
Adversarial Training における過剰適合を防ぐ方法
3つの要点
✔️ 通常学習と Adversarial Training との誤差の挙動の違いを調査
✔️ Adversarial Training では過剰適合が支配的な現象であることが判明
✔️ Adversarial Training での過剰適合には,早期停止が有効であることを示した
Overfitting in adversarially robust deep learning
written by Leslie Rice, Eric Wong, J. Zico Kolter
(Submitted on 26 Feb 2020 (v1), last revised 4 Mar 2020 (this version, v2))
Comments: Accepted to arXiv.
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:
はじめに
近年深層学習では,Double Descentなどの現象により,過剰適合が抑えられるなどが知られ始めています.しかし,敵対的摂動に対してロバストにするための手法である Adversarial Training を行う場合,通常の深層学習とは異なり,過剰適合が支配的な現象であることがわかりました.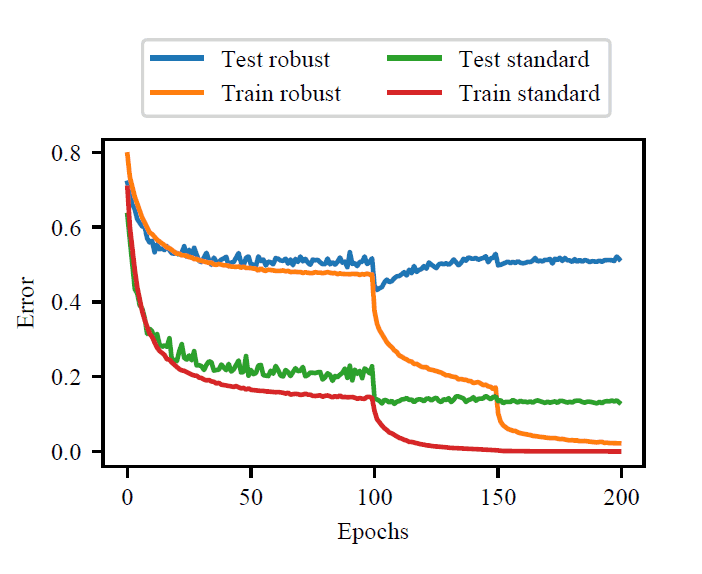
CIFAR-10での学習の一例では,上図に示されている通り,通常の学習 (Train standard, Test standard) は Double Descent が起こっていることが確認できますが,Adversarial Training (Train robust, Test robust) では,学習データに対する損失 (Train robust) は下がり続ける一方で,テストデータに対する損失 (Test robust) はある点以降は増加していくことが確認できます.この例から,Adversarial Training を行う場合,過剰適合が起こっていることが確認できます.
このような Adversarial Trainingにおける過剰適合に対応するには,早期停止が最も有効であることがわかりました.他の正則化手法との比較を行って,早期停止が最も有効であることを示します.
敵対的摂動(Adversarial Perturbation)とは
敵対的摂動
識別モデルが誤認識するように作られた入力データを,敵対的サンプル(Adversarial Examples)といいます.この敵対的サンプルは,通常のデータに対してノイズを乗せることによって作られます.このノイズを敵対的摂動といい,様々なノイズの作り方が考案されています.ノイズを乗せる目的は,誤認識させること,すなわち,正しいクラスに分類した時の誤差を大きくすることです.これは以下のように定式化できます.
$$ max_{\delta \in \Delta}l(f_{\theta}(x_{i} + \delta), y_{i}) $$
ここで$l$は損失関数を表します.この式のように,モデル$f_{\theta}$がデータ$x_{i}$を$y_{i}$と識別するときの損失を最大化するような摂動$\delta$を求めることで,敵対的摂動を作ることができます.この式を解けば敵対的サンプルを作ることができるのですが,人の目で見て敵対的サンプルであるとわかってしまうのは良くないため,なるべく小さな摂動を加えるように,上の最適化問題に制約を加えるのが一般的です.ここでいう摂動の"小ささ"というのは様々な測り方がありますが,摂動のL1ノルム,L2ノルム,L∞ノルムなどを摂動の大きさとして定義し,それを小さくしつつ上の最適化問題を解くのが一般的です.
Adversarial Training
Adversarial Training は,敵対的摂動に対してロバストなネットワークを作るための学習の手法です.通常の学習データに加えて,敵対的摂動によって作られたデータである敵対的サンプルも学習することによってロバスト性を向上させます.定式的には,以下のルールでネットワークのパラメータ$\theta$を更新します.$$ min_{\theta}\Sigma_{i}max_{\delta \in \Delta}l(f_{\theta}(x_{i} + \delta), y_{i}) $$内側の最適化問題である$max_{\delta \in \Delta}l(f_{\theta}(x_{i} + \delta), y_{i})$は,敵対的摂動を作るときに解くべき最適化問題となっており,この部分を最大化するような$\delta$に対して損失を最小化するようなネットワークのパラメータ$\theta$を求めるというのが Adversarial Training となっています.
実験
Adversarial Training における過剰適合を防ぐためには,いくつかの正則化方法が考えられます.この論文では,早期停止のほかに,L2正則化とData augmentation を候補に調査しています.
結果のまとめ
それぞれの詳細に入る前に,先に結果のまとめを掲載します.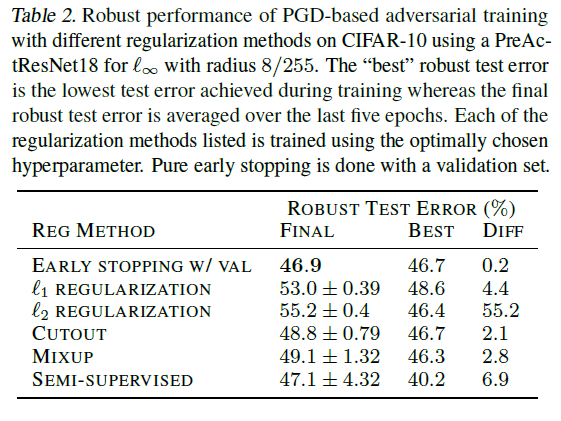
この表を見ると,早期終了がもっともロバストテスト誤差を小さくできていることがわかります.
早期停止
早期停止において問題となるのは,何を基準に停止させるのかということです.そこで筆者たちは,訓練データ,検証データ,テストデータのそれぞれに対して学習曲線を作成しました.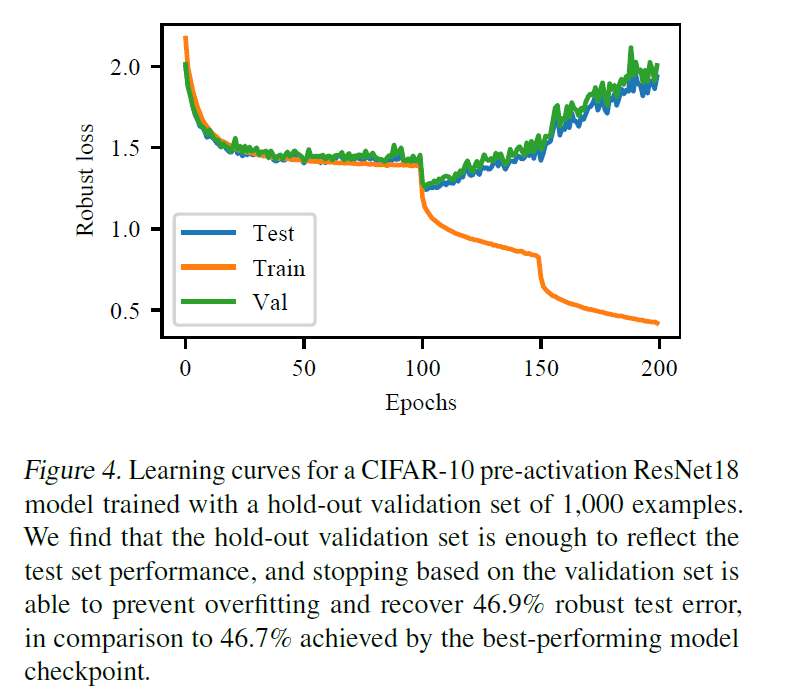
この学習曲線によると,検証データとテストデータに対する損失の変化がほとんど一致していることがわかるので,早期終了を行う際は検証データに対する損失が上がり始めたところで終了すれば,テストデータに対しても損失が小さくすることができることがわかります.
L2正則化
L2正則化の強さを変化させていった時のテストデータに対するロバスト誤差 (敵対的サンプルを含むテストデータに対する誤差) は次の図のようになります.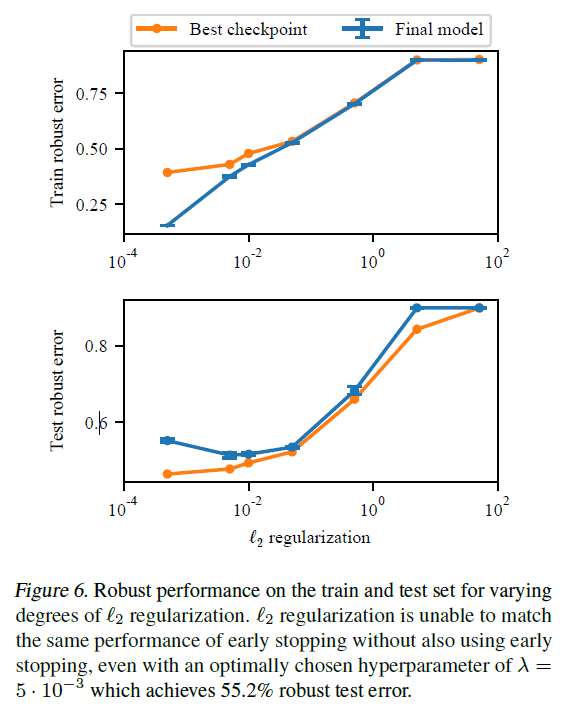
最適なハイパーパラメータを選択した場合で,55.2%のテストデータに対するロバスト誤差を達成しています.しかし,この結果は早期終了には及んでいません.
Data augmentation
Data augmentation の方法として,Cutout, mixup, 半教師あり学習の3つを検討しています.
・Cutout
Cutout のハイパーパラメータである長さを変化させたときのロバスト誤差の変化は次のようになります.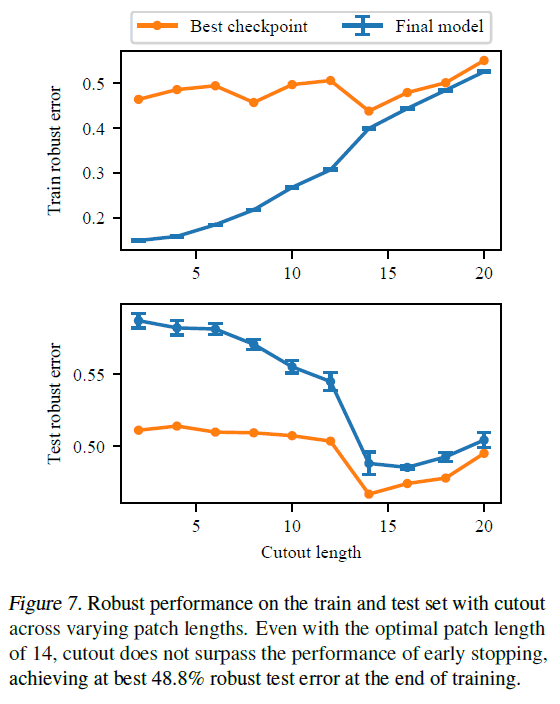
Cutout では,Cutout length を14にした場合がベストスコアで48.8%となっており,これも早期終了には及ばなかったことがわかります.
・Mixup
Mixup においてハイパーパラメータを変化させた場合は次のようになります.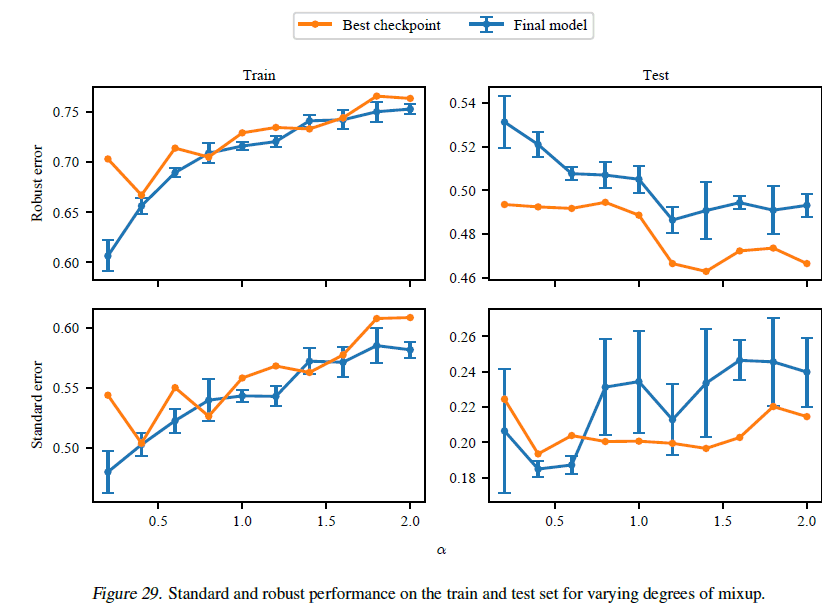
図からわかる通り,Mixup でもハイパーパラメータを変化させても早期終了には及びませんでした.また結果にはある程度の分散があることがわかります.
・半教師あり学習
半教師あり学習でラベル付けを行って学習データを増強した場合,次のようになります.
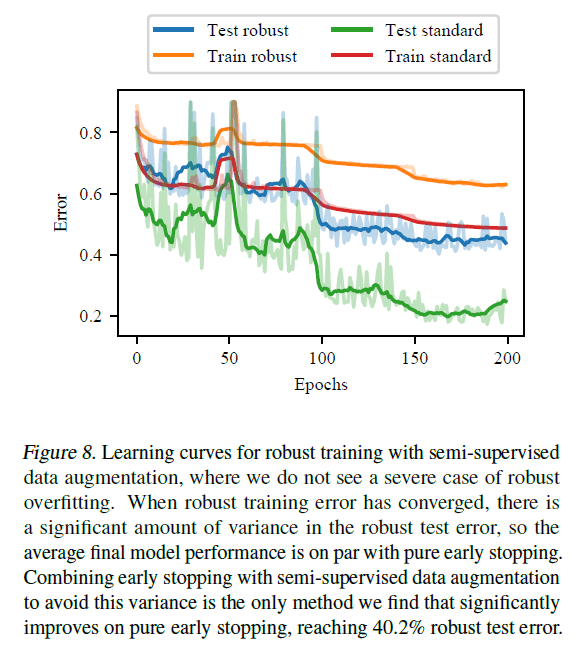
半教師あり学習を用いてデータ増強を行った場合,結果の分散が大きいことが問題ではありますが,平均的なパフォーマンスは唯一早期終了と同程度となりました.半教師あり学習によるデータ増強と早期終了を組み合わせた場合,テストデータに対するロバスト誤差が40.2%に達し,純粋な早期停止を大幅に改善することができました.このため,半教師あり学習によるデータ増強は,単体で比較した際は早期終了には及びませんが,早期終了と組み合わせると大きな効果が期待できます.
まとめ
深層学習における通常の学習と Adversarial Training では,誤差の収束の特性が異なることがわかりました.一般的な正則化手法の多くは,過剰に正則化するか,過剰適合を許してしまいます.しかし,早期終了と半教師あり学習によるデータ増強を組み合わせることで,過剰適合をある程度防ぐことができることがわかりました.Adversarial Training では過剰適合が非常に起こりやすいので,検証データを用いて学習曲線をよく確認することが重要です.





この記事に関するカテゴリー






