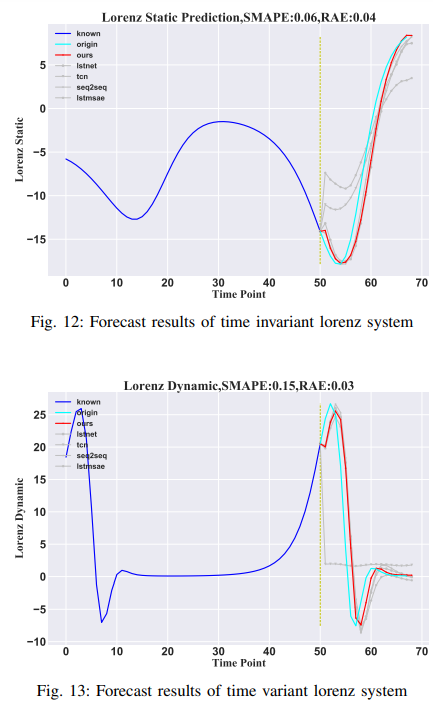
・ローレンツ
ここで、G(-)はX(t) = (xt1, ..., xt90)′のローレンツ系の非線形関数セット、Pはパラメータ・ベクトルです。本論文では、時変系と時不変系で説明したモデルの区別を示すために、時不変ローレンツ系と時変ローレンツ系をそれぞれテストしました。時不変ローレンツ系(Lorenz-S)では、Pは時間的に変化しないが、時間変化する 系(Lorenz-D)では、Pは変化します。実験シミュレーションでは、5000個のサンプルが生成され、最初の90%のデータがトレーニングセットとして、最後の10%がテストセットとして利用されました。実験結果は、この論文で紹介したモデルが、時間変動システムでも時間不変システムでも有効に機能することを示します。その結果をFig. 12とFig. 13に示します。
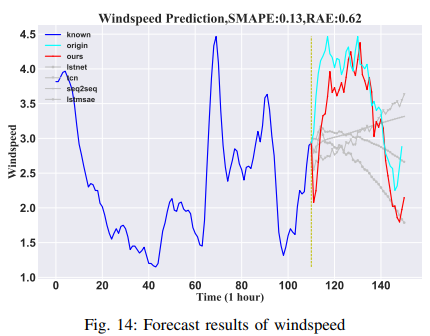
・風速
このデータセットは、気象庁が提供する稚内の155観測点の高次元(155次元)風速データです。10分ごとに、合計138,600分記録されています。この論文では、既知の110分の継続時間を用いて、その後の40分の風速を推定しています。他の154地点のデータは追加機能として使用され、155地点のうちの1地点の目標風速がランダムに選ばれました。風速の予測は非常に困難であると考えられているが、この手法では、風速の予測結果が非常に優れています。風速の予測は非常に難しいとされているが、この手法は他の手法よりも優れた結果を予測することができます。その結果をFig. 14に示します。
・交通量
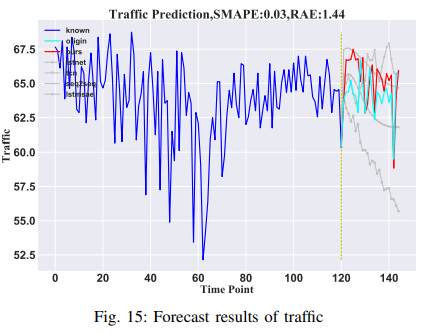
平均車速(MPH)は、ロサンゼルスの国道134号線沿いの207個のループ検知器のデータを用いて予測し、各検知器の観測値は個別の変数として扱われます。最初の120時間は、24時間の平均速度を予測するために利用されます。高次元データから、1つのセンサーからのデータがターゲット変数として選ばれ、他のセンサーからの観測値は補助的な特徴として使用されます。これは、空間データを予測するモデルの能力を示しています。その結果をFig. 15に示します。
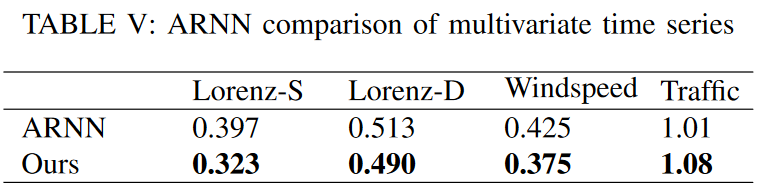
よりよい比較のために、論文を再現する代わりに、ARNN (Automatic Reserve Pool Neural Network) の実験結果をそのまま踏襲し、ローレンツ、風速、交通のデータセットで、RMSEを指標としてテストしました。その結果をTable Vに示します。TSDFNetがシングルステップの予測問題でも良好な性能を発揮することを示すために、大気品質データセットでLSTM-SAEと比較します。予測対象は2010年から2014年までのPM2.5濃度であり、このモデルはRMSEの大幅な削減(24→15)を達成しました。その結果はFig. 16に示されています。
D. 議論
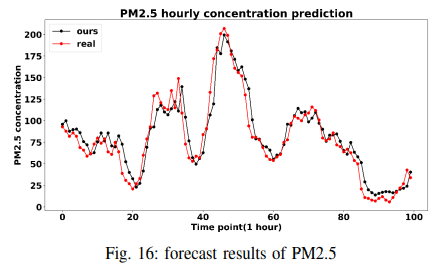
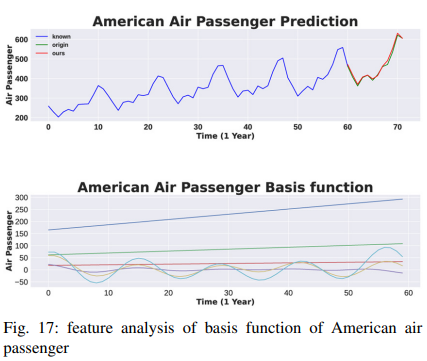
TSDFNetの性能上の利点を確立した後、このモデル設計により、その特定のコンポーネントを分析して、モデルが学習した一般的な関係を説明することができることを示します。まず、式(4)で記述されるTDNの解釈可能な変種を分析することで、特徴の重要性を定量化します。航空旅客データセットは定常ではなく、季節性とトレンドが混在しています。これは、年々増加し、月ごとに頻繁に変化します。結果はFig. 17に示されており、図の上段には元の信号とその予測が、2段目には基底関数が表示されています。
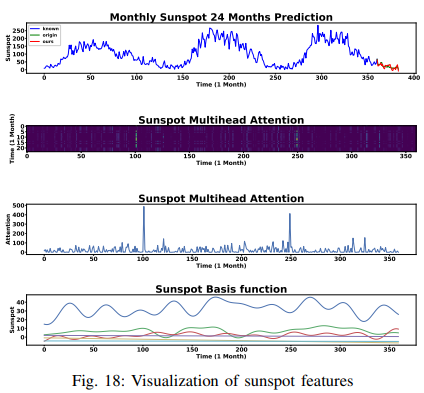
黒点データセットの結果はFig. 18に示されています。図の上段はいかに季節性があるかを示し、下段は微調整された三角法基底関数によって周期性がいかにうまく捕捉されたかを示しています。さらに、TSDFNetが推論に基づく決定的瞬間を強調する注目度重みパターンも、かなり参考になるかもしれません。2行目には、暗い背景の中に間隔をあけてたくさんの鮮やかな縞模様が見えます。これらは新しいサイクルの開始を表しています。3行目に示すように、各時間ステップの選択重みを集約すると、注目のスパイクが太陽黒点の谷に一致することがわかります。
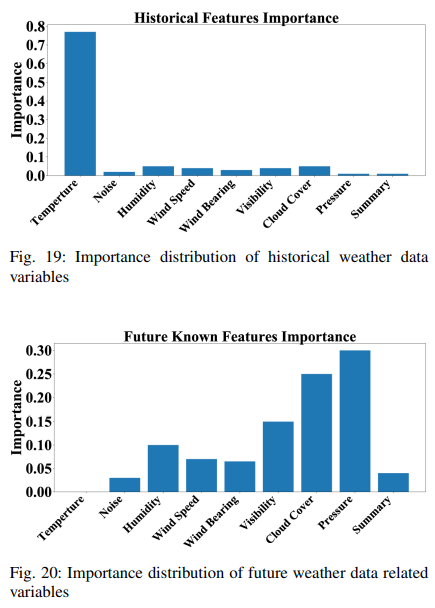
さらに、各特徴の重要度は、(11)で決定されるように、特徴選択ブロックの決定重みパターン また、(11)により決定された各特徴の重要度は、特徴選 択ブロックの決定重みパターンを用いて検討することができます。履歴データの他の特徴成分も考慮しながら、履歴特徴の重要度分布をFig. 19に示します。過去の温度データが将来の温度データの重要度の75%程度を占めていることがわかります。今後の既知データの重要度分布はFig. 20に描かれています。予測の精度は、将来の気圧と雲の厚さに大きく依存することがわかります。また、将来の気温データは知ることができず、0という値で埋められるため、結果への寄与は0です。また、我々のモデルがいかに重要でない変数を排除しうるかを示すため、ガウスノイズを入力として使用します。ガウスノイズの寄与は、関連する情報を持たないので最小です。
まとめ
本論文では、特徴量エンジニアリングをモデリングに取り入れ、驚異的なパフォーマンスを達成した新しい解釈可能な深層学習モデルであるTemporal Spatial Decomposition Fusion Network (TSDFNet) を紹介しました。TSDFNetは、時系列の長期予測問題を扱うために特別なコンポーネントを利用しています。Temporal Decomposition Network(TDN)は、時系列分解の固有モードとして任意の基底関数をカスタマイズできます。Spatial Decomposition Network(SDN)はシーケンス分解のための基底関数として外部特徴を用います。Adentive Feature Fusion Network(AFFN)はすべての入力特徴を融合し、最も重要な特徴を選択します。最後に、広範な実験により、TSDFNetが様々な有名なアルゴリズムと比較して、一貫して最先端の性能をもたらすことが実証されています。



この記事に関するカテゴリー






