「説明のテンプレート」を自動で学習すれば文生成を自在に操れる
本論文:Learning Neural Templates for Text Generation
著者実装:https://github.com/harvardnlp/neural-template-gen
チャットボットや文書要約などのサービスを提供する上で、ニューラルネットワークの活用は欠かせません。しかし主流な手法であるエンコーダー・デコーダーは出力結果を制御することが難しく、意図した結果が得られないことがよくあります。
特にビジネスシーンにおいて出力結果を制御することは、利用者の要求を満たすために重要です。ニューラルネットワークは流暢な文を生成できる一方で扱いが難しく、泣く泣くルールベースの手法で我慢している…という状況もよくあるのではないでしょうか。例えば「イベントの時間・場所・参加費を確実に伝えられる文を生成したい」といった場合でも、エンコーダー・デコーダーモデルはその全ての情報を盛り込んだ文を生成してくれるとは限りません。
本手法では文生成のテンプレートを自動学習することで、どのような情報を盛り込んで欲しいかを指定できる文生成手法を提案しています。
説明文生成タスク
本研究では与えられた情報(レコード)から、それを説明する文を生成するタスクに取り組んでいます。例えば以下の図のように、Frederick Parker-Rhodesという人物について「1914年生まれ」「イギリス出身」などのレコードが与えられたとします。

この内容を受け取り、次のような文を生成することが目的です。今回の例では、与えられたレコードのうち、「名前、生没、出身、専門分野」を抜き出すことで、以下のような説明文を作ることができます。与えられたレコードからどの情報を抜き出し、どのように文にするかという点で難しく、様々な角度から研究が行われています。

エンコーダー・デコーダーの問題点
このようなタスクを学習するときに、一般的にはエンコーダー・デコーダーモデルが用いられます。すなわち、与えられたレコードをベクトルにエンコードし、そのベクトルを初期状態としたRNNなどを用いて一単語ずつ文を生成していく手法です。こうした手法は機械翻訳などで用いられてますが、本タスクのように決められた形で文生成をする場合には以下のような不便な面もあります。
文生成の理由がわからない
ニューラルネットワークが「ブラックボックス」と呼ばれるように、エンコーダー・デコーダーを用いた手法においても「なぜそのような文生成を行なったのかが分かりづらい」という問題があります。例えば上述のFrederick氏の情報に対して、モデルが以下のような文章を生成したとします。
frederick parker-rhodes (21 november 1914 – 2 march 1987) was an english mycology and plant pathology, mathematics at the university of uk.
この文はandの位置や品詞の間違いなど全体的な流暢さが欠けているだけでなく、情報そのものに関する誤りも含まれています。例えばレコードには「イギリス在住」という記述はありますが、生成された文に含まれている「イギリスの大学に所属しているか」は記述されていません。
モデルの出力を改善するためには、こうした文生成の失敗を分析することが重要です。しかし、エンコーダー・デコーダーは「なぜcomputer scienceなどの情報を省略したのか」「なぜイギリスの大学という情報を付け足したのか」といった理由が明確ではないため、モデルの改良が難しいといえます。
文生成の制御が難しい
文生成の理由がわからないという問題は、文生成の制御が難しいという問題に直結します。例えばFrederick氏のレコードを記述する上で、生没情報を説明文に含めたくない場合を考えます。エンコーダー・デコーダーの場合、エンコーダーに生没情報を入力しないという方法で制御を試みることが可能ですが、それにより出身地も省略されてしまうなど文生成の関係のない箇所に影響が出てしまうことがあります(エラーの伝播)。
文生成を制御することは、レコードから説明文を生成するという今回のタスクにおいて非常に重要です。もし説明文の形式が統一されている場合は、あらかじめテンプレートを指定することで安定した出力を得られるためです。またこうした文生成の制御は、実際の自然言語処理の活用シーンにおいても重要であるといえます。
テンプレートの自動学習
neural HSMMを用いたテンプレートの学習
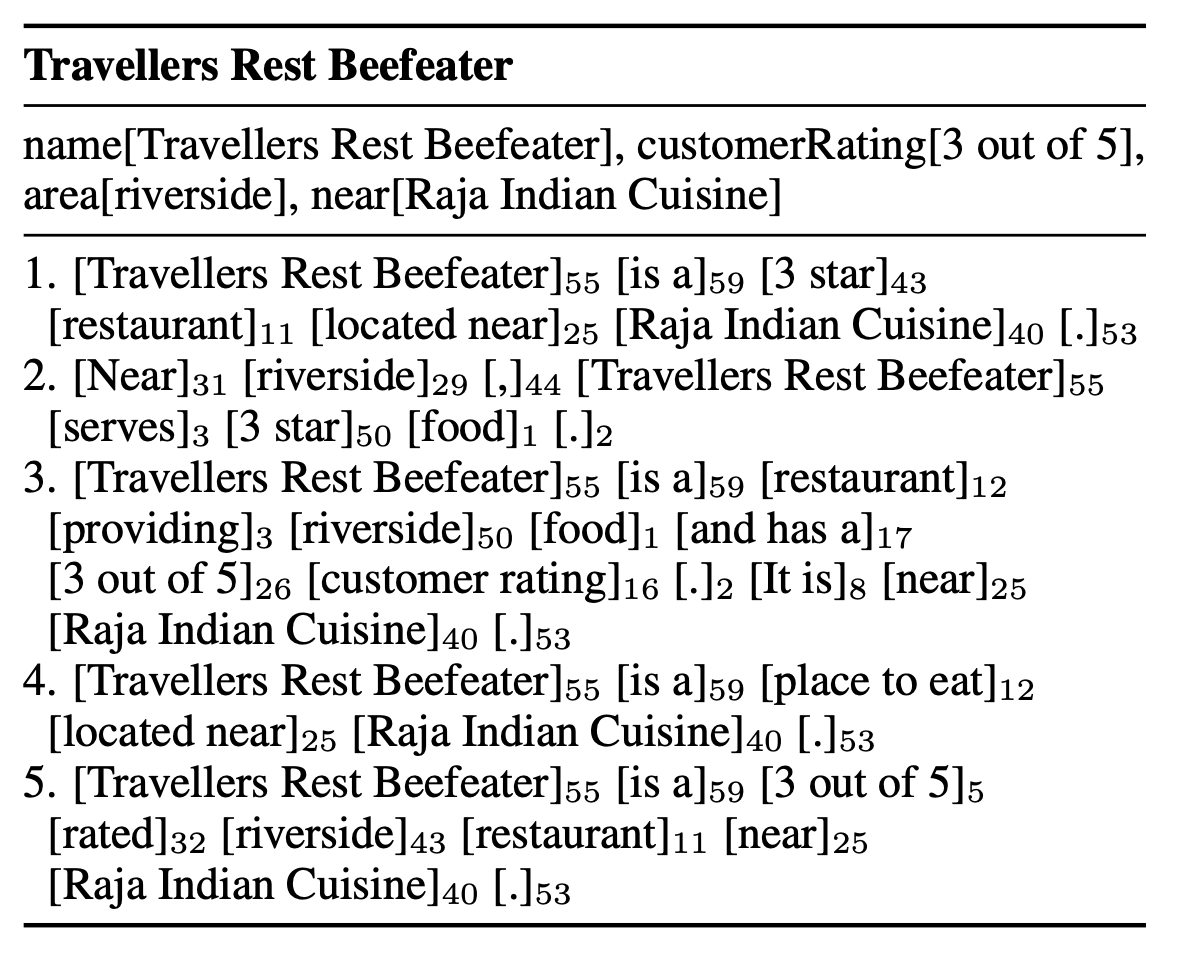
上記の問題を解消するために、本研究では文生成におけるテンプレートの自動学習を行います。以下は「Travellers Rest Beefeater」という飲食店に関するレコードと、提案手法によって生成された文の例です。生成された文がブロックごとに分かれており、それぞれ55・59といったIDが振られています。ブロックは順に「店名」「is a」「レーティング」「店舗種類」「〜の近く」「場所」「ピリオド」となっており、このテンプレートを組み替えることで自在に出力を制御することが可能です。

こうした機構を実現するために、ニューラル隠れセミマルコフモデル(neural HSMM)を用いています。生成される文の各ブロックは、それぞれ異なる隠れ状態から生成されると考えます。例えば上の例の「Travellers Rest Beefeater」というブロックは、55番目の隠れ状態から生成されます。そして、55番目の隠れ状態はレコードを参照して「店名」を抜き出すようなものとして自動的に学習されます。
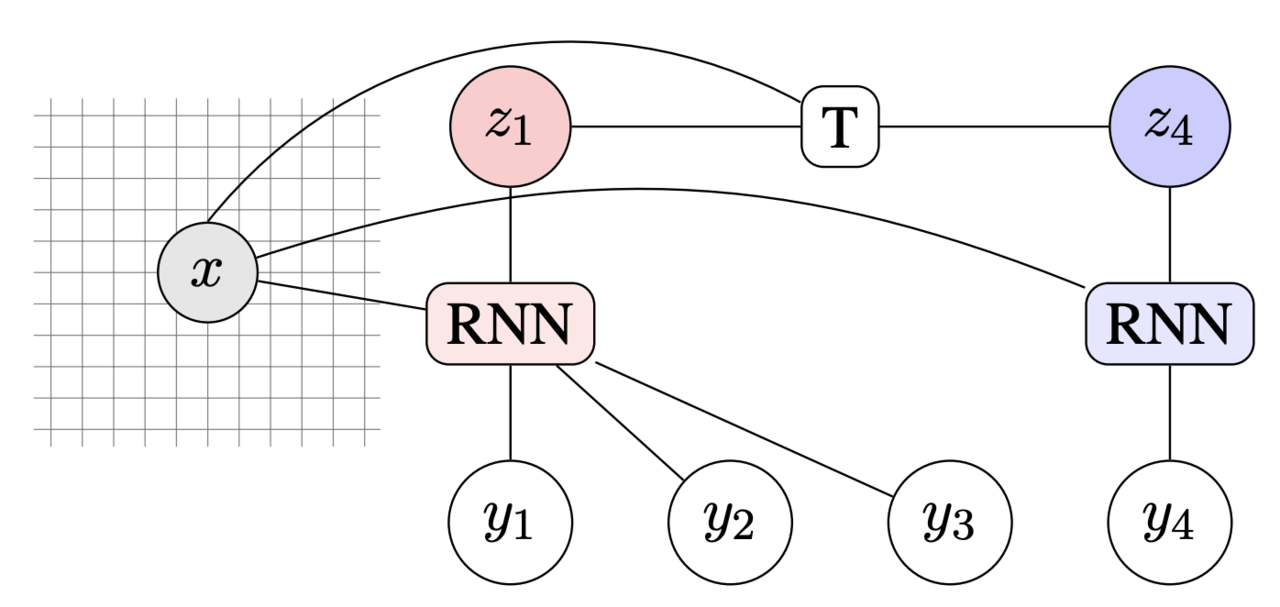
この機構は以下の図のようにして表されます。xは店舗のレコードなどの情報、zは各ブロックを生成するための隠れ状態です。隠れ状態zを受け取り、RNNを用いてブロック内の各単語yを順に生成していきます。また隠れ状態zは遷移確率Tによって遷移し、このTも学習を行うことで文全体の生成を学習します。
各ブロックは、直前のブロックで生成された単語列とは無関係に隠れ状態zから生成されるため、エンコーダー・デコーダーモデルで問題となっていたエラーの伝播が発生しません。すなわち青色のRNNで単語y4を生成するときに、赤色のRNNの生成結果を考慮しません。もちろん、赤色のRNNの隠れ層を青色のRNNに渡すことで、この制約を容易に取り払うことも可能です。
評価
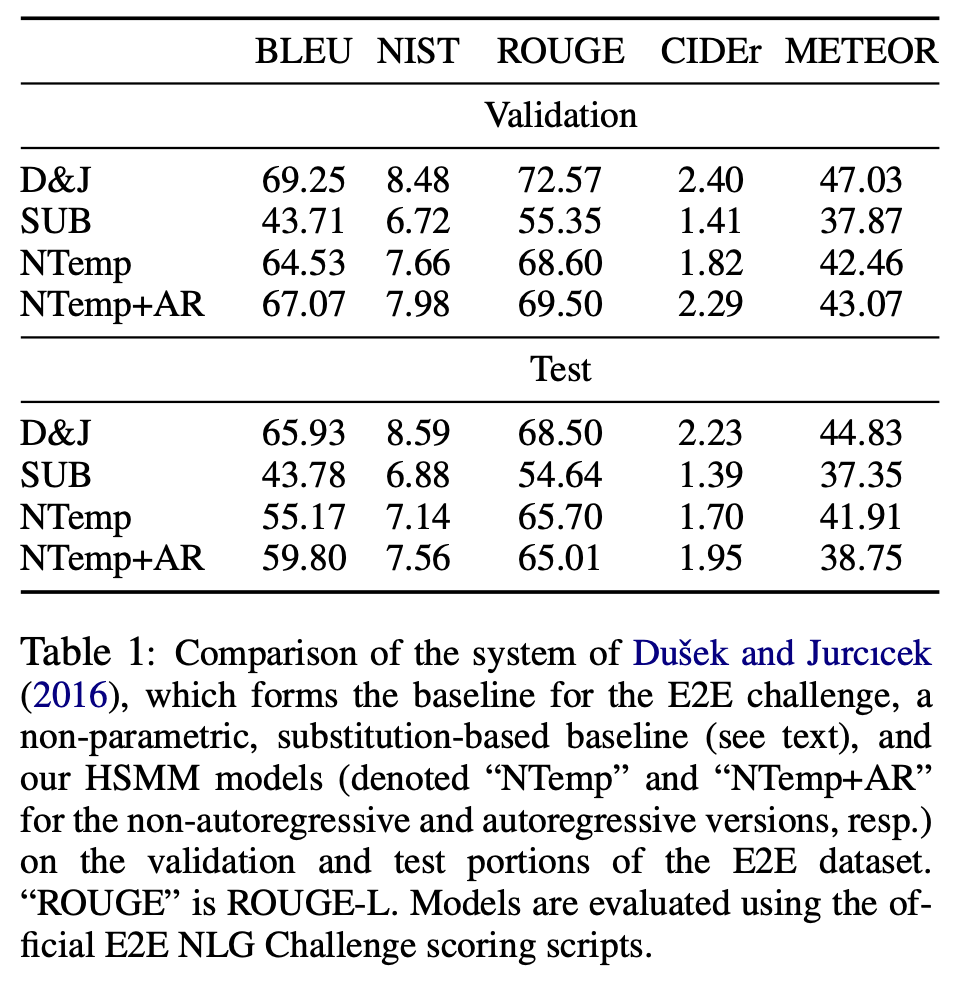
タスクにおける量的な評価は以下の表の通りとなっています。BLEU、NISTなどは生成された文が正解の文とどれほど近いかを表す指標で、いずれも高いほど性能が良いスコアです。D&Jは従来のエンコーダー・デコーダーモデル、SUBはテンプレートを用いたシンプルなモデル、NTempとNTemp+ARは提案モデルで、それぞれブロックごとに独立な生成を行うもの・ブロック全体をみて生成を行うもの(前節下線部)を表します。実験結果より、提案手法はエンコーダー・デコーダーモデル(D&J)に数値面で劣っているものの、文生成を制御できるという点を考慮すると「十分戦えている」数値であることがわかります。
本手法のキモである文生成の制御の結果は以下の表にまとめられています。Travellers Rest Beefeaterというレストランの説明文について、異なるブロックの並び(テンプレート)を指定することで、文生成が制御できていることがわかります。数値上の性能を大きく落とさずに、これだけ文生成を制御できている点が本論文の評価ポイントです。
まとめ
本記事では、文生成におけるテンプレートを自動で学習する手法について紹介しました。実際のタスクにおける数値面の性能では既存手法に届きませんが、実応用を考えた際に非常に有用な手法であるといえます。本研究は世界的に有名な自然言語処理の国際学会、EMNLP2018で発表され、著者による実装も公開されていますので手軽に触ってみることが可能です(記事冒頭参照)。整備されたレコードが手元にあり、チャットボットやその他のメディアなどを介してそうした情報を届けたいという場合に、ぜひ検討して見てはいかがでしょうか。



この記事に関するカテゴリー






