特征表达式应该是低维的?
三个要点
✔️ 一般表征学习从高维输入获得低维表征。
✔️ 提出一种从低维输入中获得高维表示的方法,该方法不受刻板印象的影响。
✔️ 与现有的强化学习相结合,提高了连续控制任务的性能。
Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?
written by Kei Ota, Tomoaki Oiki, Devesh K. Jha, Toshisada Mariyama, Daniel Nikovski
(Submitted on 3 Mar 2020 (v1), last revised 27 Jun 2020 (this version, v2))
Comments: Accepted at ICML2020
Subjects: Machine Learning (cs.LG); Robotics (cs.RO); Machine Learning (stat.ML)
Paper Official Code COMM Code
介绍:
深度学习中最关键的问题是表征学习,从原始输入数据中提取重要特征,获得对解决任务有用的潜伏表征。
举个例子,比如说你想让人工智能玩一个闯关游戏。在这种情况下,输入数据将是高度和宽度为几十到几百个像素的RGB图像,输入尺寸的数量将是几千到几万。深度强化学习不使用这样的高维数据,因为它是。首先,利用CNN等提取重要特征,然后转化为维度较少的潜伏表示。然后利用这种低维度的表示方式进行有效的学习。直观地讲,解决块状物塌陷的关键,应该是块、球、杆的位置要操控。
换句话说,高维输入在使用它来解决任务时存在很多问题,比如包含很多不必要的数据,没有组织重要的信息。所以使用表征式学习是很重要的,它可以正确地获取解决任务所需的信息。典型的表征学习从高维输入数据中检索出低维的潜在表征。就像前面的例子一样,它主要是将笨重的高维数据转化为低维的、可处理的数据。
那么,如果另一方面,你从低维输入数据中得到一个高维的潜伏表征,会发生什么?
换句话说,输入的高维潜伏表征对解决任务有用吗?
这里介绍的论文是一项研究,它对深度强化学习中的表征学习这一问题做出了肯定的回答。
OFENET(提案方法)
在强化学习中,代理在某个时间$t$从环境中接收到观测值$o_t$和奖励$r_t$,并选择一个动作$a_t$。
本文提出的在线特征提取器网络(Online Feature Extractor Network,OFENet)方法,将观测值$o_t$和动作$a_t$作为输入,得到高维观测表示$z_{o_t}$和观测-动作对表示$z_{o_t,a_t}$。
当我们实际执行强化学习任务时,他们使用的是OFENet的单独强化学习算法。
但是,这种强化学习算法使用OFENet得到的$z_{o_t}$,$z_{o_t,a_t}$代替观测值$o_t$和动作$a_t$。
Architecture
OFENet的架构如下

如图所示,观测值$o_t$通过参数$θ_{φ_o}$的映射$φ_o$转化为观测表示值$z_{o_t}$,动作$a_t$通过参数$θ_{φ_{o,a}}$的映射$φ_o$转化为观测表示值$z_{o_t}$。同时,通过参数为$θ_{φ_{o,a}}$的映射$φ_{o,a}$,将观测表示$z_{o_t}$和动作$a_t$转化为观测-动作对表示$z_{o_t,a_t}$。
这可以用一个公式表示如下
$z_{o_t} = φ_o(o_t)$。
$z_{o_t,a_t} = φ_{o,a}(o_t,a_t)$。
这些映射$φ_o$,$φ_{o,a}$利用了DenseNet调优的MLP-DenseNet。
在MLP-DenseNet中,每层的输出$y$为$y=[x,σ(W_1x+b)]$,即输入$x$与权重矩阵$W_1$和输入$x$的乘积的连词($[x1,x2]$为连词,$σ$为激活函数。偏偏就省略了)。)
换句话说,DenseNet的卷积运算被MultiLayer Perceptron取代。所以,和DenseNet一样,下层的输入和输出都包含在最终的输出中。在他们的实验中,除了MLP-DenseNet和MLP(通常的多层感知器),他们还使用了ResNet调优的MLP-ResNet,它和MLP-DenseNet一样,用多层感知器代替了ResNet卷积运算。格式。
分销班次
FENet与强化学习算法同时训练。因此,随着OFENet的训练,强化学习算法的输入分布可能会发生变化。这就是所谓的分布转移,众所周知,这是强化学习中的一个严重问题。(AI-SCHOLAR在本篇和其他文章中都有提到)。
为了缓解这个问题,他们使用批量归一化来抑制分布的变化。
辅助任务
强化学习算法的目标是学习能使累积报酬最大化的措施。OFENet需要学习高维度的状态和行为表示来帮助它学习这样的措施。为此,他们使用一个辅助任务,将观察/行为表示$z_{o_t}$,$a_t$作为输入,并预测下一个观察值$o_{t+1}$。
这个辅助任务由参数为$θ_{pred}$的模块$f_{pred}$执行,其中$f_{pred}$表示为$z_{o_t}$和$a_t$的线性组合。其中,$f_{pred}$表示为观察和行动表示$z_{o_t}$,$a_t$的线性组合。
他们同时训练强化学习算法和OFENet。即他们优化OFENet参数$θ_{aux} = \{θ_{pred}, θ_{φ_o} , θ_{φ_{o,a}} \}$,使下图所示的辅助任务损耗$L_{aux}$最小化。
$L_{aux} = E_{(ot,at)∼p,π}[||f_{pred}(z_{o_t},a_t ) − o_{t+1}||^2 ]$。
执行辅助任务
为了充分发挥OFENet的性能,必须选择合适的超参数。然而,最优的超参数强烈依赖于环境和强化学习算法。
因此,我们需要一种有效的方法来寻找有效的超参数。由于执行强化学习任务和比较性能的效率很低,他们使用辅助任务的性能来确定超参数。
辅助任务执行情况的确定程序如下
- 他们通过执行随机措施收集观察和行动的历史记录,并将其随机分为训练和测试集。
- 在训练集中训练后,我们用测试集中的五个随机种子来寻找平均辅助损失$L_{aux}$。
- 实际任务中采用平均辅助损耗最低的架构。
通过这种方式,无需实际让强化学习代理与环境交互学习,就能有效地确定超参数。
实验结果
在实验中,他们验证了基于低维输入的连续控制任务的性能。
所有的实验都是在MuJoCo环境下进行的。
比较研究
首先,由OFENet(原版)得到的有表示法和无表示法的情况对比结果如下所示。
如前所述,OFENet与现有的强化学习算法结合使用。这里用于比较的算法如下
在所有情况下,$z_{o_t}$,$z_{o_t,a_t}$都设置为比输入维度大240维。
另外,他们使用ML-DDPG生成的表示方式代替OFENet进行比较。
在这种情况下,他们将ML-DDPG和SAC结合起来(对应下图中的ML-SAC)。表征的维度数,既要考察原始情况(输入维度的1/3),也要考察与OFENet(OFE一样)的相同维度。
五种随机种子的学习曲线和最高平均回报率如下表所示
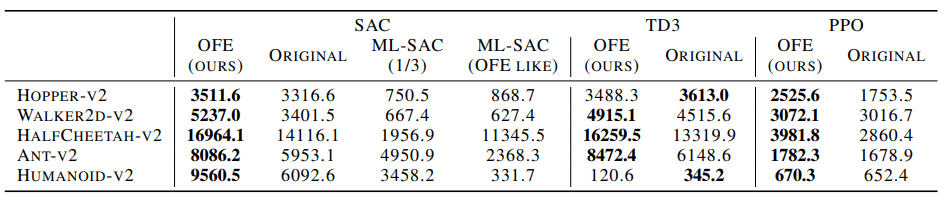
从图和表可以看出,ML-SAC的性能高于现有的表示学习方法ML-DDPG(ML-SAC)和非MFE(原始)。
消融研究
OFENet使用了MLP-DenseNet,它用多层感知器取代了DenseNet卷积层。取而代之的是这个MLP-DenseNet,MLP-ResNet和MLP会像下图一样。
从这个图中可以看出,使用MLP-DenseNet时,性能最为突出。由于网络变化对性能的影响非常大,因此要正确构建高维表示并不容易。
为了研究OFENet架构中有助于性能提升的其他元素,他们对以下例子进行消融研究。他们使用SAC作为强化学习算法,Ant-v2作为仿真环境。
full:当使用完整的OFENet表示时。
原创:原创SAC
no-bn: 无批量归一化
no-aux:没有辅助任务
与OFENet的SAC参数数量相同。
冻-ofe:先训练和固定ofenet,再训练强化学习算法。
如图所示,辅助任务、批归一化以及OFENet和强化学习算法的同步训练有助于OFENet的性能提升。
他们还研究了增加OFENet表示的维度数如何影响强化学习的性能。下图为改变$z_o$,$z_{o,a}$维数的情况。
因此,他们发现,随着维度数的增加,性能在一定阈值内有所提高。
摘要
在一般的表征学习中,从高维输入中获得低维的潜伏表征。然而,正如我们在这里所表明的那样,强化学习代理可能会通过将低维输入转换为高维表示来表现得更好。
这是一项非常重要的、很有前景的研究,对表达学习的陈旧观念投石问路。
类似文件的建议
Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates
written by Shixiang Gu, Ethan Holly, Timothy Lillicrap, Sergey Levine
(Submitted on 3 Oct 2016 (v1), last revised 23 Nov 2016 (this version, v2))
Comments: Accepted at arXiv
Subjects: Robotics (cs.RO); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
Paper Official Code COMM Code
Agent Modeling as Auxiliary Task for Deep Reinforcement Learning
written by Pablo Hernandez-Leal, Bilal Kartal, Matthew E. Taylor
(Submitted on 22 Jul 2019)
Comments: Accepted at AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE'19)
Subjects: Multiagent Systems (cs.MA); Machine Learning (cs.LG)
Paper Official Code COMM Code



与本文相关的类别

