ImageReward:基于学习文本到图像中人类评分的奖励模型。
三个要点
✔️ 提出一个奖励模型 ImageReward,用于预测人们在文本到图像任务中的偏好。
✔️ 提出奖励反馈学习(ReFL)方法,利用 ImageReward 的输出直接通过梯度下降优化图像生成模型。
✔️ 可生成优于现有方法的图像。
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
作者: 徐家正, 刘晓, 吴宇晨 童宇轩、 李庆凯、 丁明、 唐杰、 董玉晓
(提交日期:2023 年 4 月 12 日(v1),最后修订日期:2023 年 6 月 6 日(此版本,v3)) 版本,v3))
注释:32 页
主题:计算机视觉与模式识别(cs.CV);机器学习(cs.LG)
CODE:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
导言
文本到图像模型是根据文本指令生成图像的模型,最近的发展使生成高质量图像成为可能。
然而,在对齐方面仍然存在挑战,即模型产品与人类偏好的匹配。
具体来说,可以提及以下几点
文本与图像的对齐问题:无法准确描述提示中指定的对象数量及其关系。
身体问题:无法准确表现人和动物的体形。
人的审美问题:描绘超出正常人喜好范围的人的问题。
毒性和偏差问题:有害内容的输出等。
这些问题可能很难通过改进模型结构或改进预训练数据来解决。
在自然语言处理方面,已经开发出一种名为 RLHF 的方法,用于根据人类评估的反馈数据,通过强化学习对模型进行微调。这可以对语言模型进行微调,使其行为符合人类的价值观和偏好。该方法首先要训练一个称为奖励模型(RM)的模块,该模块用于学习人类的偏好,然后利用该模块进行强化学习。然而,这种方法需要从人类评价中收集大量数据,在许多方面都是劳动密集型的,而且成本高昂,包括构建评价方法、招募评价者和验证评价�
为了解决这些问题,本文提出了一种通用奖励模型(RM)--ImageReward,它可以学习人类在文本到图像中的偏好。此外,利用该模型,我们还提出了一种名为 ReFL 的方法来优化生成模型。生成示例(下图)表明,生成高质量的图像是可能的,这些图像不仅遵循文本说明,而且还符合人类的偏好。

下面将详细介绍学习方法和实验�
数据收集
DiffusionDB 是一个由 Diffusion 模型生成的数据集,其中包含 10,000 条提示语和图片,我们采用了 DiffusionDB 中的 170,000 多对提示语和图片作为评估数据。
评估流程从对提示进行分类并检查是否存在问题的阶段开始,然后是根据一致性(是否遵循提示)、忠实性(准确性)和无害性(无伤害)评估分数的阶段,最后是根据偏好对图像进行排序的阶段。根据喜好对图像进行排序的阶段。
评估系统的接口如下图所示。数据收集结果是对 8878 个提示进行了 136892 个图像提示配对评分。

奖励模式(RM)学习
按照以往研究的 RM 学习方式,使用以下损失函数来学习 RM $f_{\theta}$。其中,提示用 $T$ 表示,生成的图像用 $x$ 表示。
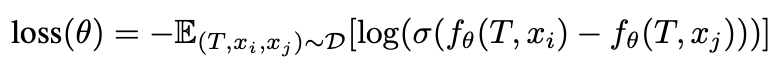
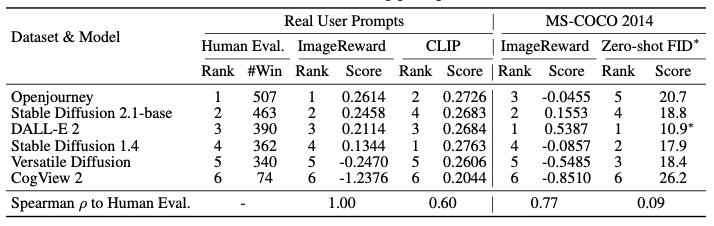
验证结果表明,以这种方式学习到的 ImageReward 也可用作文本到图像模型的评估指标。下表显示了在对各种模型生成的图像进行排名时,人类评分与 ImageReward 评分和 CLIP 评分的对应关系。这表明,ImageReward 评分与人类评分和排名相吻合,可以认为它比 CLIP 评分更好地反映了人类评分。
ReFL:使用 ImageReward 微调文本到图像模型
考虑使用 ImageReward 对文本到图像模型进行微调。
在自然语言处理方面,强化学习被用来将 RM 信息反馈到语言模型中(RLHF),但扩散模型不能使用 RLHF 方法,因为它们是由多步去噪过程生成的模型。
本文提出的算法将 ImageReward 输出的分数设为目标函数,直接进行误差反向传播。本文使用了以下两个目标函数,前者是 ImageReward 分数的目标函数,后者是一个正则化项,以避免过度学习和学习不稳定。其中,$\theta$ 是扩散模型的参数,$g_{\theta}(y_i)$ 是为提示 $y_i$ 生成的图像。
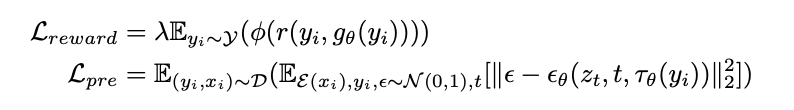
试验
ImageReward 预测的准确性
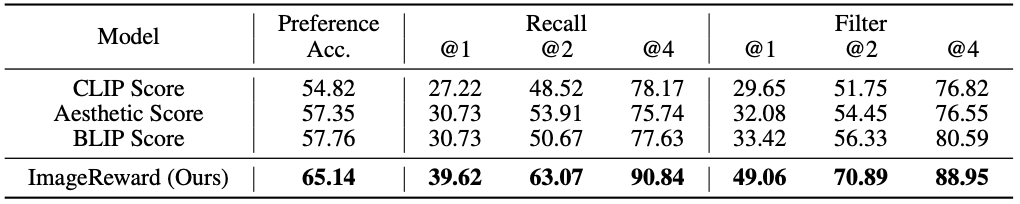
下表显示了预测人类偏好的准确性,ImageReward 的准确性高于其他方法(例如使用计算文本和图像相似性的模型,如 CLIP 和 BLIP)。
利用 ReFL 提高图像生成性能
下表比较了使用 ImageReward 微调稳定扩散 v1.4 模型的方法。它显示了与基线稳定扩散 v1.4 模型相比,该模型获得较高评分的次数及其胜率。
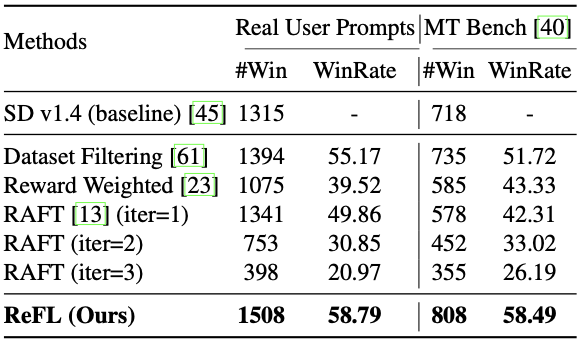
下文概述了表格中出现的以往各项研究。
数据集过滤是一种使用 RM 过滤数据集的技术。针对给定的提示选择得分最高和最低的图像,用于微调生成模型。
奖励加权是一种微调方法,在生成模型的微调过程中使用 RM 对损失函数进行加权,以生成有利的图像。
RAFT 是一种通过反复评估生成的图像和微调生成模型来提高生成模型性能的方法。
与上述研究相比,可以看出所提出的 ReFL 具有很高的准确性。
与以往的研究不同,所提出的 ReFL 算法直接使用来自 RM 的奖励值,并通过梯度下降提供反馈,这可能会导致对图像生成的更好评估。
如下图所示,进行了定性比较。

摘要
在本文介绍的论文中,我们提出了一种在文本到图像领域优化图像生成模型的方法 ReFL,即通过训练一个学习人类评价的奖励模型 ImageReward,并直接使用梯度下降法使用该模型,并介绍了其有效性。与本文一样,在文本到图像数据集、评价函数和生成模型的应用方面,新方法也在不断被提出,我们将继续关注这一领域的发展。



与本文相关的类别


