データの不均衡を攻略!データの数と分布が違うデータ間での半教師あり学習の手法
3つの要点
✔️少数のラベル付きのデータと大量のラベルなしデータに分布の差があるシナリオを想定するタスクを提案
✔️分布の差を埋めるために、二つの分布の中間的なデータを生成する手法と、分布の差を埋める学習手法を用いる手法を提案
✔️既存の半教師あり学習の手法を大きく上回る精度を達成
半教師あり学習とサンプリングバイアス
半教師あり学習とは、教師あり学習と教師なし学習を組み合わせた学習の方法で、(少数)のラベル付きデータと(大量)のラベルなしデータを用いて、タスクを解けるように学習をするというものです。この学習手法は、ラベルなしデータを大量に集めることはできるものの、アノテーションのリソースを確保できず、少数のサンプルに対してのみしかアノテーションできないようなケースで有用です。具体的な学習アルゴリズムとして、ある規則に基づいて教師なしデータに擬似的なラベルをつけて、その擬似的なラベルを用いて教師あり学習を行うような手法が提案されています。
ですが、実際にラベルが振られているデータが、ランダムにサンプリングされたものではなく、恣意的に選ばれたデータの集合であった場合、データを生成する分布が同じである可能性が高いにも関わらず、ラベル付きデータとラベルなしデータの経験的分布に差が生じてしまいます。つまり、この分布の差を捉えながら学習するアルゴリズムを使用しなければ、データを生成する分布に適合したモデルを学習させることができず、結果として予測精度が落ちてしまいます。
今回ご紹介する手法は、このようなシナリオにおいて、分布の差を埋めるような学習を行い、なおかつラベル付きデータとラベルなしデータの中間の分布から生成されたとみなせるようなデータを作成し、データ拡張することで、精度の向上を実現する、というものです。
提案手法
Adversarial Distribution Alignment
今回は、ラベル付きのデータとラベルなしデータには、分布の差があるというシナリオを想定しています。そのため、特徴量を抽出する際に、二つの経験的分布に依存しない、普遍的な特徴量を抽出することで、予測精度の低下を防ぎます。
普遍的な特徴量を抽出するために、何らかの指標を用いてラベル付きデータとラベルなしデータの特徴量の分布間のダイバージェンスを計算し、それを小さくしながら、予測精度を高めるための教師あり学習を行います。これにより、データを予測するために必要な特徴を捉えながら、二つの経験的分布に依存しない特徴量を獲得することが期待できます、

今回は、このダイバージェンスの指標として、ドメイン適合のタスクで用いられることの多い、H-Divergenceを使用します。$x$を特徴量を抽出する関数$g$に入力した際に得られた出力を、識別器$h$に入力します。$h$は、その特徴量がラベル付きデータの経験的分布 $D_l$から得られたものか、ラベルなしデータの経験的分布$D_u$から得られたものかを識別します。この識別をもっとも正確に行える $h$を求め、その$h$が実際に識別を行なったときの正答数を1から引いて二倍したものが、H-Divergenceです。つまり、特徴量を識別したときに、誤答数が多いということは、二つの分布の特徴量が、どちらの分布から得られたものかを識別することが難しいということになります。これは、二つの分布が近い関係にあると解釈することができます。
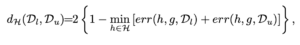

このH-Divergenceを小さくするように関数$g$を選択すれば、経験的分布の差を埋めた特徴量を獲得できることが期待できます。
今回は、関数$g$と$h$をそれぞれニューラルネットワークとし、敵対的学習を用いてこの最小化-最大化問題を解きます。上の式を少し変形して、

を学習することで、特徴量の分布を近づけます。
Cross-set Sample Augmentation
Adversarial Distribution Alignmentを用いれば、ラベル付きデータとラベルなしデータの不均衡を埋めることができます。ですが、ラベル付きデータの数が限られているため、敵対的学習が安定しない可能性があります。そこで、分布の差を埋めることに寄与するようなラベル付きのデータをアルゴリズムによって増やすことで、この問題に対処します。これを、Cross-set Sample Augmentationと呼んでいます。具体的には、以下のような方法で$\tilde{x}$, $\tilde{y}$, $\tilde{z}$を生成します。
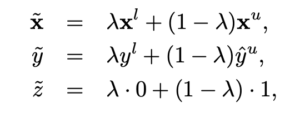
ここで、$x^u$はラベルなしデータ、$x^l$,$y^l$はラベルつきデータとそのラベル、$\hat{y}^u$は、モデルによって得られた$x^u$の予測値を示します。$z$は識別器に与えるラベルを示します。ここでは、ラベル付きデータとラベルなしデータを、$\lambda$の割合で合成し、予測器と識別器に与えるラベルも同じく$\lambda$の割合で生成しています。これにより拡張されたデータセットを用いて、学習を行います。
この方法によって生成されたラベルは、ラベル付きデータとラベルなしデータの経験分布の中間の分布から生成されたデータとしてみなすことが、論文内で証明されています。
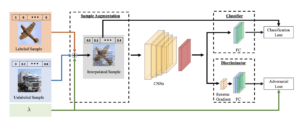
全体のアーキテクチャ
以上をまとめると、このようなアーキテクチャになります。Cross-set Sample Augumentationでデータを生成し、それを用いて予測器(Classifier)を教師あり学習によって学習します。また、同時に、特徴量のレベルでラベルありデータとラベルなしデータのH-Divergenceを最小化するように、識別器(Discriminator)を学習します。
実験
SVHNとCIFAR10のデータセットを用いて画像分類のタスクを通して実験を行なっています。SVHNは、街中にある標識や看板などに書かれた数字が切り取られたラベル付きのデータセットです。CIFAR10は、飛行機や動物など、SVHNと比べてより一般的な画像を対象にしたデータセット群です。これらのデータの一部をラベル付きデータとして扱い、一部をラベルなしデータとして扱います。
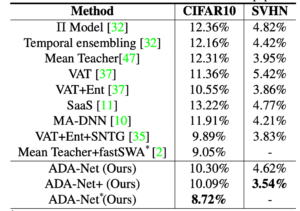
精度検証
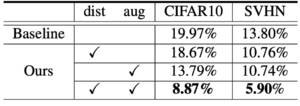
比較した手法は、ラベル付きデータのみで学習したモデルです。精度を比較すると、既存の手法に比べ、ADA-Net(提案手法)が最も高い精度を達成しています。
また、今回提案している二つのアルゴリズムが、どれくらい精度に寄与しているのかを調べるため、比較実験を行っています。ここでも、二つのアルゴリズムを併用しているモデルが、最も高い精度を達成しています。
特徴量の可視化
特徴量の可視化実験においては、ベースラインのモデルから得られる特徴量と比べると、ラベルつきデータとラベルなしデータのデータの分布が非常に近くなっていることがわかります。また、Cross-set Sample Augmentationによって得られたデータも、同様に近くなっています。このことから、Adversarial Distribution AlignmentとCross-set Sample Augmentationを用いることで、特徴量レベルでのデータの分布を近づけることができると言えます。

まとめ
今回は、半教師あり学習において、ラベル付きデータとラベルなしデータの分布に差がある状態を想定して、その差を埋めながら学習をすることができる手法を紹介しました。
現実の世界でも、このような状況に直面することは往々にしてあるので、そういった状況下では非常に扱いやすい手法なのではないかと思います。
ただ、敵対的学習によって分布の差を埋めるアプローチは、Mode Collapseなどの問題に陥る可能性もあるので、より安定するようなDistriburion Alignmentの手法を採用することで、より難しいタスクでも高い精度で学習をすることができるのではないかと思いました。
Semi-Supervised Learning by Augmented Distribution Alignment
written by Qin Wang, Wen Li, Luc Van Gool
(Submitted on 8 Aug. 2019)Accepted to ICCV2019




この記事に関するカテゴリー






