Google & Deep Mind 、複数のビデオ内から同じ出来事を抽出する動画解析モデル「TCCL」を発表
動画の持つ情報量は、動画内の物体の一連の動きが意味を持つなど、画像に比べてはるかに大きな可能性を秘めています。しかし、”動画”に対する機械学習の発展はまだその多くが未開拓と言えるでしょう。この記事では、先週Google BrainとDeep Mindが開発した”動画認識”への新たなモデル「Temporal Cycle-Consistency」について紹介します。
参考論文 : Temporal Cycle-Consistency Learning
先週Google BrainとDeep Mindが”動画認識”の新しい論文を発表しました。
この論文では、動画認識の発展として、ある特定の動きをする複数の動画の足並み(動作始めから動作終わりまでの一連の動き)を揃える動画解析モデル”Temporal Cycle-Consistency Learning(TCCL)”を提案しています。
例えば、ピッチャーの投球フォームは、足を振りかぶってからボールを投げるまで、人によって様々です。動き始めの動作も違えば、振りかぶっている時間も異なります。TCLLを用いることで、複数の投球フォームの動き始めから動き終わりまでの行動を全て一律のタイミングで表示させることができます。

技術的課題の一つとして、各フレーム毎のラベル付与における問題があります。これまでの研究でも、動画再生速度の一律化について、動画を画像として区分けして認識させる試みはありました。 しかし、教師あり学習では正解ラベルの入力数が大きくなるため、少ない情報量における動画しか識別することができませんでした。
また、動画の各フレーム毎にどのような動作をしているか、という正解ラベルを付与しようとすると、手作業においては限界がある上、細かな動作の適切な分類が必要となってしまいます。
この研究では、”時間一律化の表現”をいくつかの動画を学習させることによる教師なし学習によって実現します。それらのフレームデータから特徴量を抽出し、最近傍法により動画の各時点における類似度が高い点を同じ動作として認識します。
ここで注目しておくべきは、ただ動画の再生時間を合わせているわけではなく、動画の内容である”投球フォームの動作”が”再生時間内の各点において同じ”という点です。例えば、動画開始から1秒後には振りかぶっており、1.5秒後にはボールが手から離れているといった一律さを保っています。まるでAIが動画の内容を認識しているかのような一律化を再現します。
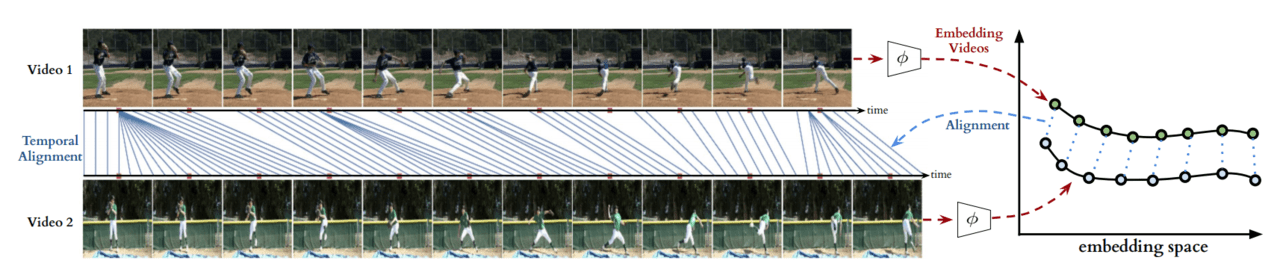
TCLLモデルの概要
今回のモデル「TCLL」では主に、最近傍法のアルゴリズムを用いています。動画の各フレームにおける最近点を見つけることにより、同じ動作が発生しているタイミングを発見し、動画を一律に再生します。
より詳細には、2つのビデオを比較し、一つの動画のフレームにおける最近点と、もう一方の動画の最近点がお互いに同じ分類(cycle consistent)と見なされる場合、同じ動作と判定します。また、これらの最近傍法によって損失関数を最小化する最近点を選び出すことにより、最適化された動画の一律化を再現します。
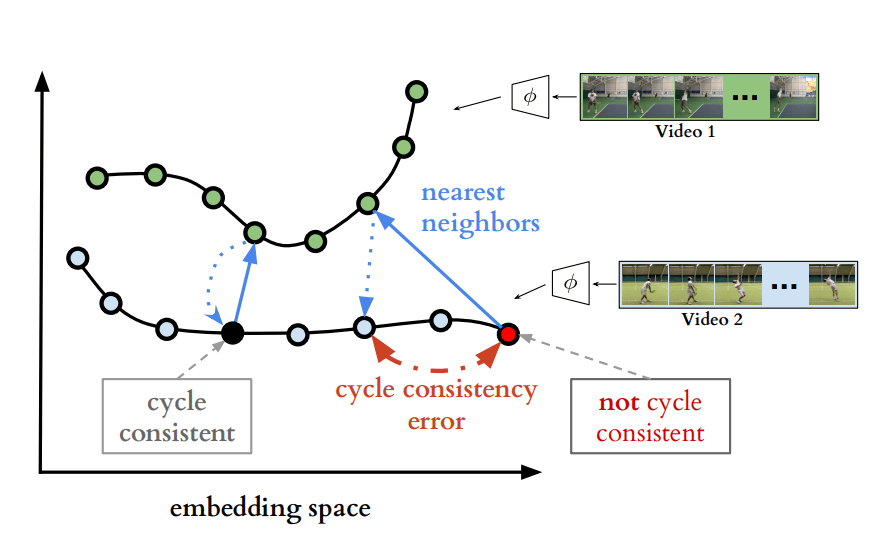
TCLLによる動画の同時再生
テストの一つでは、モデルに103種類の投球フォームデータを学習させました。結果、投球フォームは”動作の始点”,”膝を高く上げる動作”,”腕を伸ばしきる動作”,”ボールをリリースする動作”,”動作の終点”の5つフェイズに分類されています。この分類により失われた情報量は8.18[%]となっており、すなはち、それぞれの動画において91.82[%]は元の動画を正確に再現することに成功しています。
実際に「TCLL」を用いて、ランダムに抽出した49人の投球フォームを一律化し比較したGIFが以下のようになります。メジャーリーガから少年のフォームまで、非常に高い精度で各投球フォームを一律に再生することができています。

今後の展望
動画の持つ情報量は、内容なども含めて画像に比べて非常に豊富であり、それらを活かす技術の発展は今後も期待できます。音声についても同様に時間を一律に対応させることができます。例えば、コップに水を注ぐ2本の動画A,Bを撮ったとして、Aの音声を、あたかもBの音声かのように全く同じ動作のタイミングで移行することができます。
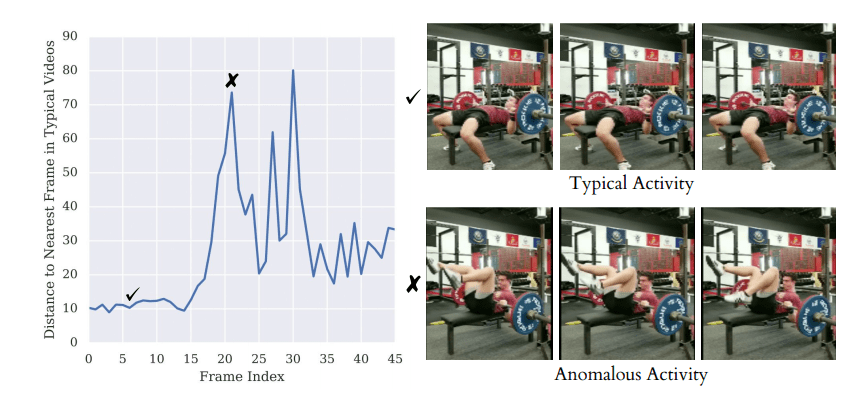
また、応用の一つとして、”異常検知”が挙げられます。下図は、モデルに学習させた複数のウェイトリフティングの動画から一つの動画に注目し、横軸をフレーム数、縦軸を最近点からの距離としたグラフです。下図の✔︎における箇所は正常な挙動を表しており、下図の✖における箇所が他動画と異なる挙動であることを表しています。スポーツにおける細やかなフォーム比較や分析など、実世界への応用が期待されます。
以下はデモ動画になります。



この記事に関するカテゴリー






