意味的な構造を捉えたスタイル変換!より美しく画像を変換する手法の登場
3つの要点
✔️画像内の意味的な構造を捉えるスタイル変換の手法を提案
✔️グラフカットを用いて特徴量をクラスタリングし、クラスタごとに特徴量の統計量をマッチング
✔️定性的な評価において、もっとも評価が高い変換を実現
意味的な構造を捉えるスタイル変換
ニューラルネットワークを用いたスタイル変換の手法の多くは、画像の特徴量マップの大域的な特徴量を用いて実現されています。たとえば、AdaINという手法においては、コンテンツ画像の、特徴量マップのチャンネルごとの平均と分散を、スタイル画像のそれと合わせ、それをデコードすることで実現されてきました。
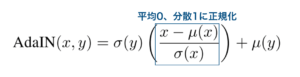
ですが、AdaINに代表されるような特徴量マップのチャンネルごとの統計量を用いた画像変換は、画像内の意味的な構造を捉えることは出来ていません。なぜなら、特徴量マップの大域的な特徴量を用いているため、画像内のどこにどのような物体があるか、という情報を無視してしまっています。これが原因となり、画像内の背景部分に対しても、物体に対しても全く同じような変換が行われてしまうなど、より良い変換を実現できなくなってしまう可能性があります。

実際の例を見てみます。上の画像のうち、一番左の画像が、変換のために使われるスタイル画像とコンテンツ画像です。AdaINなどの大域的な統計量を用いた手法は、木と背景が同じように変換されてしまうため、木のコンテンツとしての情報が失われてしまっていることがわかります。
今回紹介する手法は、画像内の特徴量マップには複数のスタイルのクラスタが存在すると仮定し、そのクラスタごとに統計量を正規化することで、画像の意味的な構造を捉えながらスタイル変換を実現する手法です。
特徴量のクラスタリング
そこで、今回の手法では、スタイル画像の特徴量のパッチをクラスタリングし、コンテンツ画像をそれぞれのクラスタに割り当て、クラスタ毎に統計量を正規化することで、意味的な構造を捉えることを試みます。
スタイル画像の特徴量マップをクラスタリングし、それをコンテンツ画像に適用するために、エネルギー関数を定義し、そのエネルギー関数を最小化するようにクラスタの割り当てを行います。このエネルギー関数はデータ項と平滑化項に分けられ、この二つの最小化することを目指します。
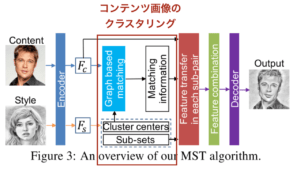
図 グラフカットを用いたスタイル変換のアーキテクチャ
続きを読むには
(3072文字画像14枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






