RLHF:如何利用人类评分训练强化学习代理。
三个要点
✔️ 通过人类对代理行为的比较评估来量化好坏,并训练一个奖励模型来接近它
✔️ 使用奖励模型训练强化学习代理使用
✔️ 奖励模型训练的代理表现出与使用普通奖励模型训练的代理相当的性能。与使用普通奖励模型训练的代理性能相当
Deep reinforcement learning from human preferences
written by Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei
(Submitted on 12 Jun 2017 (v1), last revised 17 Feb 2023 (this version, v4))
Comments: Published on arxiv.
Subjects: Machine Learning (stat.ML); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
导言
强化学习的成功在很大程度上取决于良好奖励函数的设计,而对于许多任务来说,设计这样的奖励函数本身就很困难。
例如,如果我们想让机器人通过强化学习学会擦桌子,我们不知道什么样的奖励函数是合适的,即使我们设计了一个简单的奖励函数,也可能会诱发非预期行为。因此,我们人类的价值观与强化学习系统的目标函数之间的错位一直被认为是强化学习领域的一个难题。
如果有某项任务的理想示范数据,就可以通过逆强化学习或模仿学习来复制其行为,但在没有这些数据的情况下,这些方法就不适用了。
另一种方法是由人来评估系统的行为并提供反馈。然而,鉴于强化学习需要大量的经验反馈,将人类反馈作为直接奖励并不现实。
为了克服这些挑战,本文采用了一种利用人类评估反馈数据学习奖励函数的方法,然后利用这些数据优化强化学习系统。虽然这种方法已在较早的研究中提出,但本文将其应用于较新的深度强化学习框架,从而可以获得更复杂的行为。
技术
以 $\pi$ 作为策略,以 $\hat{r}$ 作为估计奖励函数,重复以下三个过程来训练 RL 代理。
首先,在过程 1 中,使用策略 $\pi$ 收集与环境交互的时间序列数据(轨迹)$\tau$。使用传统的强化学习算法优化策略,使 $\hat{r}$ 的累积和最大化。
然后,流程 2 从流程 1 获得的时间序列数据集 $\tau$ 中选择两个缩短的片段 $\sigma$,并要求人工比较和评估哪个更好。
在流程 3 中,利用人工评估反馈对估计奖励函数 $\hat{r}$ 进行优化。
政策优化
估计的奖励函数 $\hat{r}$ 可用于通常的强化学习算法,但需要注意的一点是,$\hat{r}$ 并不是一成不变的。因此,应采用对奖励函数变化具有鲁棒性的策略梯度方法,这也是本研究采用 A2C [Mnih 等人,2016 年] 和 TRPO [Schulman 等人,2015 年] 的原因。
$\hat{r}$ 生成的奖励值被归一化为具有固定的标准偏差和平均值 0。
首选用途
评价者会看到两个以 1~2 秒短片形式出现的轨迹片段 $\sigma$,并通过比较他们更喜欢哪个来评分。人类的评价由分布 $\mu$ 表示。
学习奖励函数
损失函数的计算公式如下
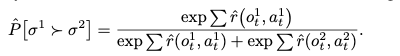
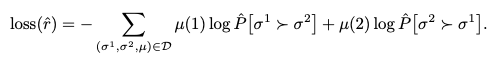
实验结果
评估者会看到一段 1 或 2 秒钟的轨迹短片,他们必须评判哪一段更好,这种情况会重复几百到几千次。因此,每人需要花费 30 分钟到 5 个小时的时间进行反馈。
机器人模拟
第一项任务是在一个名为 MuJoCo 的物理模拟器上实现的八项基于机器人的任务(步行者、跳跃者、游泳者、猎豹、蚂蚁、高攀者、双摆、钟摆)。
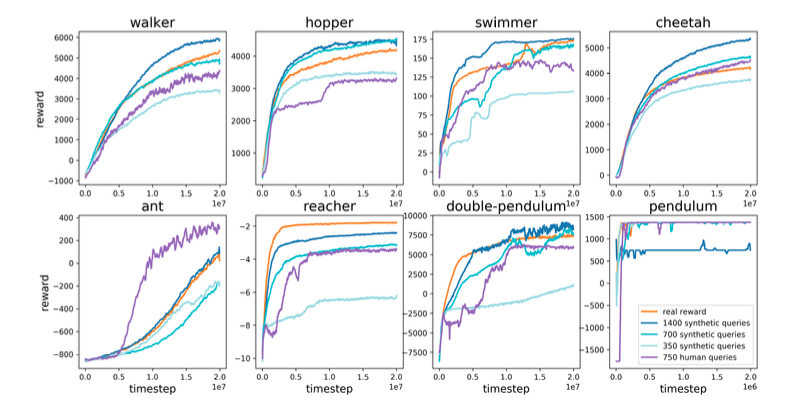
结果如上图所示。
当奖励模型根据人类评估数据进行训练,并将模型输出作为奖励来训练代理(紫色)和
用环境中的真实奖励值训练奖励模型,并将模型输出作为奖励来训练代理(蓝色系统),以及
将该代理在各种任务中的表现与使用真实奖励值(橙色)训练的代理的表现进行比较。
可以看出,使用奖励模型(紫色和蓝色)的建议方法与使用真实奖励值(橙色)训练代理时的性能水平相同,就像在普通强化学习中一样。
雅达利
第二项任务是使用雅达利的七款游戏(beamrider、breakout、pong、qbert、seaquest、spaceinv 和 enduro)。
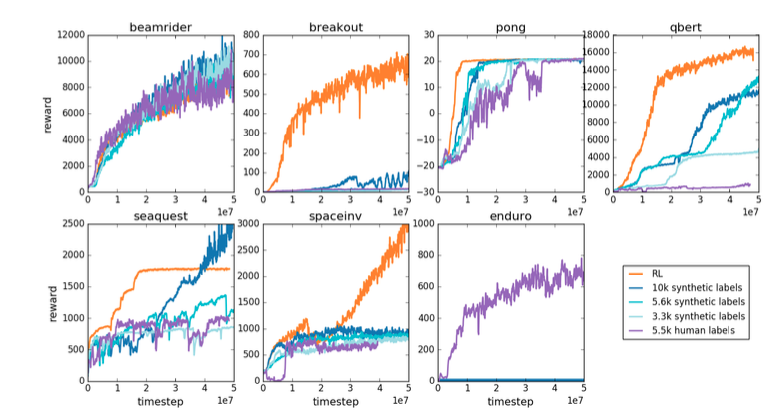
结果如上图所示。
根据游戏类型的不同,我们可以看到,使用奖励模型(基于紫色或蓝色)的建议方法战胜或输给了普通强化学习方法(橙色)。
在大多数游戏中,使用人类反馈(紫色)训练奖励模型的效果与使用真实奖励值(蓝色)训练奖励模型的效果相同或略差,但考虑到用于训练奖励模型的数据数量前者(紫色)似乎更有效。
补充实验结果
所提出的让奖励模型学习人类评价的方法,在难以设定良好奖励函数的任务中尤为有效。
在上述机器人模拟实验中,料斗机器人学会了翻筋斗,半雪橇机器人学会了单腿前进,它们都能在短时间内高效地学会奖励函数通常比较复杂的行为。
消融研究还揭示了以下几点
首先,我们发现,如果离线训练奖励模型,即使用最近代理的累积行为数据,而不是使用最近代理的行为,就会获得不良行为。这表明,需要在线提供对人类评分的反馈。
我们还要求人类评分员通过比较两个例子而不是绝对分数来反馈他们的评分,因为这样可以得到一致的评分,在连续控制任务中尤其如此。这样做的原因是,当奖励尺度变化很大时,用预测绝对分数的回归方法很难预测奖励。
结论
我们已经证明,利用人类评估反馈训练奖励预测奖励模型的方法在最近的深度强化学习系统中也很有效。这是将深度强化学习应用于复杂现实任务的重要第一步。
摘要
在这篇文章中,我们介绍了一篇关于 "人类反馈强化学习"(Reinforcement learning from Human Feedback,RLHF)的最新论文,这是一种著名的方法,用于微调大规模语言模型,使其表现出符合人类价值观的行为。自 2017 年这篇论文发表以来,已有许多针对 RLHF 的方法被提出,它也是未来有望发展的最重要领域之一。我们希望这篇文章能帮助您关注 RLHF 的发展。



与本文相关的类别