テクスチャ情報に意味のないデータセットを用いて、形状情報を重視するように学習させる
通常の画像データセットで学習されたCNNはほぼテクスチャに依存して分類していることが確認されています。この論文ではテクスチャ情報に意味のないデータセット用いて学習することで形状に着目させることを提案しまています。
AIは形状情報を重要視するの苦手?
以前AI-SCHOLRでも紹介しましたが一般的なCNN(画像認識モデル)は物体形状よりもテクスチャ(ローカル情報)を重視していることがいくつかの研究からわかっています。一方人間はオブジェクトの形状(グローバル情報)を頼りに識別していると考えられています。
例えば上の3つの画像を見た時、人間の目にはどのように見えるでしょうか?

大半の人は、左:ゾウの皮膚っぽいけど、よく分からない?、真ん中:確実にネコ、右:テクスチャは変だけど形はネコ。というような感想を持つのではないでしょうか?
しかし、ImageNet で学習したCNNに識別させると左の画像に対し、81.4% という高い確信度で「ゾウ」と答えています。一方真ん中の猫は人間から見ればどう見ても猫ですがCNNがネコと認識する確率は、71%と少し低めです。右に限っては、63%の割合で「ゾウ」と答えています。
このように、人とCNN(この論文では ResNet-50が使われている)で識別結果が異なる理由として、人は形状を重視し、CNN はテクスチャを重視しているという傾向にあり、CNNは形状のグローバル情報に対して鈍感であることが判明しています。
一方、物体の形状が人間の物体認識にとって最も重要な単一の手がかりであることはよく知られており、サイズや他の手がかりよりもはるかに重要度が高いと考えられています。
CNNにテクスチャ情報ではなく、形状の情報を重視するように学習させることによって、 物体検出の性能向を上げようというのが今回の論文になります。
なぜ、形状が認識できないのか?
CNN がテクスチャを重視して識別していることが分かっていますが、その理由として、「CNNは、局所的なテクスチャ情報だけで充分正解でき、わざわざグローバル的な形状特徴まで学習する必要がないから」というものが考えられます。
このことを確かめるために論文ではImageNetの元のテクスチャのすべての単一画像を取り除き、それをランダムに選択したスタイルで置き換えることによって、新しいデータセット(Stylized-ImageNet略SIN)を作成しました。つまりテクスチャ情報に意味のないデータセットに仕上がっています。このデータセットを用いて形状情報を重視するように学習できるかを試しています。

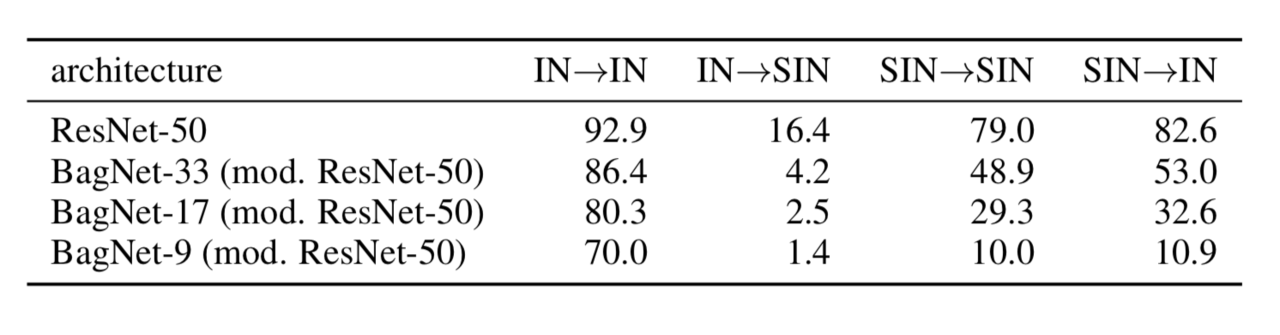
結果
結果は、Image NETで学習すると性能は著しく低下しますが、テクスチャ情報に欠けるSIN で学習した場合は それなりに高い性能が出ていることが分かります。
つまり、CNNは形状情報を学習できないわけではなく、テクスチャ情報に意味のないデータセットを用いて学習すれば形状情報を重視するように学習させる事が可能ということです。
また、以下の図はResNet-50がテクスチャ情報を使った決定の割合です。左へ行けば行くほど、テクスチャ情報に頼る割合が少なくなり、右に行けば行くほど、利用率が上がっています。
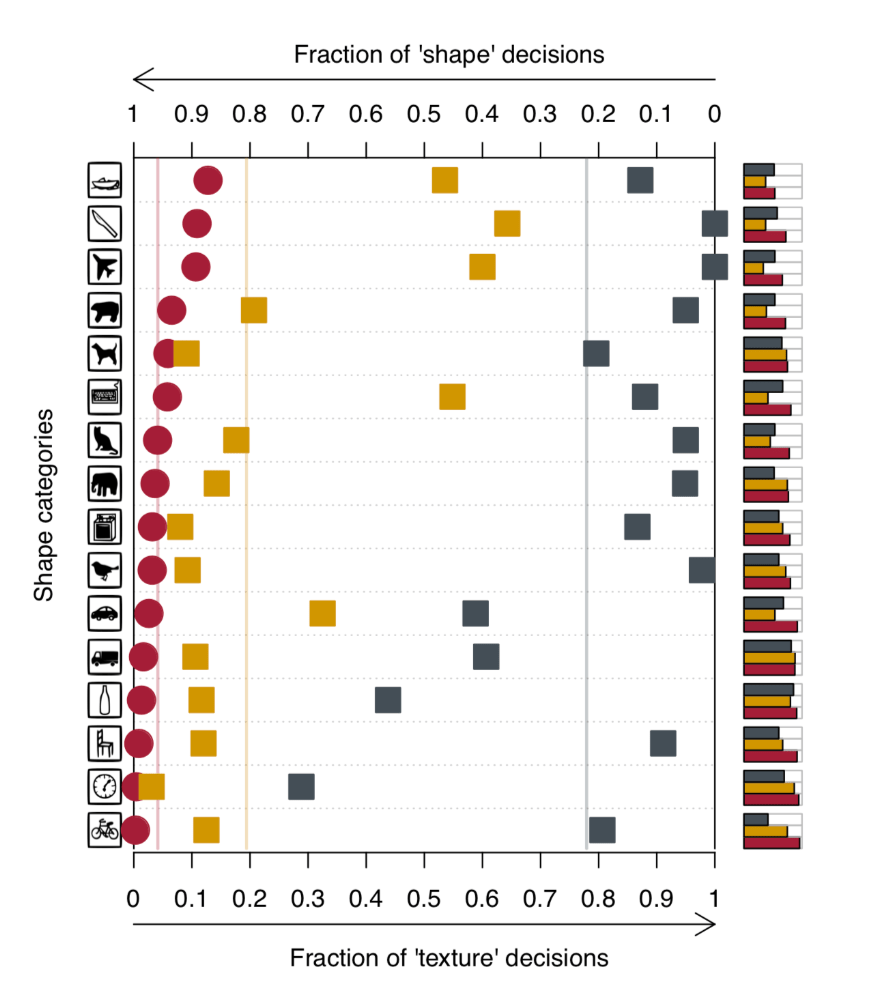
人間は赤丸、黄色がテクスチャ情報に欠けるSINで学習した ResNet-50、グレのー四角が image net で学習した ResNet-50となっています
黄色が赤に近づいてる事から、テクスチャ情報の欠けるデータセットを用いる事で、人間の認識の仕方に似せるのが可能なことがわかりました。また、SINで学習したResNet-50は、ぼやけ以外や画像の歪みに対してもロバストになっていることがわかります。



この記事に関するカテゴリー






