バッチ正規化を使用しない新たなチャンピオンNFNetsが登場!画像タスクトップの性能!
3つの要点
✔️ 新しいadaptive gradient clipping法を用いたバッチ正規化の代替
✔️ 正規化なしアーキテクチャNFNetsがSOTAを達成
✔️ バッチ正規化を用いたモデルよりも、優れた学習速度と伝達学習能力を持つ
High-Performance Large-Scale Image Recognition Without Normalization
written by Andrew Brock, Soham De, Samuel L. Smith, Karen Simonyan
(Submitted on 11 Feb 2021)
Comments: Accepted to arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Machine Learning (stat.ML)




はじめに
今日の深層学習ネットワークの多くは、バッチ正規化・ドロップアウト・ReLUのような活性化関数とともに残差接続を使用することが多いです。バッチ正規化ですが、ほとんどすべてのタスクで当たり前のように使用されています。バッチ正規化は損失面を平滑化し、ネットワークに正則化効果を与え、より大きなバッチで学習できるようにすることが示されています。
しかし性能の向上にもかかわらず、バッチ正規化には欠点もあります。それはかなり高価な操作であること、さらに悪いことに、学習例間の独立性を壊してしまいます。また、推論中のモデル性能と学習中のモデル性能の間に不一致が生じる可能性があり、隠れた追加のハイパーパラメータを学習する必要があります。したがって、バッチ正規化が将来のモデルを支援し続けるかどうかは疑問であり、代わりに有害な効果があるかどうかを考えるのが適切とされています。ここは意外と感じる人もいるでしょう。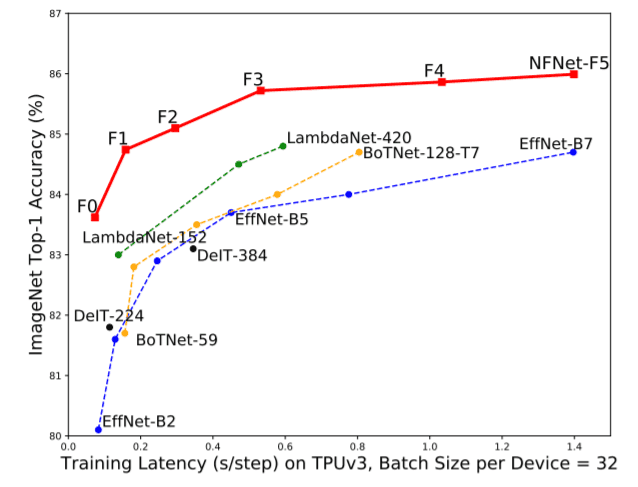
本論文では、主にパラメータノルムに対する勾配ノルムのユニットワイズ比に基づいたAdaptive Gradient Clipping(AGC)を紹介します。AGCは正規化を使用しないにもかかわらず、ImageNetベンチマーク上でSOTAを獲得するNFNetsに使用されます。EfficientNet-B7に匹敵する精度を持つNFNet-F1は、なんと8.5倍の学習速度を実現しています。3億枚の画像で事前学習を行い、ImageNet上で微調整を行った後、NFNetはBNを使用したモデルよりも精度が高くなります(ベストモデルでは89.5%のトップ1)。
バッチ正規化はどのように役立つのか?
BNの長所と短所を考えると、長所を残しつつ短所を解消する技術を開発したい。では、何を保持する必要があるのかを見てみましょう。
Downscaling of residual branch
BNの長所と短所を考えると、長所を残しつつ短所を解消する技術を開発したい。では、何を保持する必要があるのかを見てみましょう。
Mean-Shift elimination
ReLUのような活性化関数は平均活性化が0ではない。入力のドット積が0に近くても、独立した学習インスタンスの活性化のドット積は大きくなり、深さが増すにつれてこの問題は悪化する。BNでは、各チャネルの平均活性化を0にし、各ステップでの平均シフトを排除する。
Regularization effect
ミニバッチで計算された統計量は、多少のノイズを導入し、精度を向上させます。
Allows efficient large-batch training
BNは損失面を平滑化し、より大きな安定した学習率、より大きなバッチサイズ、より少ないウェイト更新での学習を可能にします。
Removing Batch Normalization
この論文では、NF-ResNetsと呼ばれる'Normalizer-Free ResNets'をベースにしています。NF-ResNetsは残差ブロックを使用します。
hi+1 = hi + αfi(hi/βi)
hiは、i 番目の残差ブロックへの入力を表します。fiは分散、すなわち、Var(fi(z)) = Var(z)を保持することに注意してください。 βi = sqrt(Var(hi))は第i番目の残差ブロックへの入力の標準偏差です。BNと同様に、この残差ブロックはスケーリングされた活性化の正の効果を持ち、勾配をより安定にします。平均シフトを防ぐために、NF-ResNetsは(Nはfan-in)で与えられたスケーリングされた重みの標準化を使用します。

これに加えて、活性化関数(ReLU, GELU)は、活性化関数に固有のスカラーγでスケーリングされています。ReLUの場合、γ = sqrt[2/(1 − (1/pi))]です。これは、スケーリングされた重み標準化層によって変化した分散を元に戻す効果があります。さらに、NF-ResNets は、Dropout と Stochastic Depth も正則化の材料として利用しています。
NF-ResNetsは,バッチサイズが最大4096までのImageNet上のバッチ正規化ResNetsと競合します。しかし、バッチサイズが4096を超えると性能が低下する傾向にあります。さらに重要なのは、性能がEfficientNetsほどではないということです。
より良いNF-ResNetsを作成する
NF-ResNetsをより高いバッチサイズで学習できるようにするために、まずGradient clippingを試みました。Gradient clippingは、許容範囲外のグラデーション値を代入することで動作します。

しかし、パラメータλは不安定であり、バッチサイズ・モデルの深さ・学習率のいずれの変化に対しても調整しなければならないことがわかっています。この問題を解決するために、、、
Adaptive Gradient Clipping(AGC)
勾配のノルムと重みベクトルのノルムの比は、重みがどのくらい変化するかを知ることができます。比率が大きければ、学習が不安定で、勾配をクリップする必要があることを示唆します。1つのレイヤーの重みと勾配行列のノルムを一度に計算するのではなく、ユニットワイズ(行単位)の比率を計算し、その情報を使ってユニットワイズ(行単位)の勾配をクリップします。数学的には、層の重さℓのi行目のAGCは、下記式によって与えられます。

Ablation Studies
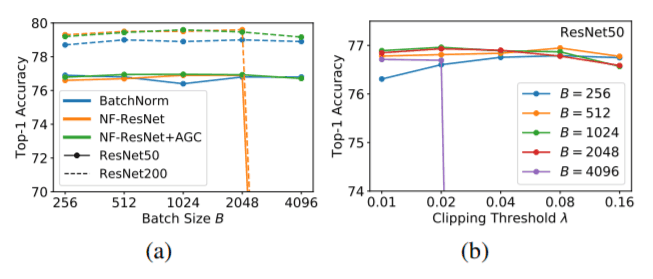
一連のablation studiesにより、AGC を用いた NF-ResNet は、NF-ResNet 単独よりも高いバッチサイズでの学習が可能であることが明らかになりました。また、より高いバッチサイズでの学習には、より小さなクリッピング閾値(<0.02)が必要であることもわかりました。また4つのResNetブロック群すべてにAGCが有効であることがわかりました。
逆に、最終的な線形層にAGCを適用すると性能が低下します。
Normalizer-Free Model Architecture: NFNets 
NF-Net Transition Block(left) and NF-Net Non-Transition Block(right)
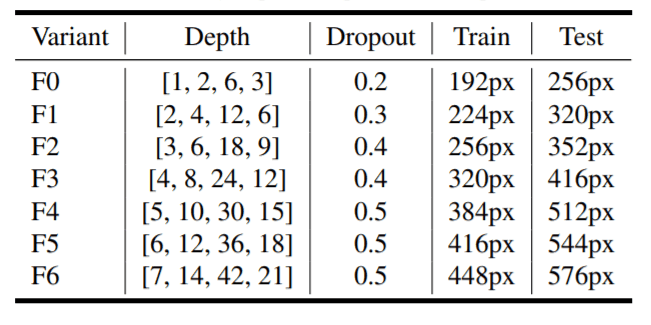 深さ・ドロップアウト・画像解像度の異なるNF-Netのバリエーション。
深さ・ドロップアウト・画像解像度の異なるNF-Netのバリエーション。
SF-Netは、SE-ResNeXtのGELU活性化モデルにわずかな修正を加えることで構築することができます。前述したように、SE-ResNeXtのすべてのGELU活性化は、分散を保持するためにスカラーγでスケーリングされています。また、最後の線形層を除くすべての重みはAGCを利用しています。
3つの3x3 conv(ストライド2の2つとストライド1の1つ)を持つ最初のステムがあり、128チャンネルの特徴マップに画像をダウンサンプリングします。次の4つのステージは、それぞれのバリアント(F0~F6)に応じて異なる数のブロックを持ちます。各バリアントの最初のブロックは左上の図のように遷移ブロックであり、残りのブロックは非遷移ブロックです。遷移ブロックは、特徴量マップをダウンサンプリングし、チャンネル数を増加させます。
各ブロックは、そのブロックの出力チャネル数の0.5倍にチャネル数を減らす1x1畳み込みで構成されています。これに続いて、一定のグループ幅128の2つの3x3畳み込みが行われます。最後に、1x1畳み込みにより、チャンネル数が2倍に増加します(つまり、ブロックの出力チャンネル数に等しい)。
実験と評価
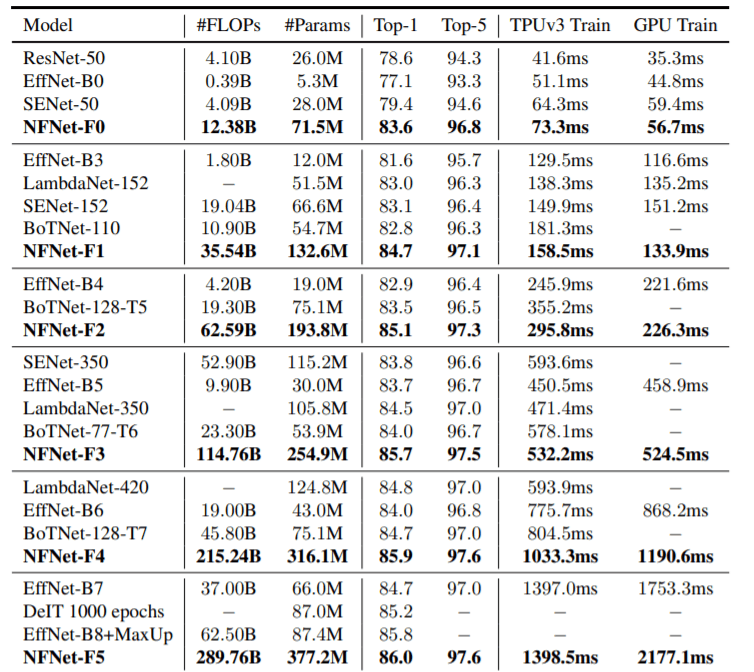
ImageNet上のNF-NetとSOTAモデルの比較
上の表はImageNet上での精度、モデルサイズ(FLOPsとParams)、GPU&TPUによる学習時間(シングルステップ)の観点から、NFNetと他の最新モデルとの比較を示したものです。NFNet-F5は精度86.0を達成しているが、パラメータ数やFLOP数が大きい。EfficientNet-B7の結果はNFNet-F1の8.7倍,FLOP数が若干少なくても遜色ない。
![]()
事前学習後のImageNetの精度
3 億枚の画像を用いてBNを用いたResNetsとBNを用いないNF-ResNetsの事前学習を行います。これらをImageNet上で微調整した後に得られた結果を上の表に示します。ほとんどすべての場合において、NF-ResNetsの方がBN-ResNetsよりも優れていることがわかります。
結論
画像認識タスクにおいて、BNを使用しないモデルがBNを使用したモデルと一致し、さらにはそれ以上の性能を発揮することがわかったことは興味深いことでした。モデルはBNの優れた特徴を保持しており、いくつかのモデルで学習スピードが非常に速くなりました。しかし、この論文では、ノーマライザを含まないモデルがNLPタスクや、インスタンスセグメンテーションや物体検出などの他のビジョンタスクでも同じように機能するかどうかについては調べきれていません。これらは今後の研究課題となると考えられます。詳細については、論文を参照してください。


わかりやすい動画解説はこちら



この記事に関するカテゴリー






