利用人类评分反馈微调文本到图像模型
三个要点
✔️ 利用人类评估反馈微调文本到图像模型的拟议方法
✔️ 通过让人们评估为提示生成的示例来训练奖励函数。获得的奖励函数用于更新图像生成模型。
✔️ 拟议的方法可以生成更准确反映提示中的对象数量、颜色、背景和其他说明的图像。
Aligning Text-to-Image Models using Human Feedback
written by Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Shixiang Shane Gu
(Submitted on 23 Feb 2023)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
导言
近年来,根据文字说明(提示)生成图像的方法有了长足的发展,但如果生成的图像与说明不匹配,就会出现问题。
在语言建模方面,RLHF 正在成为一种基于人类反馈的学习方法,并使模型的行为与人类的价值观相一致。
这种方法首先利用人类对模型输出的评估来学习奖励函数,然后通过强化学习来优化语言模型。
本文试图以这种方式利用奖励函数对文本到图像模型进行微调。(不过,本文介绍的方法并非严格意义上的 RLHF,因为它没有使用强化学习)。
下图显示了拟议方法的概况
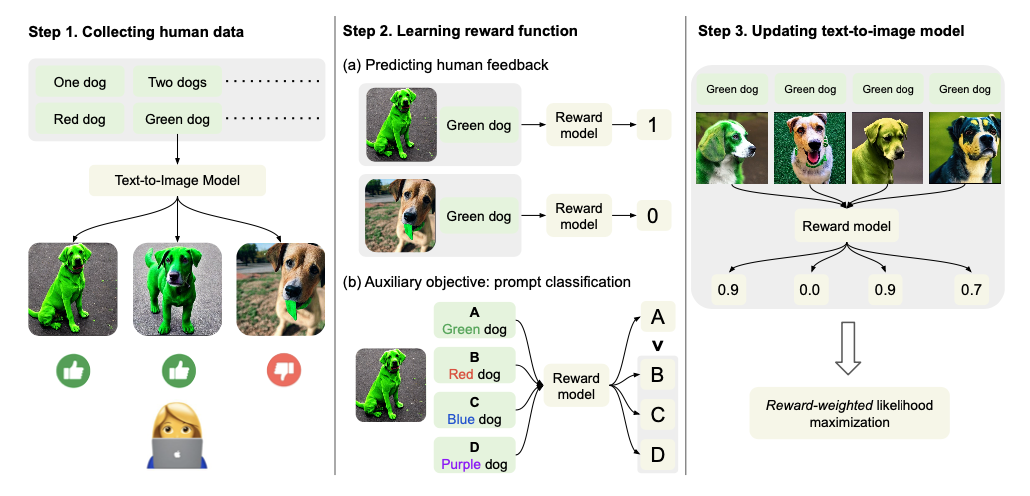
(1) 首先,为文本提示生成各种图像,以收集对人类评价的反馈。
(2) 接下来,利用获得的数据来训练奖励函数,以预测人类的评分。除了通常的评分预测任务外,奖励函数还被用来训练另一项任务,即识别用于生成图像的提示。
(3) 然后,在使用奖励函数的同时,以半监督学习的方式更新模型,这与使用传统强化学习(RL)的方法不同�
本研究采用稳定扩散模型 [Rombach 等人,2022 年] 作为图像生成模型。
技术
前面介绍的步骤 (1)-(3) 将作详细说明。
(1) 收集人类评估数据
使用稳定扩散模型可为单个提示生成多达 60 幅图像。提示指定了数量、颜色和背景。示例:城市中的两只绿狗
由于提示请求比较简单,因此人类的评分采用好坏二元标签。
(2) 学习奖励函数
训练函数 $r_{\phi}$,将图像 $x$ 和提示 $z$ 作为输入,并输出人类评估的预测值 $y$。预测值为 1 表示 "好",为 0 表示 "坏"。奖励函数学习的目标函数如下。

在数据扩展方面增加了另一个目标函数。
我们准备了一个假提示,其中提示语 $z$ 的一部分被另一部分取代,任务是利用以下目标函数正确选择原始提示语。
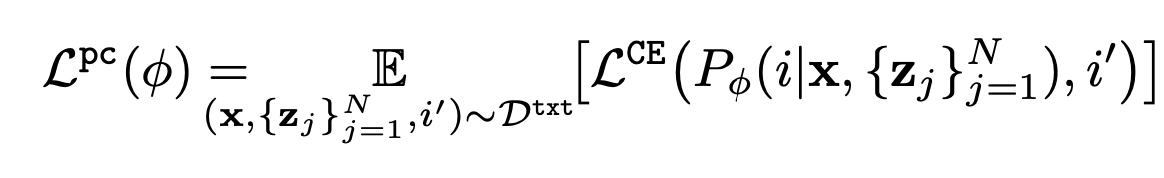
然而,$P_{\phi}$ 表示提示的选择概率。
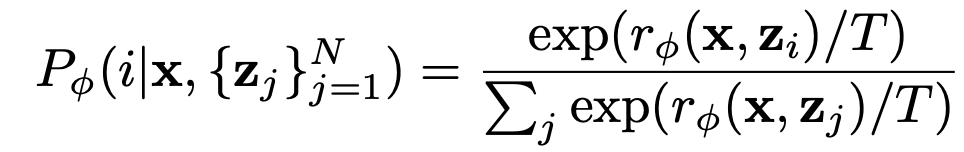
最终目标函数是上述两个目标函数的组合。
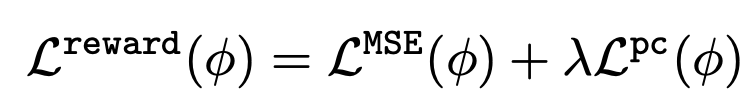
(3) 文本到图像模型的微调
利用学习到的奖励函数,文本到图像模型通过以下基于负对数似然最小化的公式进行微调。
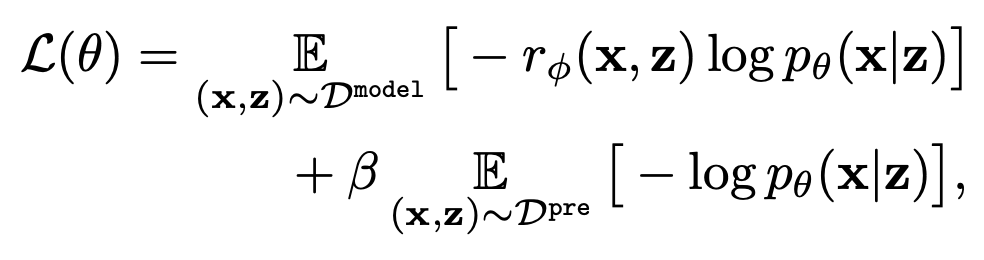
第一项的作用是使模型生成的结果更接近提示。第二项则确保生成结果的多样性�
试验
型号设置
基于稳定的扩散模型,在微调过程中,CLIP 部分被冻结,只对扩散模块部分进行训练。
作为奖励函数模型,ViT-L/14 CLIP 模型[Radford 等人,2021 年]通过 MLP 计算图像和文本嵌入以及结构返回分数。
以人为本的评估
向评分者展示两幅图像,一幅是由建议的模型(微调模型)生成的,另一幅是由原始稳定扩散模型生成的。每一对模型都收集了九位评分者的评分。结果如下图左侧所示。
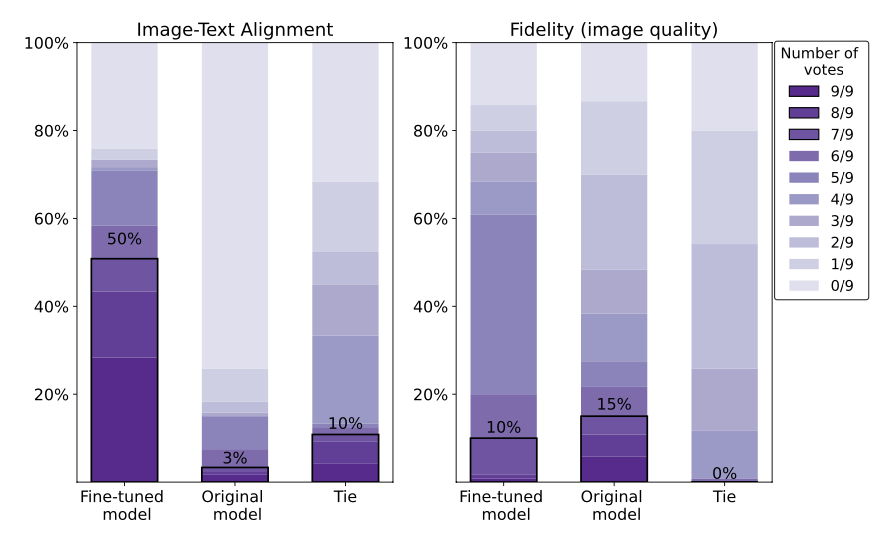
结果显示,与原始模型相比,建议模型(微调模型)的图像与文本的拟合度更高。另一方面,图像质量(右侧)略有下降。这可能是由于用于微调的数据量较少,或者在评估中只使用了文本拟合�
定性评价
让我们定性比较一下拟议模型和稳定扩散模型生成图像的效果。结果如下。

这表明,所提出的模型能够准确地反映数字、颜色和背景的指示。
但另一方面,也发现了一些问题,如图像多样性降低。这个问题可以通过增加数据量等方法来解决�
讨论
在本文中,我们提出了一种改进图像到文本模型行为的方法,即利用微调和人工评估反馈来生成图像,从而准确地遵循提示中的指示,如片数、颜色和背景。实验表明,在遵循提示说明和确保图像质量(如多样性)之间存在着难以调和的权衡。
论文最后提到了未来发展的可能性。例如,在目前的实验中,准确度是由人类在有限的范围内进行评估的,如棋子的数量和颜色,但人类评估的视角更加多样化,可以提高生成图像的性能�
本文可视为利用人类评估反馈改进文本到图像模型的第一步。我们对未来研究的进一步发展寄予厚望。



与本文相关的类别