最適化アルゴリズムを俯瞰し、傾向を掴もう!
3つの要点
✔️ 大規模な最適化アルゴリズムのベンチマークの1つを提案
✔️ 最適化アルゴリズムは問題に依存
✔️ デフォルト使用が有用な可能性
Descending through a Crowded Valley -- Benchmarking Deep Learning Optimizers
written by Robin M. Schmidt, Frank Schneider, Philipp Hennig
(Submitted on 9 Mar 2020)
Comments: Accepted at arXiv
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
Paper Official Code COMM Code
はじめに
学習モデルの学習時間や精度に最適化アルゴリズムは重要な役割を果たしていることは誰もがわかっています。多くの方が最適化アルゴリズムを選択し、そのハイパーパラメータをチューニングすることで学習モデルの精度を少しでも高くしようと頑張っている現状があります。しかし、最適化アルゴリズムの選択やハイパーパラメータのチューニングなど明確な解析結果はなく、感覚や実践経験によって行われることがほとんどです。また精度に対して、影響が大きいため、年々最適化アルゴリズムに関する研究は増え続けています。図1は最適化アルゴリズムに対する論文と年次推移になります。2019年から2020年で減っているように見えるのは単純に収集期間がまだ2020は残っているためなので基本的には増えていると考えて大丈夫です。
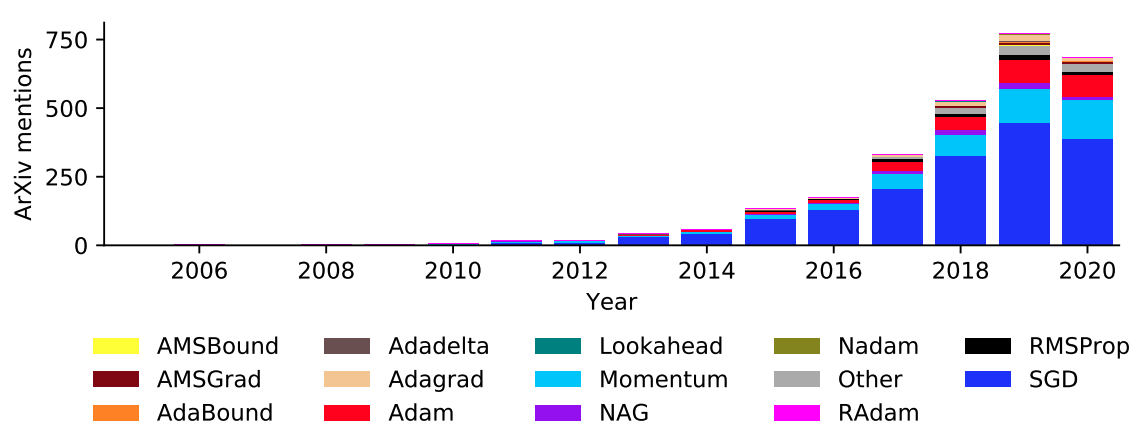
図1. 最適化アルゴリズムに対する論文と年次推移
また最適化アルゴリズムの提案研究のほとんどが、研究者自身の最適化アルゴリズムが優位であることを示すことが一般的です。
また、現在最適化アルゴリズムがどれくらいあるか知っていますか?著者による最適化アルゴリズムのサーベイ表1を示します。これでも全てを網羅しているわけではありません。また、表2に最適化アルゴリズムのパラメータスケジュールがまとめられています。
表1. 最適化アルゴリズムの種類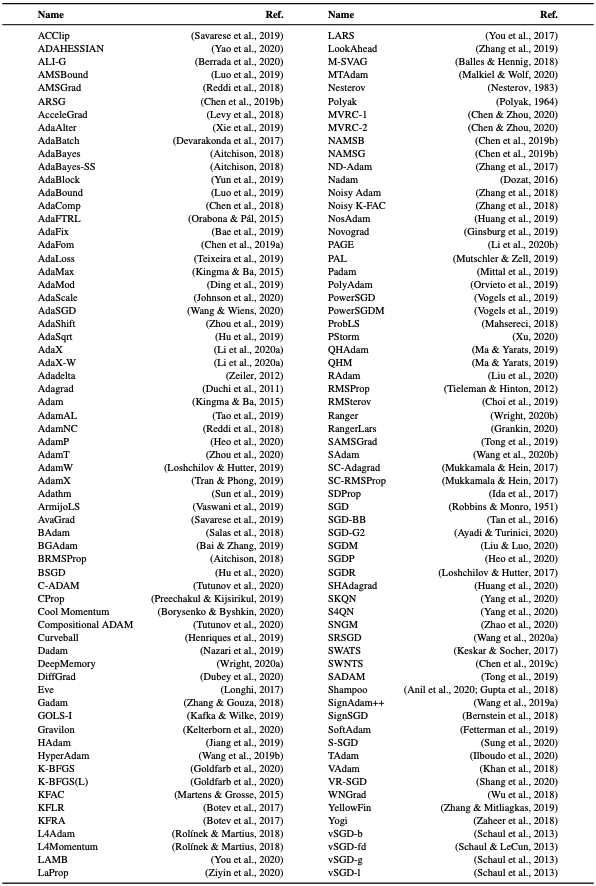
表2. 最適化アルゴリズムスケジュールの概要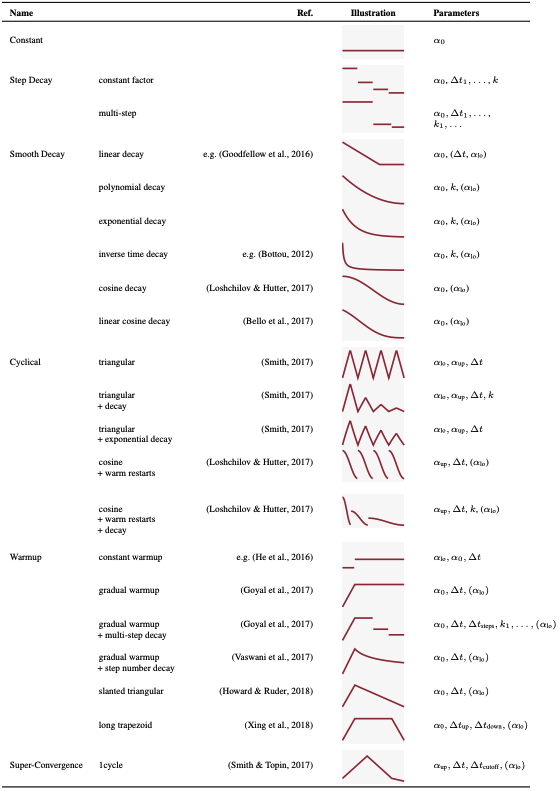
驚く人もいると思いますが、少なくともこれだけ提案されています。厄介なところはこれらの比較解析が少ないということです。そのため、多くの人がSGDのような昔から好まれているものを使う傾向があります。
なぜ、比較解析を行うことがないのか。それはこれらの比較解析での検討項目の組み合わせが膨大になるためです。それに加え、調整や実験の繰り返しによる時間と労力的なコストが大きいことや計算リソース問題があります。
そこで今回ご紹介する論文は、最適化アルゴリズムの選択やハイパーパラメータによる影響を比較検討し、最適化アルゴリズムの傾向を掴むファンダメンタルな研究になります。(1つ注意点なのが、著者たちも無限にリソースがあるわけではないため、実務的な範囲での検討程度と考えておくと良いでしょう。また、これはスタートであってモデル全体の検討まではできていないのでまだ甘さがありますが、傾向を掴むことと俯瞰して最適化アルゴリズム全体を見ることにはちょうど良いと思います。)
貢献
- 最適化アルゴリズムの広範囲的なまとめのキャッチアップが可能(表1と表2)
- 大規模な最適化アルゴリズムのベンチマークの1つを提案
- 数千回の分析と経験的な実験で、最適化アルゴリズムは問題に依存する
- 最適化アルゴリズムのデフォルトパラメータとチューニングパラメータに大きな差がないことが多い(AI-SCHOLAR内の記事"パラメータチューニングは経験値の差がものをいう黒魔術!?"でも同一のパラメータのデフォルト値の取り扱いについての示唆があります)
- 学習率スケジュールは、”調整なし”よりは比較的有効であるが、問題によって効果が大きく異なる
- 実験から汎用的な最適化アルゴリズムは見つからなかったが、逆に問題に特化型の最適化アルゴリズムがあることが判明
実験
実験内容はシンプルです。図2を見てください。
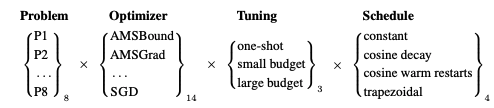
図2. 検討項目と組み合わせ
- 8つ(P1~P8)の問題に対する最適化アルゴリズムを評価
- 数ある最適化アルゴリズムから人気の高い14つを選定
- それに対して、3つのチューニング
- 4つの学習率スケジュールを検討
これらの組み合わせで評価します。評価指標は研究であれば特定の1つではなく、複数の評価項目を使いますが、今回は実社会でのAIエンジニアを想定しているため、今回はテスト精度(または、テスト損失)での評価のみに言及しています。
Problem
それぞれのタスクについては表3にまとめています。
表3. 8つの問題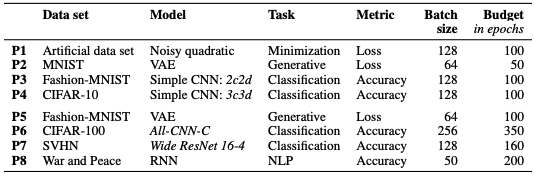
P1~P4問題はデータセットのsmallです。P5~P8はlargeです。モデルやタスク等は表の通りです。
Optimizer
数ある最適化アルゴリズムの中から、もっとも使用されているという意味で人気な最適化アルゴリズムを14つ選定しています。詳しくは表4をご覧ください。特にTuning Distributionは次のチューニング時のパラメータの調整の探索範囲になります。
表4. 選定された最適化アルゴリズムの各項目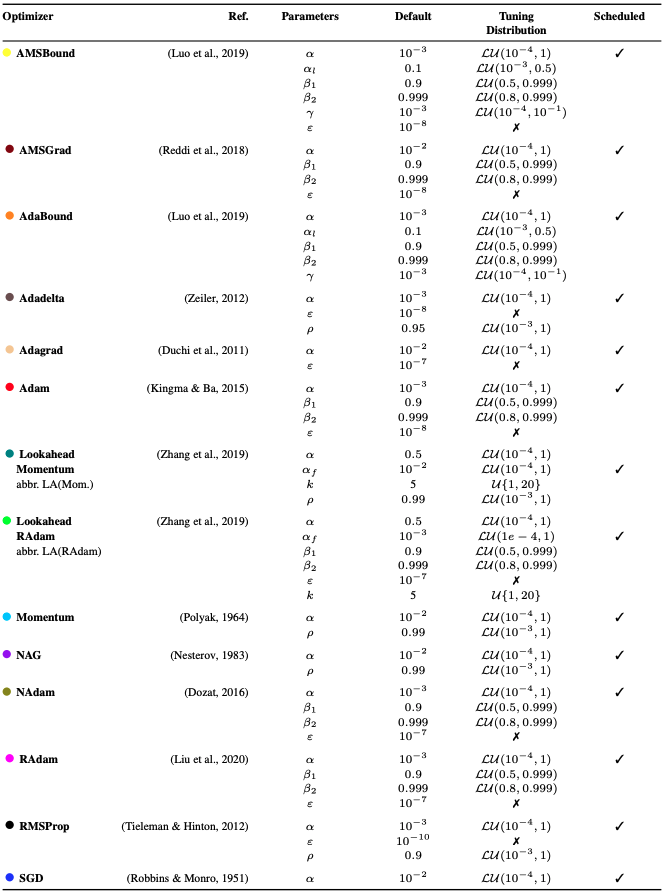
Tuning
チューニング方法は3つです。
- 提案者や研究者によるデフォルト値をしようする。デフォルト値は前項目の表4を参考にしてください。
- 小リソースチューニング(small budget)
- 大リソースチューニング(large budget)
small budgetとlarge budget
単一のシードのみをしようして25回(small budget)と50回(large budget)チューニングを行います。その後シードによる精度影響が偶然発生する可能性があるため、最適にチューニングした設定でシード値を10個ランダムに設定し、その平均値と標準偏差にて評価します。チューニングにはランダムサーチにて行いました。
Scheduled
学習率のスケジュールに関してはconstantとcosine decayとcosine with warm restartsとtrapezoidalの4つに設定しました。詳しくは表2を見るとわかります。
結果
今回は実験回数が凄いので多くの結果が出てきます。その中でも特徴的なものを取り上げます。他の結果が気になる方はぜひ原著を見てください。かなりの量の結果に圧倒されると思います。
以下の図3に結果を載せます。
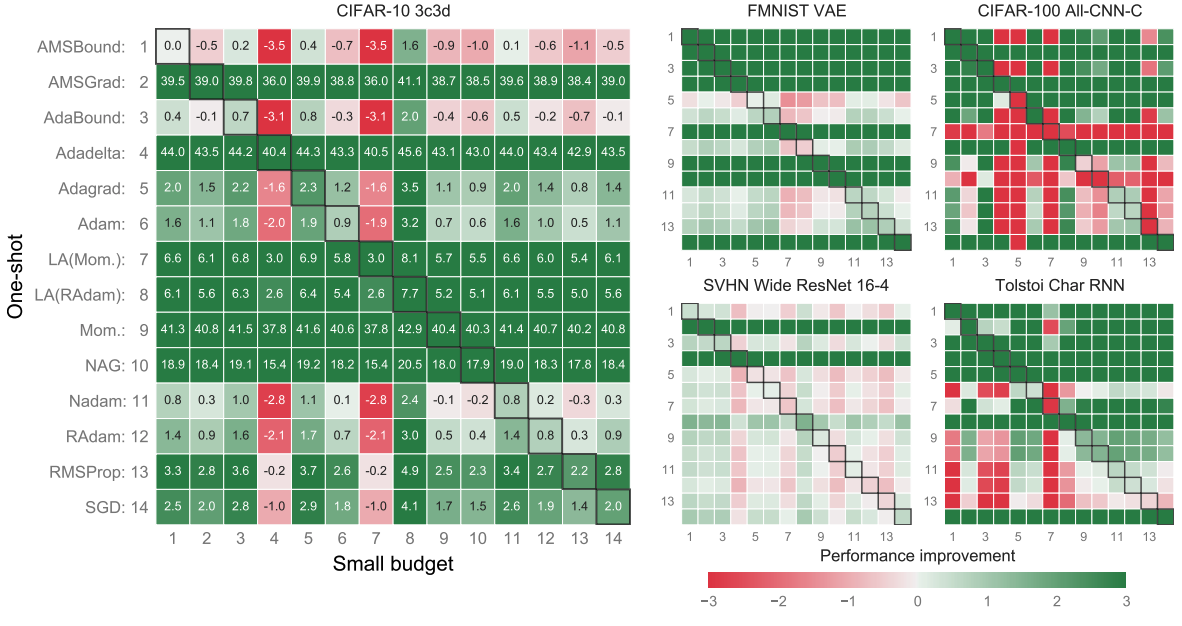 図3. 結果図(チューニングによる差)
図3. 結果図(チューニングによる差)
改善されたものが緑で改善されなかったものが赤で示されます。例えば、問題:CIFAR-10、モデル:3c3dを見てみる(一番左)と一番左下のセルをみるとAMSBound(1)(Small budget)の精度はSGD(14)(One-shot:デフォルト値使用)よりも2.5%以上向上しているということになります。(基本的に最適化アルゴリズムの列を見てください。)
もっとわかりやすいところで説明するとAdadelta(4)(Small budget)は縦に見ていくとほとんどの最適化アルゴリズムのデフォルト使用に劣ります(赤)。しかし、One-shotの7、8、9、10よりは精度が良さそうです。なので横軸基準で見るとは赤い方が精度を向上している意味になるのでAMSBound(1)(One-shot:デフォルト値使用)はほとんどのチューニングした最適化アルゴリズムよりも精度が良いとわかります。
問題基準での結果を図4に示します。
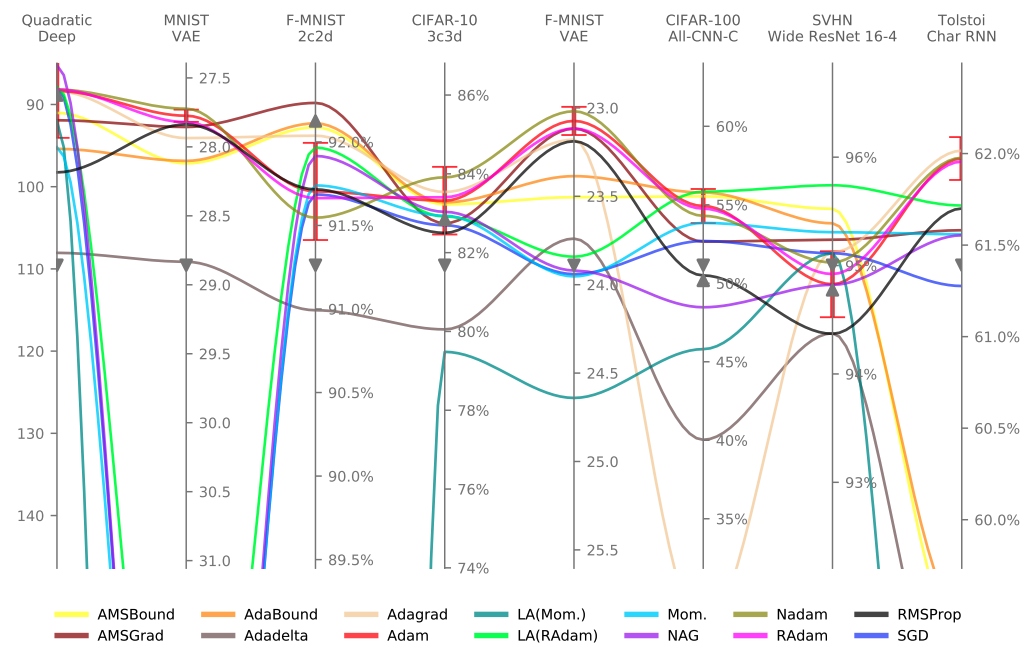
図4. 結果図(問題による差)
大きく性能に差が出ていることからタスクに対する依存性が高い。最適化アルゴリズムがあることがわかります。
まとめ
今回の検討ではまだまだ検討しきったわけではありません。
- 複雑さも大きさも異なるモデルでも同一の結果になるのか。
- モデルによっては今回の最適化アルゴリズムの傾向が変わる可能性があります。
- 最適化アルゴリズムの評価用に標準化された手順とともに、広範囲の深層学習テスト問題を含むDEEPOBSを取組ことで今回の結果をより一般化できるかもしれません。
- フレームワークによっても変わる可能性もあります。
- GANや強化学習のような大きなリソースをとるようなものには今回の検討は一般化できない可能性もあります。
- パラメータの探索手法による違いも検討項目に上がります。
- 再現性の安定性
こんなにもまだまだやることが残っています。しかし、今回の結果はこう言った実務社会エンジニアに対する有効な初見を示す可能性が十分にあります。また、この研究をきっかけに新しいアルゴリズムの提案とともに使用方法まで考えられた提案がされるきっかけにもなります。
もし、最適化アルゴリズムを含めた調整をするのであれば
- 一旦検討する最適化アルゴリズムを選定←ここはタスクと最適化アルゴリズムの依存性があるため重要(しかし、明確な選定手法はない。)
- 基本的には一般的なもの、デフォルト値を使用
- 学習率スケジュールを変更←極端に精度に影響を及ぼす問題もあるため注意
この程度でしか今回の検討からはなんとも言えません。しかし、基本的にはデフォルト値または比較的使われている一般的なものをしようすることをオススメします。他の問題も絡むため、そんなに単純ではないですが研究の精度もチューニングで細かい精度を争うよりもデフォルトで全て比較検討した方が再現性にとってもいいかもしれませんね。




この記事に関するカテゴリー





