敵対的攻撃から見た、一般的な画像分類モデルと医療用画像分類モデルの違い
3つの要点
✔️ 深層学習に基づく医療用画像解析に対する敵対的な攻撃の問題を調査
✔️ 医療用画像とDNNモデルの特性から、医療用画像分類モデルは敵対的攻撃に対して非常に脆弱である
✔️ 驚くべきことに、医療用画像に対する敵対的攻撃の検出は非常に容易で、0.98以上の検出AUCを達成
Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems
written by Xingjun Ma, Yuhao Niu, Lin Gu, Yisen Wang, Yitian Zhao, James Bailey, Feng Lu
(Submitted on 24 Jul 2019 (v1), last revised 13 Mar 2020 (this version, v2))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Image and Video Processing (eess.IV)
code:
研究概要
近年AIモデルに対する攻撃として、敵対的攻撃というものが発見されました。この攻撃は、AIモデルへの入力データに細工をすることで、AIモデルに不適切な出力をさせるというものです。この分野の研究は非常に盛んにおこなわれていました。しかしデータセットとして想定されているもののほとんどが、一般的な画像となっていました。そこで著者らは、データセットの違いによって敵対的攻撃はどのような挙動を示すかを調べるため、データセットとして医療用画像に焦点を当てました。
本論文では、医療用画像に対する敵対的攻撃の性質を調べ、医療用画像分類モデルは敵対的攻撃に非常に脆弱であることを示しています。また、医療用画像分類モデルが敵対的攻撃に脆弱である一方、その攻撃を検知することが意外にも容易であるということも示しました。著者らは、これらの通常画像分類モデルと医療用画像分類モデルの違いは、医療用画像とDNNモデルの持つ特性に依るものであると主張しています。
関連研究
敵対的攻撃(Adversarial Attack)とは
敵対的攻撃とは、入力データに細工をして、攻撃対象のモデルに誤った出力をさせるような攻撃です。入力データに対して、敵対的摂動と呼ばれるノイズを加えることで攻撃を行います。詳細は以下の記事をご覧ください。
Adversarial Training における過剰適合を防ぐ方法
医療用画像解析
診断系の手法のほとんどは、眼科、皮膚科、放射線科などのさまざまな画像をCNNに入力し、特徴を学習しています。ここで使われているCNNは、AlexNet、VGG、Inception、ResNetなどの当時存在していた最先端のものです。これらの手法は標準的なコンピュータビジョンによる物体認識と同様に優れた成果を上げていますが、透明性に欠けると批判されています。ディープラーニングを利用したモデルではその性質上、推論を検証することは現状難しいため、敵対的サンプルの存在によってモデルの信頼がさらに損なわれる可能性があります。
医療用画像に対する敵対的攻撃の分析
それでは、医療用画像に対して一定の成果を上げているDNNモデルに対する攻撃の結果を示していきます。
攻撃の設定
攻撃の種類としては次の4種類の攻撃を想定しました。
- FGSM
- BIM
- PGD
- CW
これらの攻撃はすべて、データに乗せるノイズの大きさを設定してから敵対サンプルを生成します。そのため、小さいノイズでも攻撃が成功すれば、その攻撃対象は脆弱であると考えられ、逆に大きなノイズでないと攻撃か成功しない場合は、その攻撃対象は頑健であると考えられます。
2値分類のデータセットでの結果

二値分類のデータセットでの結果は上のようになりました。概ね予想通り、大きなノイズを加えた場合は通常の画像と同様に、精度が大きく低下しています。ただし、CIFAR-10やImageNetなどの通常の画像データにおいては攻撃が成功するノイズの大きさは$\epsilon = \frac{8}{255}$なので、$\epsilon = \frac{1}{255}$程度で攻撃が成功している医療用画像は比較的脆弱であることがわかります。
多値分類のデータセットでの結果
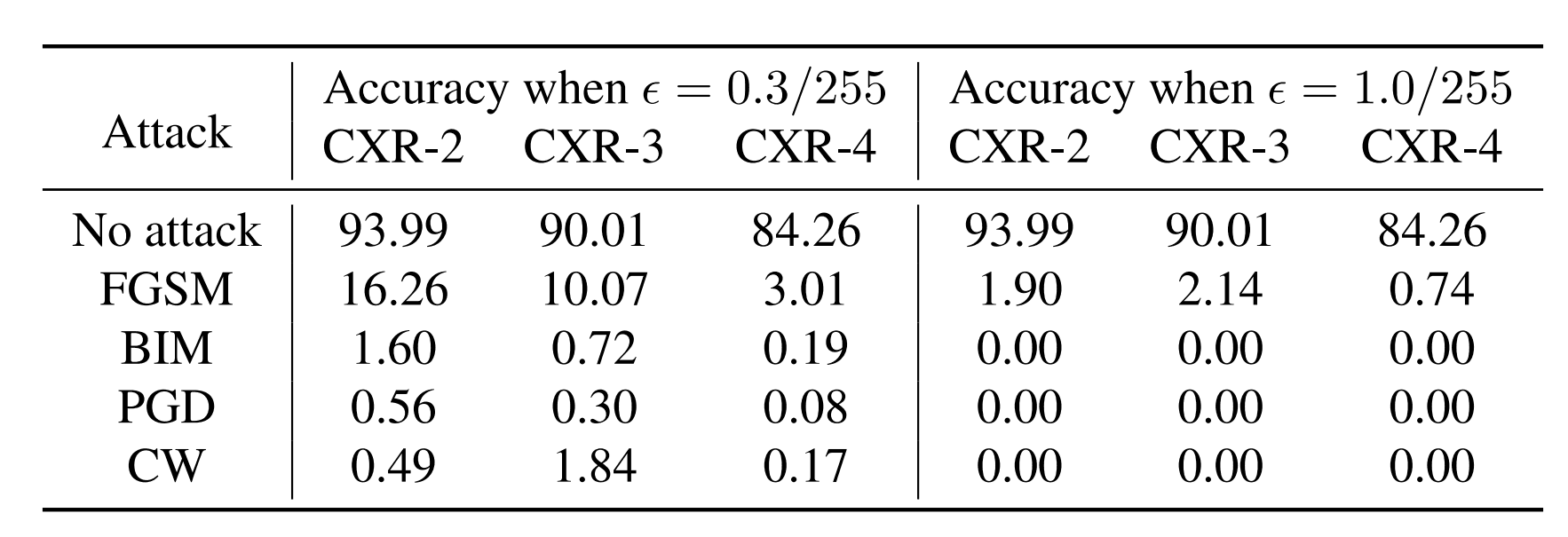
多値分類のデータセットでの結果は上のようになりました。CXR-2やCXR-3の数字の部分はクラス数を表しています。そのため、CXR-2は二値分類、CXR-3は三値分類となります。クラス数が多いほど攻撃の成功率は高くなります。同じノイズの大きさ同士を比べたとき、クラス数が多いほど精度は低くなっていることがわかります。医療用画像である今回のデータセットでは、$\epsilon = \frac{0.3}{255}$という非常に小さい値でも攻撃が成功しているため、医療用画像が非常に脆弱であることがわかります。
なぜ医療用画像がImageNet画像よりも脆弱であるのでしょうか。画像サイズは同じであるため、非常に興味深い事実です。これから、この現象をより深く考察してみます。
なぜ医療用モデルは脆弱なのか?
医療用画像の分析

通常の画像と医療用画像の顕著性マップを示したものが上の図のようになります。通常の画像では、顕著性マップにおいて注目度が高い部分は狭い範囲に集中していますが、医療用画像は広範囲に広がっていることがわかります。敵対的攻撃は画像の全体にノイズを乗せるので、同じ大きさのノイズを乗せた場合、医療用画像のほうが注目度が高い部分により大きな割合でノイズが乗ることになります。これが医療用画像としての敵対的攻撃に対する脆弱性につながっていると考えられます。しかし、通常の画像にもこのような顕著性マップになるようなものも当然存在しているため、完全な原因と断定することはできませんでした。
DNNモデルの分析
医療用画像に対するタスクを行うDNNの構造は、ResNetなどの通常画像に対して大きな成果を上げたネットワーク構造を利用しています。これらのネットワークは、単純な医療用画像解析タスクにおいては過剰に複雑であり、それが脆弱性の一つの原因となっていることを示します。

上図の三行目はResNet-50の中間層で学習された表現を表しています。驚くべきことに、医療用画像の深層表現は、通常の画像と比べて非常に単純であることがわかります。これは、医療用画像では、DNNモデルが広い注目領域から単純なパターン(おそらく病変部にのみ関連するもの)を学習していることを示しています。
上の考察で、医療用画像の分析においては単純なパターンを学習すればよいことがわかりました。単純なパターンの学習には、複雑なDNNモデルは必要ありません。そこで著者らは、個々の入力サンプルの損失分布を調査することで、高い脆弱性が過度にパラメータ化されたネットワークの使用に起因するかどうかを調べることにしました。

上の図は、入力画像に対する損失分布を可視化したものです。通常の画像はなだらかな損失分布を示しているのに対して、医療用画像は比較的急峻な分布となっています。医療用画像はシャープに損失が下がっている場所以外の損失は大きい値となっているため、敵対的攻撃に脆弱になります。このような現象はタスクに対してオーバーパラメータ化されたネットワークを使うことによって引き起こされます。
よって、DNNモデルの観点から医療用モデルの脆弱性を考えた場合、オーバーパラメータ化されたモデルの使用が原因であることがわかります。
医療用画像に対する攻撃検知

上図のような流れで敵対サンプルの検知を行います。医療用画像分類モデルの中間特徴量を利用して分類器を作成しました。その結果は以下のようになりました。

三種類のデータセット(Fundoscopy, Chest X-Ray, Dermoscopy)に対して、4種類の攻撃を行った場合の結果を示しています。通常の画像の場合、AUCは0.8未満となる場合がほとんどであるのに比べて、医療用画像の場合は、高いAUCを示しています。特に、KDベースの検知器の場合、すべてのデータセット、攻撃に対して非常に高いAUCを示しています。DFeatは深層特徴量のみを使う場合なのですが、この場合でも非常に高いAUCを達成していることから、敵対サンプルと通常のサンプルでは深層特徴量が根本的に異なる可能性があることがわかりました。
深層特徴量の分析

通常のサンプルと敵対的サンプルの深層特徴量を比較するため、t-SNEを用いて可視化した例が上図になります。このように可視化すると、通常のサンプルと敵対的サンプルは特徴量に大きな違いがあることがわかります。通常の画像データセットの場合はt-SNEを使ってもこのようにきれいに分離されにくいため、医療用画像の深層特徴量は性質が異なることがわかります。
まとめ
本論文では、医療用画像分類モデルの敵対的攻撃に対する脆弱性について調べました。その結果、医療用画像分類モデルは通常画像分類モデルに比べて非常に脆弱であることがわかりました。しかし、医療用画像は攻撃検知が通常画像よりも容易であることも明らかになり、これが医療用画像に対する敵対的サンプルの深層特徴量と通常サンプルの深層特徴量が、通常画像のそれらよりも分類しやすいものになっていることが原因であることがわかりました。これらの知見は、医療用画像分析モデルの信頼性の担保に大きく貢献しています。





この記事に関するカテゴリー






