脱ReLU!敵対的学習では、滑らかな活性化関数を使うべし!
3つの要点
✔️ 一般的に敵対的学習によって機械学習モデルのロバスト性が向上するが精度が低下する。
✔️ 活性化関数ReLUの非平滑な性質が敵対的学習を阻害していることが明らかになった。
✔️ ReLUを滑らかな関数に置き換えるだけで、計算量や精度を変えずにロバスト性を向上することができた。
Smooth Adversarial Training
written by Cihang Xie, Mingxing Tan, Boqing Gong, Alan Yuille, Quoc V. Le
(Submitted on 25 Jun 2020 (v1), last revised 11 Jul 2021 (this version, v2))
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Neural and Evolutionary Computing (cs.NE)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
画像に摂動(perturbation)を加えた画像は敵対例(adversarial example)と呼ばれ、人間の目には元の画像(註:adversarial exampleの文脈では元画像をclean imageと呼ぶことが多いです)と大きな違いはないが、分類モデルの推論結果を変えてしまいます。

上図が敵対例で、摂動は中央のノイズに見える画像で、敵対例は右の画像です。このように元画像(左)と敵対例はほとんど同じであるにも関わらず、分類結果はパンダからテナガザル(gibbon)に変化してしまいました。
歩行者を認識できる車載AIや乳児を見守るAIカメラなどに対して敵対的攻撃を行うことで、予期しない振る舞いをわざと引き起こすことが可能になります。
敵対的攻撃に対して、あらかじめ敵対例を学習データセットに含めて学習することを敵対的学習といいます。これによりモデルは敵対例が入力された場合にも正しく分類できるようになり、つまりロバスト性を向上させることができます。しかしその一方で、モデルの分類精度自体が低下してしまうということが分かりました。そのため一般的にモデルのロバスト性と精度は両立できないと考えられています。
本論文では、敵対的学習過程の解析によって上記の通説を覆す結果を得ることができました。実は、広く用いられている活性化関数ReLUが敵対的学習を阻害していることが明らかになりました。ReLUの非平滑な性質(non-smooth nature)がその原因であり、ReLUの代わりに滑らかな関数(smooth function)を用いることで精度とロバスト性を両立できることが分かりました。筆者らはこの手法を滑らかな敵対的学習(smooth adversarial training, SAT)と呼んでいます。
背景
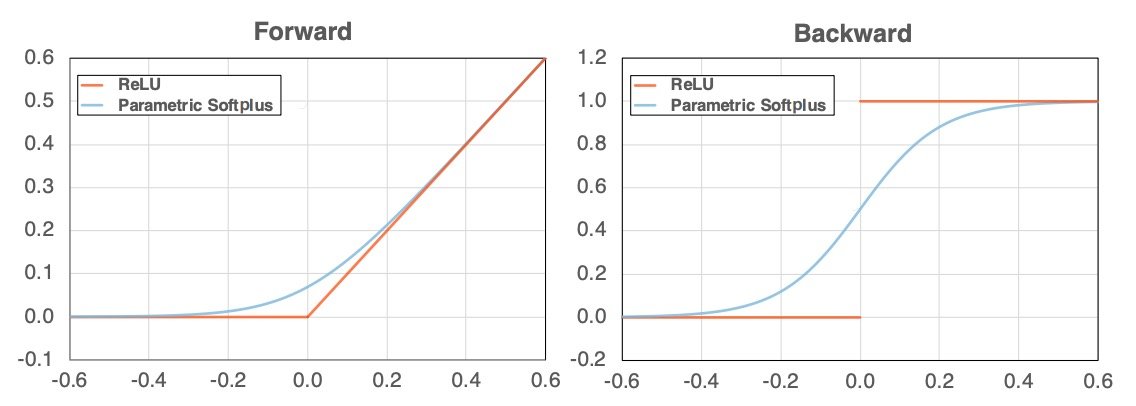
上記のようにReLU(左図のオレンジ)のグラフは、x(横軸)が0の前後で角度を変えます。その結果、微分すれば不連続になります(右図のオレンジ)。本論文ではこの性質のために敵対的学習がうまく機能しないことを示し、ReLUを滑らかな関数に代用するSmooth Adversarial Training(滑らかな敵対的学習、SAT)を提案します。
関連研究
敵対的学習は、敵対例をモデルに学習させることでロバスト性を向上させます。既存の研究では、敵対例に対するロバスト性(adversarial robustness)を向上させるためには、元画像(clean image)での精度を犠牲にするか、あるいは勾配マスキングのように計算コストを高める必要があります。この現象は、敵対的ロバスト性の" No Free Lunch(タダ飯なし)"(註:あちらを立てればこちらが立たず。得しかしない解決法はないということ)と呼ばれています。しかしながら本論文では、滑らかな敵対的学習によってタダ(for free)でロバスト性を高めることができます。
敵対例で学習する以外にロバスト性を高める方法として、防御的蒸留(defensive distillation)、勾配離散化(gradient discretization)、動的ネットワークアーキテクチャ(dynamic network architectures)、ランダム化変換(randomized transformations)、敵対的入力ノイズ除去/敵対的入力精製(adversarial input denoising/purification)などが報告されています。しかしこれらの方法では勾配の質が変化してしまい、勾配降下法がうまく機能しない可能性が指摘されています。
ReLUによる敵対的学習の弱体化
本節では一連の実験によって、勾配計算(逆伝播)パスにおいてReLUが敵対的学習を阻害するのか、そして逆に滑らかな関数が敵対的学習を強化するのかを示します。敵対的学習は以下の式に表す最適化問題と考えることができます。
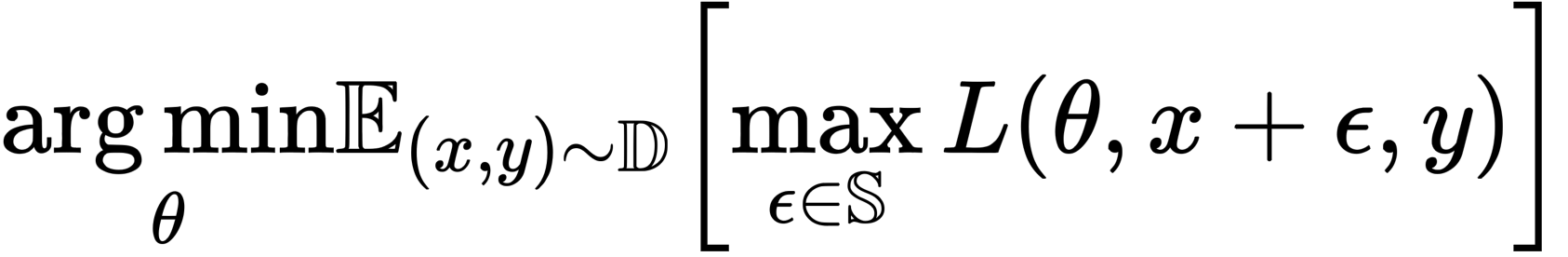
ここでDはデータ分布、Lは損失関数、θはネットワークパラメータ、xは訓練画像、yは正解ラベル、εは摂動、Sは摂動範囲です。なお摂動が人間に知覚されないように、Sはなるべく小さい値に設定されます。
上記の式に示すように敵対的学習は、敵対例による損失を最大化する方向性(内側)とモデル全体の損失を減らすためパラメータを更新する方向性(外側)の2つのパートに分かれます。
なお本研究では、ベースモデルとしてResNet-50を使用し、デフォルトでは活性化関数にReLUを用います。そして攻撃方法としてPGD攻撃(projected gradient descent attacker)のシングルステップ(学習により次第に強力な敵対例を作るのではなく、1度生成するだけの計算コストの少ない方法)を採用します。このPGD-1で作られた敵対例を学習します。
なおPGDとは最適化手法の1つで、摂動を計算する際に用いられます。摂動によって敵対例が生成されるわけですが、敵対例が自然に見えるように訓練データ分布内に収まるようにしなければいけません。そのため「不自然にならない」範囲で「最適な摂動を加える」という制約付き最適化を行う必要があり、それを行うのがPGDです(註:PGDは敵対的攻撃の文脈で頻出するので敵対例の生成方法と思われがちですが、最適化手法の一つです)。
次に、評価手法としてPGD-200を使用します(敵対例を作るにも機械学習を行い、損失が最大化するように200回摂動を更新します)。なお200回の攻撃の更新は、検証として十分であると考えられています。

上記が結果の概要です(表1)。先に述べたように、敵対的学習は①敵対例を強化する学習(2列目、for the adversarial attacker)と②モデル全体の損失を小さくする学習(3列目、for the network optimizer)に分かれています。
まず敵対的学習をしなかったResNet-50にPGD-200攻撃を行うと、精度が68.8%になりロバスト性は33%でした。これに対してネットワーク最適化時にReLUからParametric Softplus関数に置き換えるとロバスト性は1.5%改善していることが示されています。
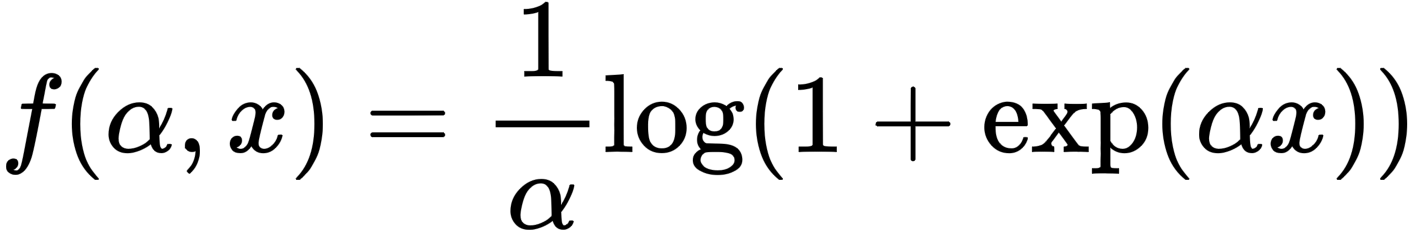
Parametric Softplus関数を上記に示します。アルファは任意の数です。
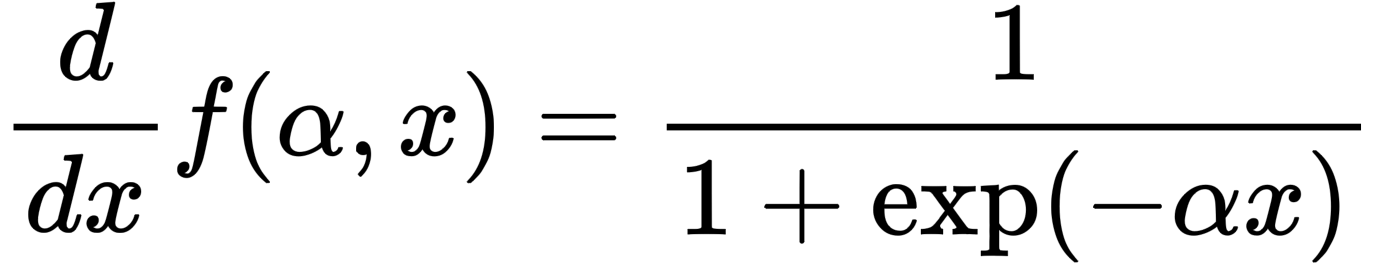
微分したものが上記です。ReLUとは異なり、以下に示すように導関数も連続(青色)です。
敵対的学習は、①敵対例による損失の最大化(強力な敵対例の生成)と②モデル全体の損失の最小化(強力な敵対例でも誤分類させない)の2パートに分かれています。まず①強力な敵対例の生成に関して、ReLUが不向きであると著者らは指摘しています。
なぜなら敵対例の生成には勾配計算が必要になりますが、x=0前後でReLUの出力は急激に変化します。その結果、摂動計算時に大きく値が変化するため、より強力な敵対例を学習する過程をReLUが弱体化させてしまいます。そこで著者らは、ReLUを近似した滑らかな関数であるParametric Softplusを提案しました。なおαは任意ですが、ReLUにより近似するようにα=10と経験的に定義されています。
敵対的攻撃者(adversarial attacker)のための勾配品質(gradient quality)向上
まず①学習時の敵対例計算(= 内側最大化ステップ)に対する勾配品質の効果について見てみましょう。内側最大化ステップは以下の式で表されていましたね。
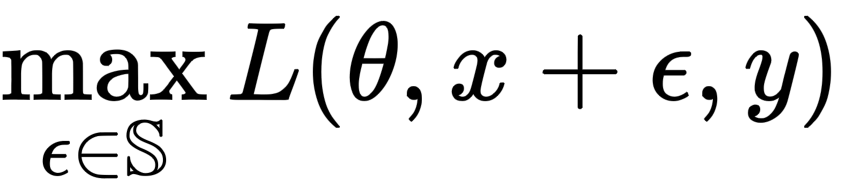
このステップではより強力な敵対例を生成するわけですが、敵対例の生成には勾配計算が必要になります。このときにReLUではなく、Parametric Softplus関数を用います。
正確に言えば、敵対例を生成するための学習時において、順伝播でReLUを使い、逆伝播にはParametric Softplusを使います。そしてモデル全体としての学習(敵対的学習)では順伝播も逆伝播でもReLUを使います。その結果、ロバスト性は1.5%向上しますが、精度は0.5%低下しました(表1)。
Smooth Adversarial Training
前節では、逆伝播時に滑らかな関数を使用するとロバスト性が向上することを示しました。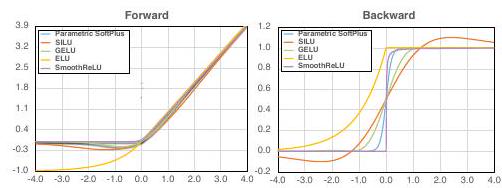
ここではいくつかの滑らかな関数を挙げ、それぞれで検証します。
Softplus
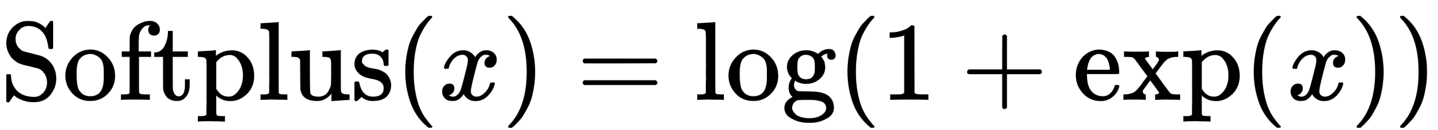
SILU
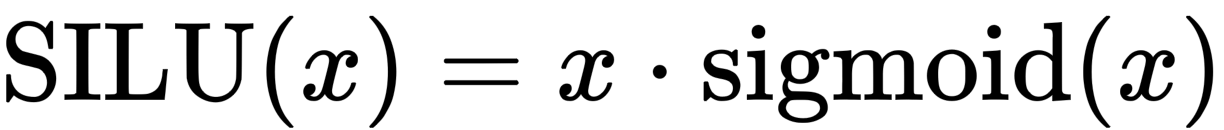
Gaussian Error Linear Unit(GELU)
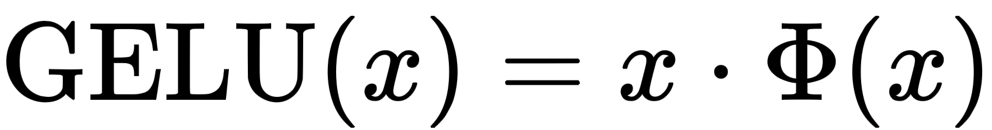
Φは、標準正規分布の累積分布関数です。
Exponential Linear Unit(ELU)
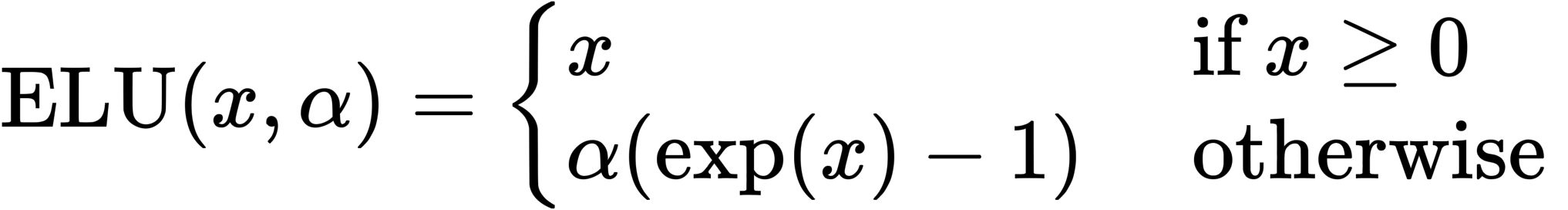
今回はα=1としています。というのもαが1以外のときには導関数が不連続になるためです。
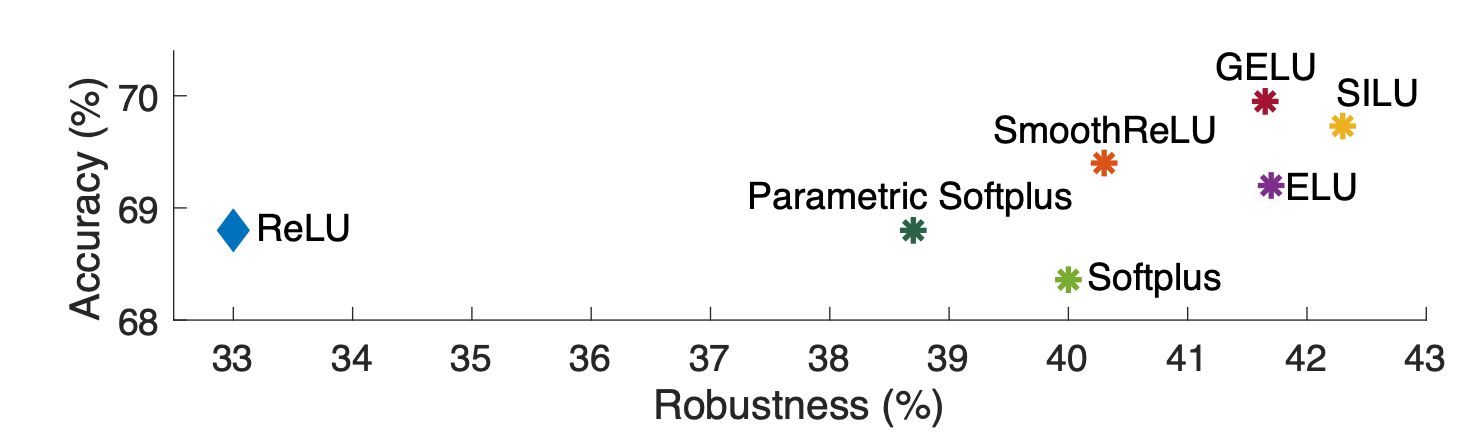
結果は上記のとおりです(図3)。最もロバスト性が高いのはSILUで、ロバスト性は42.3%、精度は69.7%を達成しました。今回使用したもの以外でより良い平滑化関数を用いればさらに結果が向上するものと考えられます。
結論
本論文では敵対的学習において活性化関数を滑らかな関数に置換したSmooth Adversarial Trainingを提案しました。実験によりSATの有効性が実証され、精度およびロバスト性において既存研究を大きく上回りました。






この記事に関するカテゴリー






