ドメイン適応に強弱をつける?物体検出タスクに適したドメイン適応技術の登場!
3つの要点
✔️物体検出タスクにおける教師なしドメイン適応手法の提案
✔️大域的な特徴量には弱くドメインを適応させ、局所的な特徴量には強くドメインを適応させる
✔️様々な教師なし物体検出タスクにおいて、高性能を発揮
「ドメイン適応」という技術を聞いたことがあるでしょうか。この技術は深層学習を実世界で応用するのに非常に重要な技術です。
近年、人間が行なってきた作業が深層学習技術によって取って代わられようとしています。その代表例として「物体検出」タスクが挙げられます。物体検出タスクでは、画像が与えられ、その画像のどの部分に何があるかを推定します。
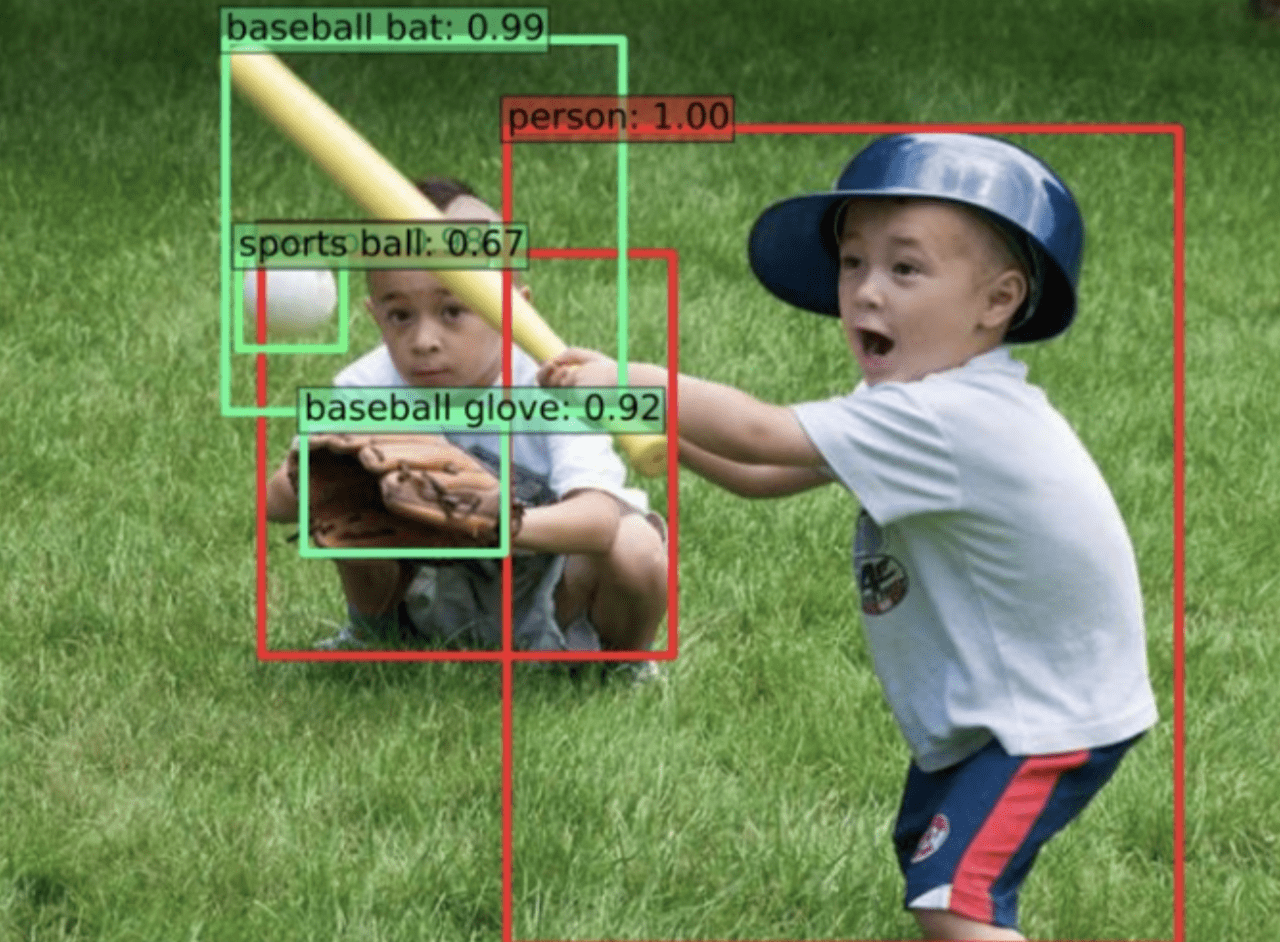
図1. 物体検出の概要
皆さまご存知だと思いますが、深層学習は品質の良い大量の教師データを使って学習を行います。物体検出に関しては、大量の画像と物体がどこにあるか、そしてそれが何のクラスであるのか、を示すラベル情報が必要です。
しかし、いざ学習した物体検出モデルを実世界で応用しようとすると様々な問題が生じます。この1つの原因として、教師データとテストデータに差があるということが挙げられます。
例えば、町中で常時、人がどこにいるか防犯カメラから検知したいとします。そして、晴れた日で人目線から撮ったデータで学習を行ったとします。しかし、実運用ではカメラは人目線ではなく、もう少し高い位置からの角度で人を捉えています。また、晴れた日ではなく、雨の日の場合でも検知を行いたいとします。そのような場合、学習したモデルでは性能が落ちてしまう可能性があります。
このように教師データとテストデータに差があるとモデルの性能が落ちてしまう可能性があります。ここで登場するのが「ドメイン適応」技術です。ドメイン適応技術では、教師データとテストデータの差をなくし、テストデータでも性能発揮出来るようにする技術です。
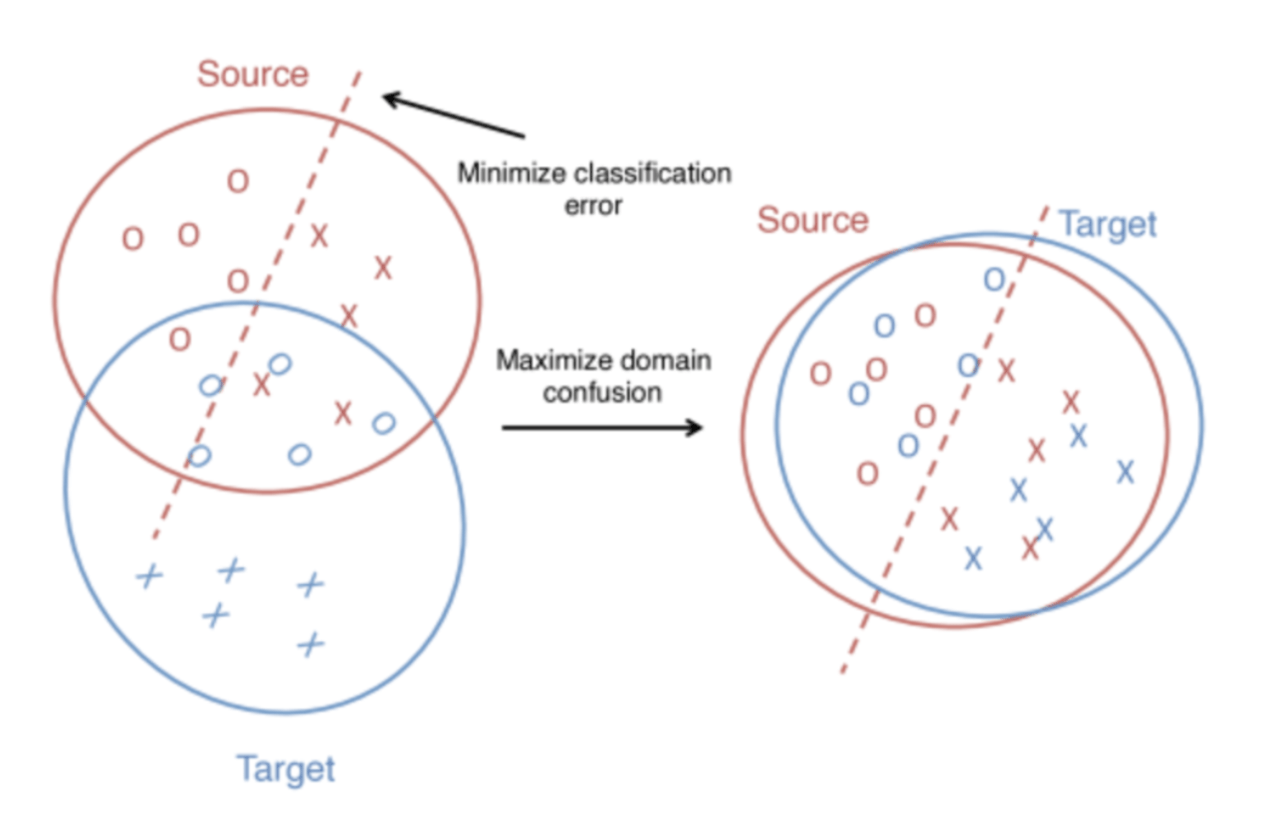
図2. ドメイン適応の概要
従来の物体検出技術で提案されたドメイン適応技術では、教師データ(以降、ソースドメイン)とテストデータ(以降、ターゲットドメイン)の差がほとんどなくなるように学習を行います。(ソースドメインとターゲットドメインを強く一致させます。)
画像認識では判定したい物体はかわらないため、2つのドメインを強く適応させても上手く作用します。しかし、物体検出の場合、背景等の情報まで強く適応させてしまうとターゲットドメインでは性能が落ちてしまう可能性があります。
そこで、本研究では、局所的な特徴(物体情報など)に対しては強くドメイン適応させ、大域的な特徴(背景情報など)に関しては、弱くドメイン適応させる手法を提案しています。
ここでいう、弱くドメイン適応させるとは、すべてのサンプルに対してドメイン適応させるのではなく、一部のサンプルのみドメイン適応を行う、ということです。
適応の概略
本記事で紹介するのは「教師なしドメイン適応」と呼ばれる手法です。これはソースドメインには画像とラベル付きの大量のデータがあり、ターゲットドメインでは少量の画像のみがあるという前提です。
このラベルのついていないターゲットドメインの情報を上手く利用して、ターゲットドメインでも性能が出るように学習していきます。
では、教師なしドメイン適応を行うにはどのようにすれば良いでしょうか。これにはソースドメインとターゲットドメインの分布の近さを測って、その距離を小さくすることでドメイン適応が行えると考えられます。
例えば、ドメイン間の距離を測る指標として、「hダイバージェンス」と呼ばれるものがあります。この指標を例にとって、どのようにドメイン適応を行うか説明します。以下がhダイバージェンスの定義式です。
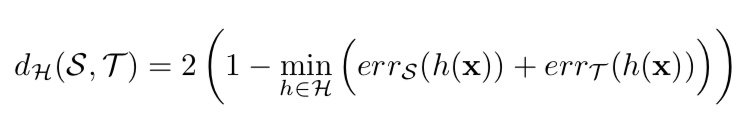
式1. hダイバージェンス
ここで、Sはソースドメイン、Tはターゲットドメインです。また。hは特徴量がソースドメインのものかターゲットドメインのものか識別する「ドメイン識別器」で、$err$はドメインの分類誤差です。
つまり、この指標の最小化は以下のような学習を行えば良いことが分かります。
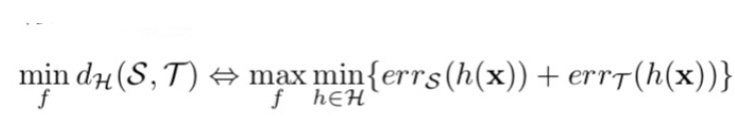
式2. hダイバージェンスの最小化問題
これは画像生成などに良く用いられる「敵対的学習」によって実現できます。敵対的学習を用いて、特徴量抽出器fによって抽出された特徴量が、ソースドメインのものか、ターゲットドメインのものかドメイン識別器が識別出来なくなるように学習します。
この学習により、fがドメイン普遍な特徴量を抽出出来るようになります。このfを使えば、ターゲットドメインでも上手くタスクが行えることが期待されます。
提案手法の概要
ではここから、提案手法を説明していきます。図2は提案手法の概要図です。
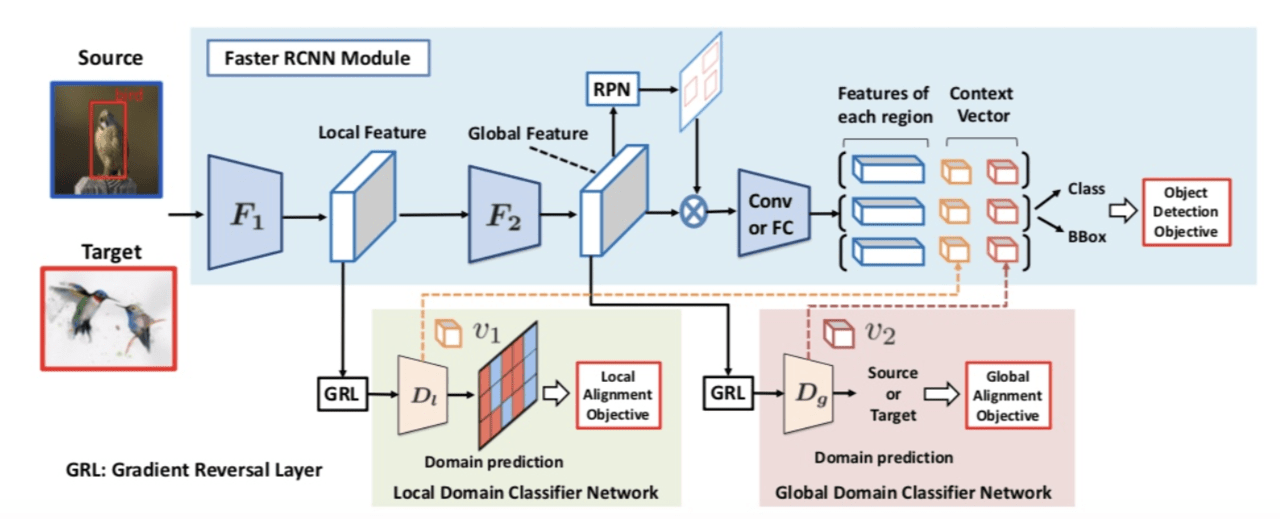
図3. 提案手法の概要図
提案手法の大まかな流れは次のようになります。なお、提案手法ではFaster-RCNN(以下、FRCNN)と呼ばれる物体検出モデルをベースとして、ドメイン適応を行なっています。
(1) 特徴量抽出器F1でソースドメインもしくはターゲットドメインから特徴量を抽出する。
(2) (1)で抽出された特徴量は局所的な特徴量であるので強くドメイン適応させるように学習する。このときドメイン分類器Dlはドメインラベルだけではなく、特徴量v1も出力する。
(3) (1)で抽出された特徴量はさらに特徴量抽出器F2に入力される。F2から抽出された特徴量は大域的な特徴量であるので、弱くドメイン適応させるように学習する。 (2)と同様にドメイン分類器Dgは特徴量v2を出力する。
(4) v1およびv2(以下、context vector(CTX))を最終的な特徴量と組み合わせて検出を行う。
なお、ソースドメインからサンプルされた場合は正解ラベルがあるので、検出損失が計算できます。つまり、敵対的損失と検出損失を同時に最適化できます。一方、ターゲットドメインからサンプルされた場合は敵対的損失のみを考慮し、最適化を行います。
弱くドメイン適応させる手法
ここからは提案手法のメインである弱くドメイン適応させる手法について説明します。
では、弱くドメイン適応させるにはどうすれば良いでしょうか。著者達はドメイン分類誤差を測る指標に問題があると指摘しています。 従来手法ではドメイン分類誤差にクロスエントロピー誤差(以下、CE)を用いています。しかし、図3(右)をご覧ください。
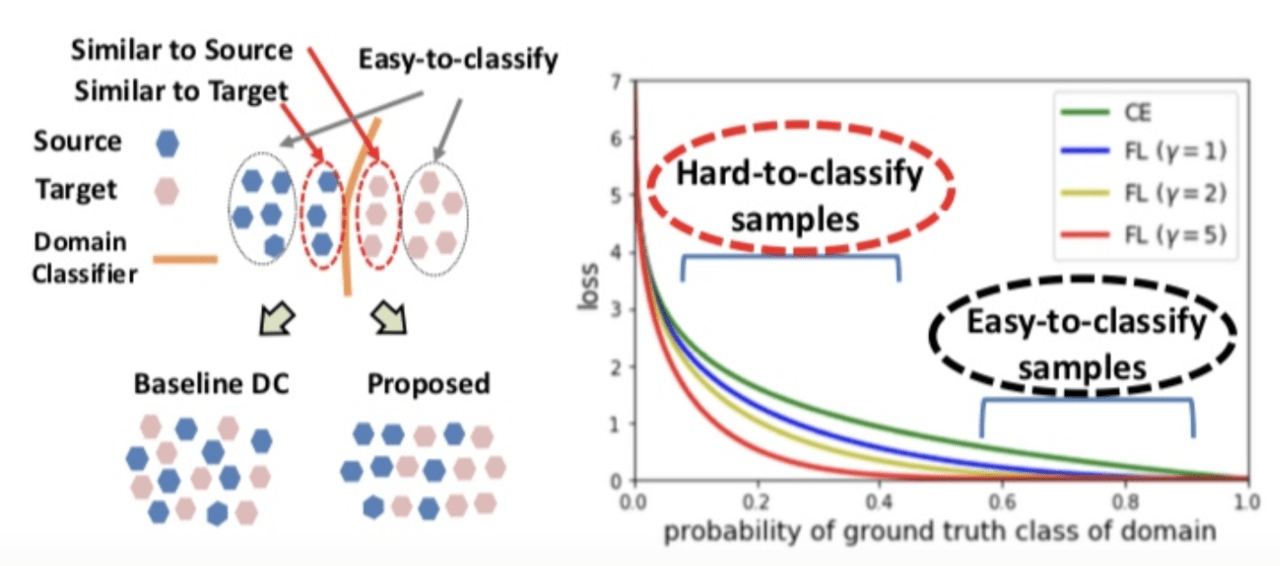
図4.ドメイン分類しやすいサンプル(easy-to -classify)とそうでないサンプル(hard-to- classify)
CEではドメイン分類器の出力値である確率pが高くなっても、損失がある程度残っています。また、図3(左)をご覧ください。確率pが高いということは、ドメイン分類器にとってはそのサンプルは容易に判断出来る(easy-to-classify)ということを示しています。一方、確率pが小さいことは容易には判断できないサンプル(hard-to-classify)であることを示しています。
つまり、CEではeasy-to-classifyサンプルとhard-to-classifyサンプルのどちらに対しても学習を行ってしまいます。本研究ではhard-to-classifyサンプルのみに対して学習を行えるように損失関数を設計しています。図3(右)のFLと記載されている損失関数をご覧ください。これは以下のような損失関数です。
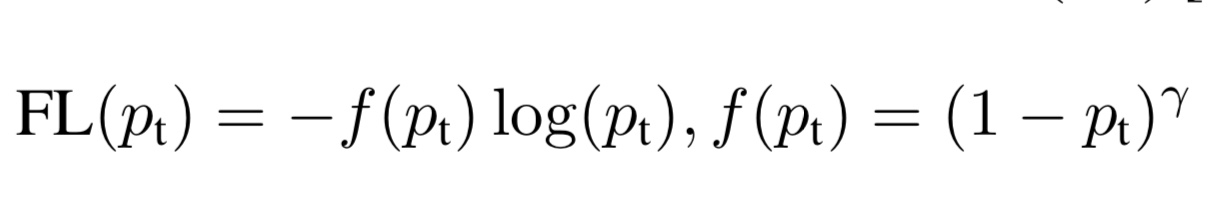
式3. Focal loss
この損失関数は確率pが高いほど、損失がCEに比べ低くなっています。つまり、hard-to-classifyサンプルのみに着目して学習を行うことが可能になります。これにより、ドメイン識別器の決定境界付近のサンプルに対して学習を行うことができるので、効果的に敵対的学習を行うことが可能となります。なお、$γ$はhard-to-classifyサンプルに対して、どれだけ学習を行うか決めるパラメータです。
実験結果
本研究では主に2つの実験を行なっています。①ソースドメインとターゲットドメインが大きく異なる場合です。例えば、実画像と絵のような場合が当てはまります。②ソースドメインとターゲットドメインが近い場合です。これは、天候による差などが例に挙げられます。
ここで、提案手法と比較する手法は以下の3つです。
(1) ソースドメインのみを使って学習させたドメイン適応を行なっていないFRCNN。図中ではSource Onlyと記載されています。
(2) 提案手法と同じアーキテクチャで学習するが、弱いドメイン適応を行う際に損失関数にCEを使用するモデル(BDC-Faster)
(3) DA-Fasterと呼ばれる強くドメイン適応を行った物体検出の従来モデルで、ベースはFRCNN
評価指標はAPもしくはMAPで、高ければ高いほど良い指標です。
では、はじめに①の設定での実験結果を見ていきましょう。使用したデータセットはソースドメインが20クラスの実画像から構成されるPASCAL VOC、ターゲットドメインはCli partと呼ばれるPASCAL VOCと同じクラスを持つ漫画風の画像データセットです。図5が実験結果です。
 図5. ドメインが大きく異なる場合の実験結果
図5. ドメインが大きく異なる場合の実験結果
ここで、Gは大域的な特徴量をドメイン適応しているか、Iはイメージレベルでドメイン適応しているか(DA-Fasterで使用されたもの)、CTXはcontext-vectorを使用したか、Lは局所特徴量をドメイン適応しているか、を示しています。
図5を見てわかるように、提案手法は比較手法より良いパフォーマンスを発揮していることが分かります。BDC-Fasterと大域的なドメイン適応をした提案手法を比較すると、提案手法の方が大4きく性能が向上しています。これは大域的な特徴量に対して、弱いドメイン適応が有効に働いていることを示しています。
またDA-Fasterの結果を見ると、ドメイン適応を行なっていない手法より性能が劣化しています。これはDA-Fasterが強いドメイン適応を行なっていることが原因だと考えられます。
次に②の実験結果を見ていきましょう。使用するソースドメインはCityscapeで、ターゲットドメインはFoggy-Cityscapeです。どちらのデータセットも街の風景のデータセットで、Foggy-CityscapeはCityscapeに霧のノイズを足したデータセットです。図6が実験結果です。
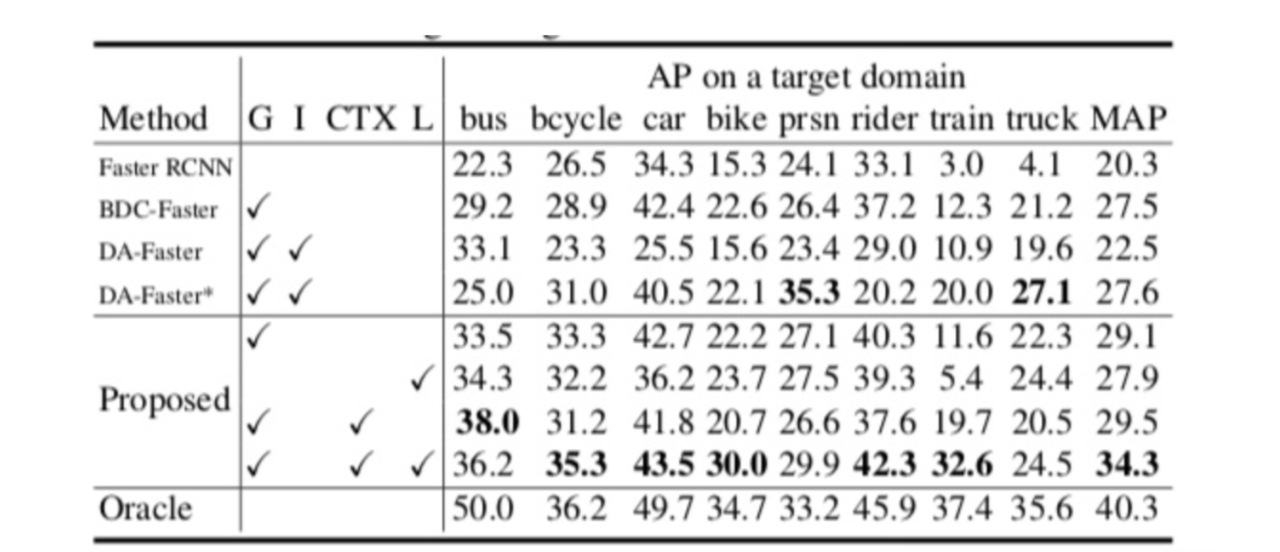
図6. ドメインが近い場合の実験結果
図6によると、提案手法は比較手法よりも優れたパフォーマンスを発揮していることが分かります。なお、Oracleとは教師あり学習を行った場合の結果です。提案手法は教師あり学習に近い性能を発揮していることが分かります。
また以下の図をご覧下さい。
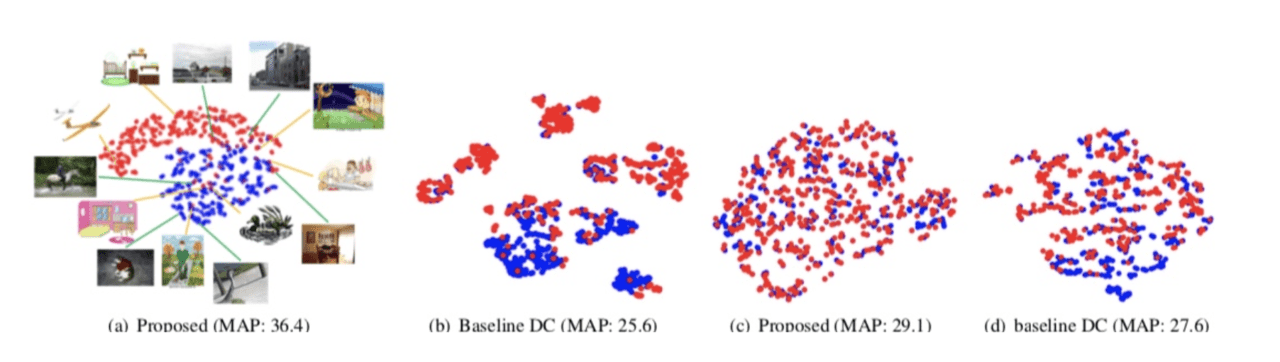
図7. 提案手法によるドメイン適応の結果
図7の左2つはドメインが大きく異なる場合に、ドメイン適応した結果を、そして青色の点がソースドメインを、赤色の点がターゲットドメインを表しています。
図7の一番左が提案手法、その右が比較手法の結果です。比較手法ではソースドメインとターゲットドメインが強く適応されていますが、提案手法は弱く適応されていることがわかります。
また、図7の右2つは比較的近いドメイン間でドメイン適応を行った場合の結果を表しています。この場合においても、提案手法は比較手法のパフォーマンスを上回っています。
まとめ
本記事では物体検出に適応可能なドメイン適応手法を紹介しました。物体検出タスクにおいては、物体レベルでの特徴量に対してはドメイン適応は効果的ですが、背景などの大域的な特徴量に強くドメイン適応させると物体検出のパフォーマンスを下げてしまう可能性があります。
そこで、本研究では物体レベルの特徴量には強いドメイン適応を、そして大域的な特徴量には弱いドメイン適応をさせる手法を提案しました。提案手法による物体検出の実験の結果、従来手法より良いパフォーマンスを得ることができました。これにより、学習済みモデルを別ドメインで活用できる可能性が広がり、ますます深層学習が実応用に近づいたと考えられます。
また、近年CGで作成したモデルで教師データを作成し、そのデータを使ってモデルを学習するという流れがあります。もちろんCGと現実世界は異なるドメインですので、ドメイン適応の技術がより盛んになるのではないかと思います。
本記事は少し理論よりの記事となってしまいましたが、ドメイン適応は深層学習を実応用させるために必要な技術です。この記事がドメイン適応技術の理解にお役に立てれば幸いです。
Strong-Weak Distribution Alignment for Adaptive Object Detection
written by Kuniaki Saitoet al.
(Submitted on 5 April 2019)Accepted by CVPR 2019
Subjects: Computer Vision and Pattern Recognition (cs.CV)




この記事に関するカテゴリー






