蒸留学習の実用化!車内からの視点を直接予測するSemantic Forecastingとは?
論文: Segmenting the Future
Written by Hsu-kuang Chiu, Ehsan Adeli, Juan Carlos Niebles
Status: Submitted on 24 Apr 2019
Subject: Computer Vision and Pattern Recognition (cs.CV)
近年、自動運転の実現が騒がれていますね。
日本では、2020年までに高速道路でレベル3(緊急時のみ人による操作)の実現を目標としています。
自動運転を実現する要素技術の1つにカメラから取得された画像の各画素が何かを推定するSemantic Segmentationがあります。Semantic segmentationを画像に対して行うことで、画像のどこに何が写っているかをAIが理解することに役立ちます。
一方、自動車が例えば40km/hで走っているとしたら、1秒間に約10mを移動しています。人間の脳は、その速度で移動している状態でも、もちろん瞬時に目から取得した映像を処理することができますが、それと同時に、「この車、左に曲がりそうだな」とか、「この人横断歩道渡りそうだから気を付けておこう」といったように環境の数秒後の”未来”を予測し未然に事故を防ぐよう暗に心がけています。
このように、今回は”AI”に数秒後(数フレーム後)の未来の環境がどうなっているかを現在の画像から予測させるタスクを紹介します。もちろん取得してきた画像に対して高精度かつ高速度にSemantic Segmentationを行うことも重要ですが、画像から数秒後の未来の状況を予測できれば、人と同様により環境を理解し、未然に事故を防ぐことができるようになります。

今回は、過去の画像情報から、数秒後(数フレーム後)のSemantic Segmentation画像を予測するタスクを扱います(上図)。
ちなみに、論文中ではこのタスクをSemantic Forecastingと命名しています。
未来のSemantic Segmentation画像を推定した論文はこの論文が初めてではありません(実験のところで比較を行います)。ですが、既存研究では一度未来のRGB画像を予測し、その画像に対してSemantic Segmentationを行っていたり、現在のSemantic Segmentation画像から未来のSemantic Segmentation画像を予測していたのに対し、この論文では過去のRGB画像から「蒸留学習を導入することにより直接Semantic Segmentation画像を予測した点が新しい」と主張しています。
未来予測ネットワーク
入力は時系列のRGB画像、出力は数フレーム後のSemantic Segmentation画像となっています。
各RGB画像から特徴を抽出し、その特徴をForecasting Moduleに入力とします。Forecasting Moduleでは、3次元畳み込み層(画像の縦・横に加えて時系列方向に特徴を畳み込む)を用いて、得られた特徴をデコードすることで、未来のSemantic Segmentation画像を出力します。
また、詳細な境界情報を保持するためにU-NetのようにSkip-Connectionを用いることで、現在のフレームの特徴をデコード部分で再使用しています。
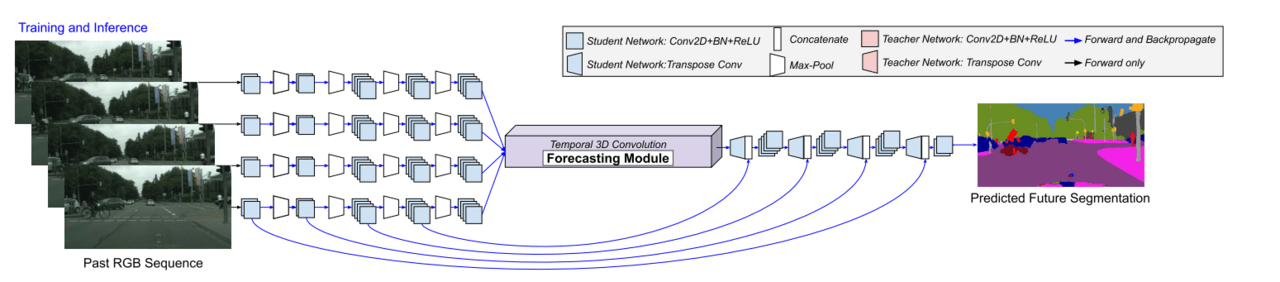
意外とシンプルなものになりましたね。実はこの論文の肝はネットワーク部分ではなく、学習方法にあります。
続きを読むには
(3930文字画像6枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






