
LLM 代理 ExpeL 现已面世,它可以从经验中自主学习!
三个要点
✔️ 提出 ExpeL,这是一种新型 LLM 代理,可从训练任务中自主学习
✔️ 通过经验收集和见解提取两个模块,代理可从经验中自主学习
✔️ 任务经验通过积累任务经验和自主学习,在对比实验中优于现有方法
ExpeL: LLM Agents Are Experiential Learners
written by Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, Gao Huang
(Submitted on 20 Aug 2023)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
在机器学习的历史上,研究人员长期以来一直在探索自主代理的潜力,最近,将大规模语言模型(LLM)纳入这些代理的做法在各学科中得到了广泛应用。
虽然 LLM 的主要优势之一是知识丰富,可用于各种任务,但由于需要大量人工标记的数据集,其高昂的计算成本一直被认为是一个问题。
此外,对 LLM 进行微调最近成为一种流行的技术,但人们发现,针对特定任务对 LLM 进行微调不仅耗费资源,而且会降低模型的通用性。
为了解决这些问题,本文介绍了提出 ExpeL 的论文,ExpeL 是一种新型 LLM 代理,它能自主地从训练任务中收集和提取经验(EXPERIENCE),使用自然语言提取知识,并做出明智的决策。
ExpeL: 体验式学习代理
我们人类的学习主要通过两种过程进行
- 将成功完成任务的过程存储在记忆中,将其作为具体实例调用(检索),并在执行新任务时加以参考。
- 从执行任务的经验中提取高层次的见解,并将其推广到新的任务中去
ExpeL 通过一个名为 "经验收集"的模块和一个名为 "见解提取"的模块来实现第一个流程,整个流程如下图所示。
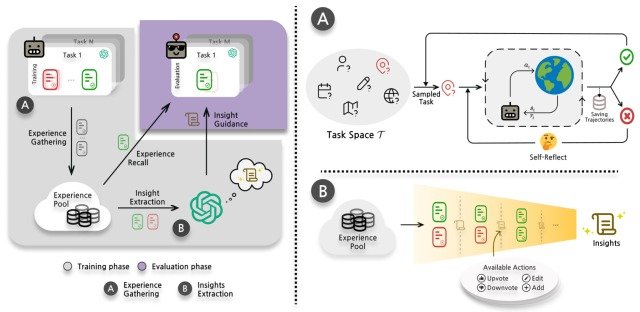
让我们逐一看看。
收集经验
当我们人类执行一项没有经验的任务时,我们会经历一个 "回忆和参照我们以前解决过的类似任务的记忆 "的过程。
受此启发,论文提出了 "经验回忆 "方法,即 "根据任务的相似性,从训练过程中收集的经验库中检索成功的过程"。
在这种方法中,代理在学习阶段与环境互动,通过与现有研究 Reflextion 的经验收集过程收集经验(体验),并将其存储在经验池(Faiss vectorstore)中。
在实际评估任务中,使用 kNN retriever 和 all-mpnet-base-vs embedder 来查找并执行上述 k 个成功进程,这些进程在评估任务和内积任务(目前收集到的任务)之间具有最大的相似性。
在这里,每当代理完成一项任务或达到最大步数时,ExpeL 代理就会重复将收集到的经验存储到经验池中的过程,然后继续执行下一项任务。
见解提取
为了利用 "经验收集 "中收集到的各种结果,代理通过两种不同的方式从经验中提取见解,并将其推广到新的任务中去
- 让代理比较同一任务中失败和成功的流程
- 让特工从不同任务的成功过程中找出模式。
为了进行上述分析,实施人员会创建一个空的洞察集,向 LLM 提供经验库中失败/成功配对或成功流程的列表,然后 LLM 根据列表对洞察集执行以下四种操作之一
- ADD: 添加新见解
- UPVOTE: 对现有见解投赞成票
- 倒票: 对现有见解投反对票
- 编辑: 编辑现有见解的内容
用于执行上述流程的模板如下图所示。

这种结构可以让用户顺利地为代理添加见解,由于所需的数据量较小,因此可以减少计算资源,而且易于实施。
此外,Reflexion 等自我改进方法有利于任务内的改进,而 ExpeL 则可以跨任务学习,使其独立于特定领域,从而获得了现有研究中所没有的多功能性。
实验
为了证明 ExpeL 的有效性,本文基于以下基准任务与现有模型进行了对比实验。
- HotpotQA:使用维基百科 Docstore API(一种搜索工具)让代理进行推理和问题解答的任务。
- ALFWorld:一项允许代理在模拟家庭的虚拟环境中执行交互式决策任务的任务。
- 网络购物: 这是一项允许代理在模拟在线购物网站的虚拟环境中执行交互式决策任务的任务。
实验中使用了七种不同的模型:模仿学习、ExpeL(仅洞察)、ExpeL(仅检索)、ExpeL(我们的)、Act、ReAct和Reflextion。
在这里,模仿学习是强化学习的一种,ExpeL(仅洞察力)是一种在 ExpeL 中不执行类似任务搜索的模型,而 ExpeL(仅检索)同样是一种不执行洞察力提取的模型。
此外,每个基准测试任务都不是单独进行的,而是按照 HotpotQA、AFLWorld 和 WebShop 的顺序依次进行的。
实验结果如下图所示。
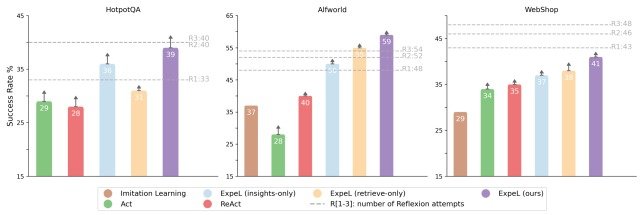
从图中可以看出,ExpeL 在所有任务中的表现始终优于现有模型,证明了该方法的有效性。
此外,比较 ExpeL(仅洞察力)和 ExpeL(仅检索)的性能可以证实,任务相似性搜索和洞察力提取在 ExpeL 中都是必不可少的,而且具有协同作用。
另一个重要发现是与 Reflextion 模型的比较,ExPeL 在 HotpotQA 中的表现与 Reflextion 相当,而在 ALFWorld 中则优于 Reflextion。
这表明,Reflexion 是通过重复执行任务(R1、R2、R3)来提高每个任务的成绩,而 ExpeL 则是通过积累每个任务的经验来跨任务学习。
另一方面,在 WebShop 中,ExpeL 的表现低于 Reflextion,这表明仍有改进的余地。
摘要
它是如何做到的?在这篇文章中,我们介绍了一篇提出 ExpeL 的论文,ExpeL 是一种新型 LLM 代理,它能自主地从训练任务中收集和提取经验(EXPERIENCE),使用自然语言提取知识并做出明智的决策。
从经验中自主学习的能力对于开发类人智能代理至关重要,而本文提出的 ExpeL 是非常有前途的第一步。
另一方面,当前研究中进行的实验仅限于基于文本的任务,作者指出,维森语言模型和字幕模型可以通过结合图像信息应用于更广泛的任务,未来的进展将很有意义。
本文中介绍的 ExpeL 架构和实验结果的详细信息,请参见本文,有关各方应予以参考。



与本文相关的类别






