
CNNのカーネルサイズは大きくするべきか?
3つの要点
✔️ 31x31もの大規模なカーネルを利用したCNNアーキテクチャを提案
✔️ Depth-Wise畳み込みの利用をはじめとした5つのガイドラインによりカーネルの大規模化に成功
✔️ 事前学習済みモデルの下流タスク転移性能で優れた結果を発揮
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
written by Xiaohan Ding, Xiangyu Zhang, Yizhuang Zhou, Jungong Han, Guiguang Ding, Jian Sun
(Submitted on 1 Jul 2021)
Comments: CVPR2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
一般的な畳み込みニューラルネットワーク(CNN)では、3×3のような小さなカーネルを積み重ねることで大きな受容野を構築しています。
一方、最近大きな発展を遂げているVision Transformers(ViT)では、Multi-Head Self-Sttention(MHSA)により、単一の層のみでも大きな受容野が実現されています。
こうしたViTの成功を鑑みると、多数の小さなカーネルで大きな受容野を実現する既存のCNNの方針の代わりに、少数の大きなカーネルを使用することで、CNNをViTに近づけることができるのではないか、という疑問が生じます。
本記事で紹介する論文ではこの疑問を踏まえ、31×31という、一般的なCNNと比べて大きいカーネルサイズを利用するCNNアーキテクチャであるRepLKNetを提案しました。その結果、ImageNetで87.8%のTop-1精度を示し、下流タスク性能を大幅に向上させるなどの優れた性能を示しました。
大きなカーネルを適用するためのガイドライン
CNNに対して単に大きな畳み込みを適用するのみでは、性能や速度の低下につながってしまいます。そのため、大きなカーネルを効果的に利用するための5つのガイドラインについて紹介します。
ガイドライン1:深さ方向(depth-wise)の大きな畳み込みは実際には効率的になります。
大きなカーネルを用いると、カーネルサイズに対して二次関数的にパラメータ数・FLOPsが増加するため計算量が多くなりますが、この欠点はDepth-Wise(DW)畳み込みを適用することで大幅に改善することができます。
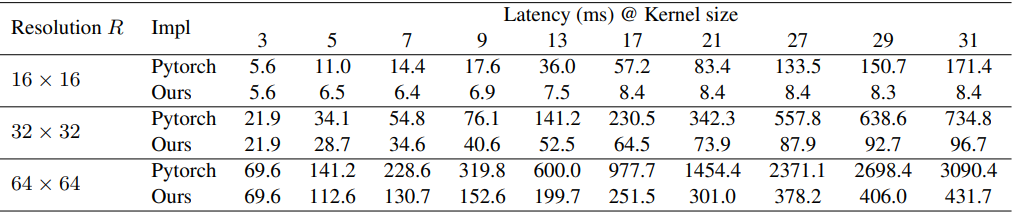
提案手法であるRepLKNet(詳細は後程)では、カーネルサイズを[3,3,3,3]から[31,29,27,23]に増加しても、FLOPsは18.6%、パラメータ数は10.4%の増加に抑えることができます。懸念点として、GPUのような最新の並列計算機では、DW畳み込み演算が非常に非効率的になるかもしれません。ただし、カーネルサイズが大きくなるとメモリアクセスの比率が低下するため、実際の待ち時間はFLOPsの増加ほどには大きくならないと考えられます。
備考
Pytorchなどの一般的な深層学習ツールは大きなDW畳み込みにうまく対応していないため、論文では以下の表のように改善された実装を利用しています。
ガイドライン2: identityショートカットは大きなカーネルを持つネットワークに不可欠です。
DW畳み込みによるMobileNet V2をベンチマークとして使用した場合、3x3または13x13のカーネルを適用した結果は以下のようになります。

表の通り、ショートカットがある場合には大きなカーネルを用いることで性能が向上していますが、使用しなかった場合は精度が低下してしまいます。
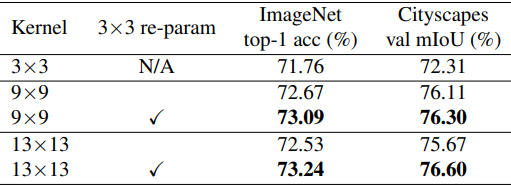
ガイドライン3:小さなカーネルによる再パラメータ化(re-parameterizing())により最適化の問題を改善できます。
MobileNet V2のカーネルサイズを9x9と13x13に置き換え、さらにStructual Re-parameterization()手法を適用した場合、次の表の通り性能を向上させることができます。
この手法は以下のように、大きなカーネル層と3x3層を並行して構築し、学習後にBatch Normalization層と3x3カーネルを大きなカーネルに融合しています。

このように、re-parameterizing手法を用いることで、最適化を改善することができます。
ガイドライン4:大きな畳み込みはImagenet分類精度よりも下流タスク性能を高めます。
上の表では、ImageNetで事前学習させたモデルをCityscapes上のDeepLabv3+()のセマンティックセグメンテーションタスクで転移学習させた場合の性能が示されています。このとき、ImageNetの精度はカーネルサイズを9x9に増加させることで1.33%向上した一方、Cityscapes mIoUは3.99%も向上しています。
(この傾向は論文で提案されたRepLKNetの実験結果でも見られており、これは大きなカーネルが有効受容野を増加させることや、形状バイアスを高めることにつながっていることによると思われます。)
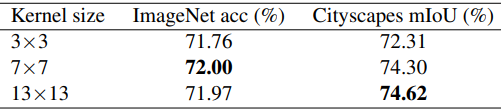
ガイドライン5: 大きなカーネル(例えば13×13)は特徴マップが小さい場合(例えば7x7)でも有効です。
MobileNet V2について、特徴マップに対しカーネルサイズを大きく設定した場合の結果は以下の通りです。
これら5つのガイドラインに基づき、論文ではRepLKNetと呼ばれるCNNアーキテクチャが提案されています。
提案手法:RepLKNet
RepLKNetは大きなカーネル設計による純粋なCNNアーキテクチャであり、構成は以下の通りです。
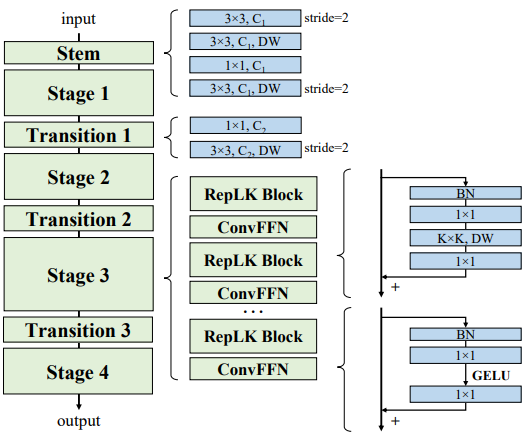
RepLKNetアーキテクチャはStem、Stage、Transitionブロックから構成されています。
Stem
Stemは最初の層であり、下流の高密度予測タスクで高い性能が得られるよう、最初に複数のconv層で詳細な情報を取得することができるように設計されています。図の通り、3x3の畳み込みと2xダウンサンプリングの後、DW3x3層、1x1畳み込み、ダウンサンプリング用のDW3x3層の順で配置されています。
ステージ
ステージ1~4はそれぞれ複数のRepLKブロックを含んでおり、ショートカットとDWの大きなカーネルを使用しています(ガイドライン2,1参照)。DWconvの前後には1x1の畳み込みを使用しており、各DW層は再パラメータ化(ガイドライン3参照)のために5x5カーネルが使用されています。
Transitionブロック
Transitionブロックはステージ間に配置されており、1x1畳み込みでチャンネルを大きくし、DW3x3畳み込みで2xダウンサンプリングを行います。総じて、RepLKNetはRepLKブロック数$B$、チャンネル次元$C$、カーネルサイズ$K$の3つがアーキテクチャのハイパーパラメータとなっています。そのためRepLKNetのアーキテクチャは、$[B1,B_2,B_3,B_4],[C_1,C_2,C_3,C_4],[K_1,K_2,K_3,K_4]$で定義されます。
実験結果
はじめに、RepLKNetのハイパーパラメータを$B=[2, 2, 18, 2], C=[128, 256, 512, 1024]$で固定し、$K$を変化させた場合について評価を行います。
ここで、カーネルサイズ$K$を[13, 13, 13, 13], [25, 25, 25, 13], [31, 29, 27, 13]とした場合を、それぞれRepLKNet-13/25/31とします。また、カーネルサイズが全て3または7となる、小さなカーネルのベースラインRepLKNet-3/7を構築します。
このとき、ImageNetにおける性能と、ImageNetで学習したモデルをバックボーンとした場合のセマンティックセグメンテーションタスク(ADE20K)性能は以下の通りです。
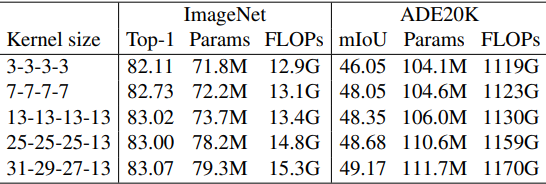
ImageNetの結果を見ると、カーネルサイズを3から13まで増加させた場合には精度が向上していますが、カーネルサイズをそれ以上大きくしても性能は向上しません。
一方、ADE20Kでは性能が増加しており、下流タスクにおいては大きなカーネルが重要であることが示されました。以降の実験では、先述の設定のうちカーネルサイズが最大のものをRepLKNe-31B、$C=[192, 384, 768, 1536]$のモデルをRepLKNet-31Lとします。
また、$C=[256, 512, 1024, 2048]$とし、RepLKブロックのDW畳み込み層チャンネルを入力の1.5倍にしたものをRepLKNet-XLとします。
ImageNet分類性能
次に、ImageNet分類性能を、全体的なアーキテクチャが似ているSwinと比較した結果は以下の通りです。
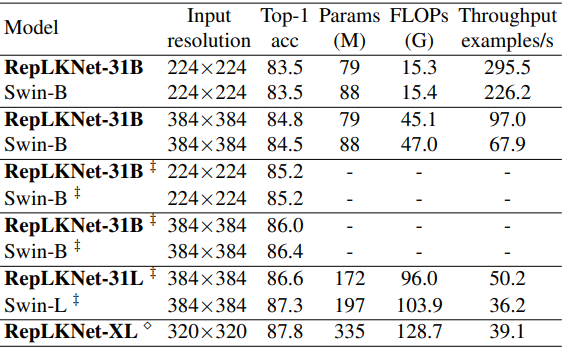
‡印はImageNet-22K上で事前学習させたのち、ImageNet-1KでFine-tuningした場合を示しており、無印の場合はImageNet-1Kでのみ学習されています。
総じて、大きなカーネルは先程と同じくImageNet分類には向いていないものの、RepLKNetは精度と効率面で良好なトレードオフを示すことが示されました。特に、ImageNet-1Kで学習したRepLKNet-31Bは、Swin-Bより高い84.8%の精度を達成し、43%高速に動作するなどの良い性能を発揮しています。
セマンティックセグメンテーション性能
次に、CityscapesとADE20Kについて、バックボーンとして事前学習済みモデルを利用した場合の結果はそれぞれ以下の通りです。
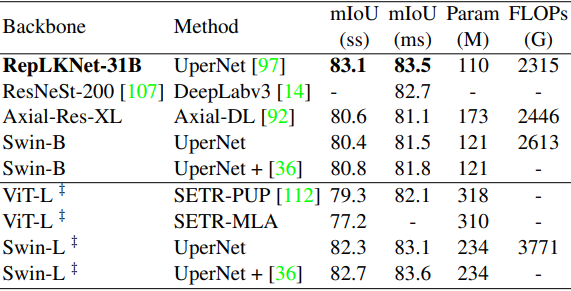
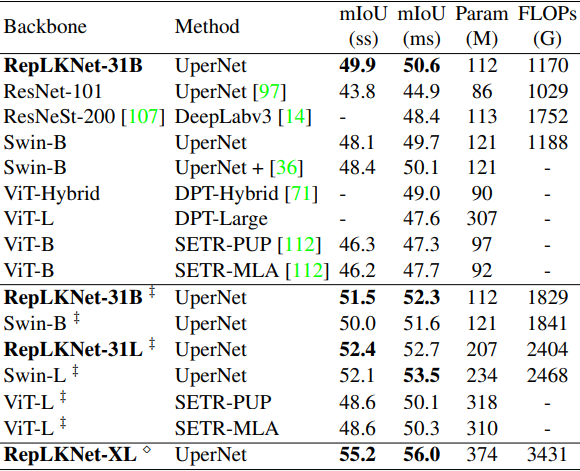
‡印はImageNet-22K上で事前学習させたものを、無印はImageNet-1K上で事前学習させたものを示しています。
総じて、RepLKNet-31Bは既存手法を上回る、非常に優れた結果を示しました。特に、Cityscapesでは、ImageNet22Kで事前学習したSwin-Lをも上回るなど、非常に良好な性能を示しました。
物体検出性能
次に、物体検出タスクに於ける結果は以下の通りです。
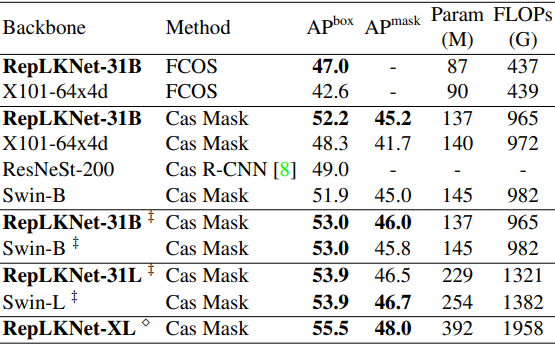
総じて、単にバックボーンを置き換えたのみで、既存手法より少ないパラメータ数・FLOPsでも、同等以上の性能を発揮できることが示され、提案手法の下流タスク性能の高さを示す結果となりました。
なぜ大きなカーネルが有効なのか?
大きなカーネルを使用することの有効性について、論文では以下のことが述べられています。
- 1) 大きなカーネルのCNNは小さなカーネルのCNNよりも大きなERF(有効受容野)を持ちます。
ERF(Effective Receptive Field)()の理論によれば、ERFは$O(K \sqrt(L))$に比例する($K$はカーネルサイズ、$L$は層数)とされており、カーネルの大きさは有効受容野の大きさに繋がります。
また、層の数が深いことは最適化の難しさに繋がるため、大きなカーネルを利用することで、より最適化が容易な少ない層でも大きなERFを得ることができます。実際に、ERFを可視化した結果は以下の図のようになります。
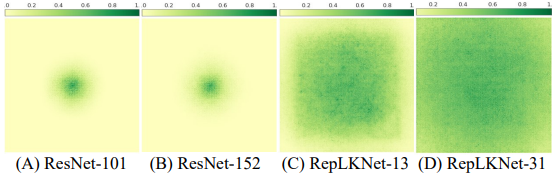
- 2) 大きなカーネルのモデルは人間に近い形状バイアスを持ちます。
- 3) 大きなカーネル設計は、ConvNeXtで動作する汎用的な設計要素です。
- 4) 大きなカーネルは、高いdilation率をもつ小さなカーネルよりも優れています。
(これらについての詳細は、元論文付録C,D,Eをご参照ください。)
まとめ
CNNアーキテクチャの設計上、カーネルサイズを大きくすることは長期間軽視されてきました。
本記事で紹介した論文では、大きな畳み込みカーネルを5つのガイドラインに基づき使用することにより、特に下流タスクにおける性能を大きく向上させることに成功しました。
この結果は有効受容野(Effective Receptive Field)がCNN設計において注意に値することや、大きな畳み込みがCNNとViTの性能差を大幅に縮めるなど、CNNとViT両方にとって示唆に富む知見が得られた研究であるといえます。






この記事に関するカテゴリー






