
I-BERT:只能对整数类型进行推理的 BERT。
三个要点
✔️ 提出了所有 BERT 计算都采用整数类型的 I-BERT
✔️ 引入了用二次多项式近似 Softmax 和 GELU 的新方法
✔️ 比不量化的速度快 2.4~4.0 倍
I-BERT: Integer-only BERT Quantization
written by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer
Submitted on 5 Jan 2021 (v1), last revised 8 Jun 2021 (this version, v3)
Comments: ICML 2021 (Oral)
Subjects: Computation and Language (cs.CL)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
基于变压器的模型,如 BERT 和 RoBERTa,在许多自然语言处理任务中都表现出很高的准确性。另一方面,内存占用(引用的内存量)、推理时间和功耗不仅在边缘,而且在数据中心都是挑战。
解决这一难题的方法之一是模型量化,即用低位精度(如 8 位整数 (INT8) 而不是 32 位浮点数 (FP32))表示模型权重和激活度,从而降低模型权重。
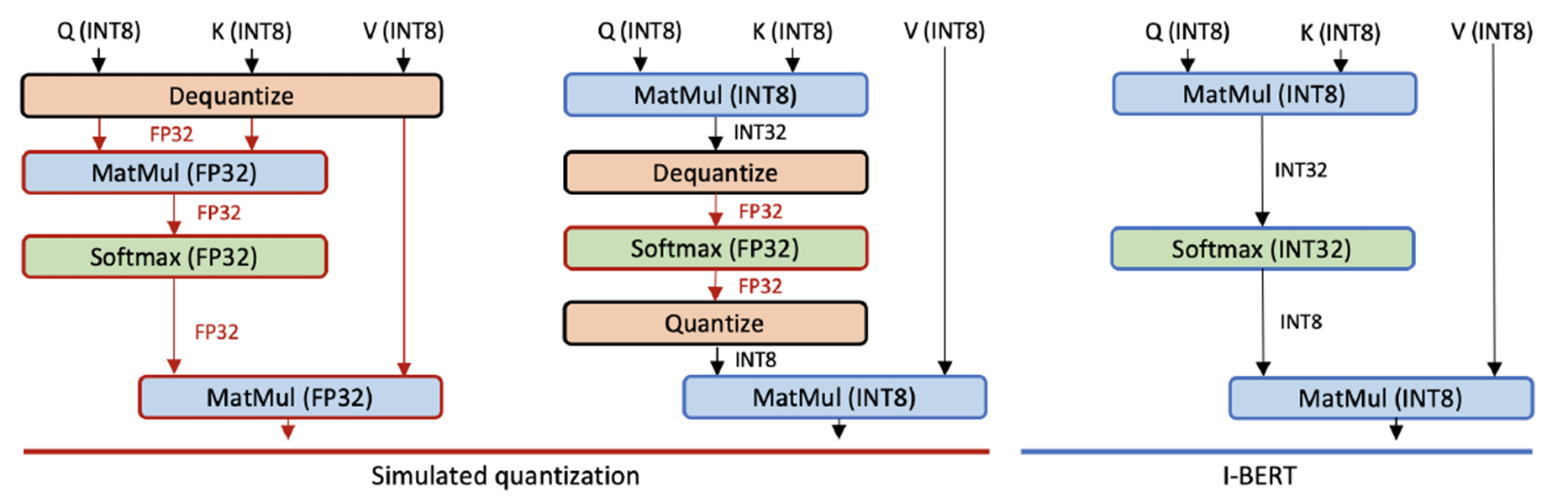
迄今为止,对基于变压器的模型所做的模型量化仅限于模型的输入和线性运算部分,不能说已经实现了完全的模型量化(上图中的模拟量化)。
因此,本文提出了 I-BERT,其中BERT 中的所有操作都以整数类型实现。
拟议方法:I-BERT
基本量化方法
浮点数到整数的量化采用对称均匀量化法,具体如下。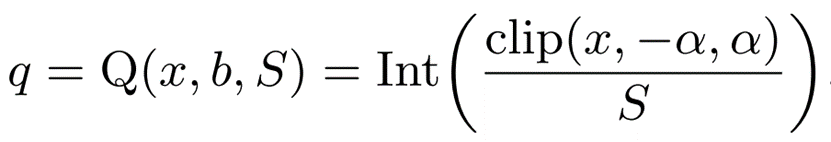
x是量化前的浮点数,q 是量化后的整数值。
非均匀量化会动态改变 q 所对应的浮点数范围,有可能捕捉权重和激活参数的分布。但它会造成开销,因此采用了均匀量化。
b 是位精度,它决定了 q 可以表示的数值范围,如下所示。
![]()
clip 是截断函数,α是控制其范围的参数。之所以称这种方法为对称量化,是因为剪辑对 [-α,α] 值的截断是对称的。
S是缩放因子;S 在推理时固定如下,以避免运行时开销(静态量化)。
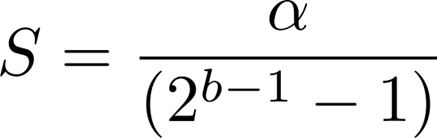
只进行整数运算的非线性函数
在以往的研究中,由于纯整数运算利用了线性,因此可以轻松进行线性和片断线性运算。例如,MatMul(矩阵乘积)可以通过将量化值 q 乘以比例因子 S 来计算,如下式所示。
![]()
另一方面,由于 GELU 等非线性函数不满足线性条件,因此无法轻松计算,如下式所示。
![]()
为应对这一挑战,本文提出将非线性函数近似为多项式函数,只需使用整数运算即可计算。
非线性函数的多项式近似
内插多项式用于将非线性函数近似为多项式函数。
找出一条阶数为 n 的多项式,以拟合 n+1 点的函数数据集,如下式所示。
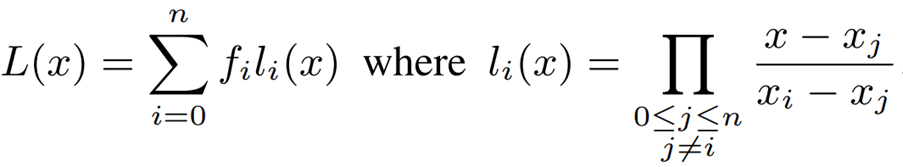
这里,阶数 n 的选择是一个关键点。阶数越大,近似误差越小,但也会出现 "开销和计算量增加 "以及 "计算位数较低时可能出现溢出 "等问题。
鉴于上述情况,我们面临的挑战是如何找到低度多项式来逼近变换器中使用的非线性函数(GELU 和 Softmax)。下面,我们将详细介绍本文提出的 GELU 和 Softmax 近似方法。
仅整数 GELU
GELU是变压器模型中使用的激活函数,可表示如下
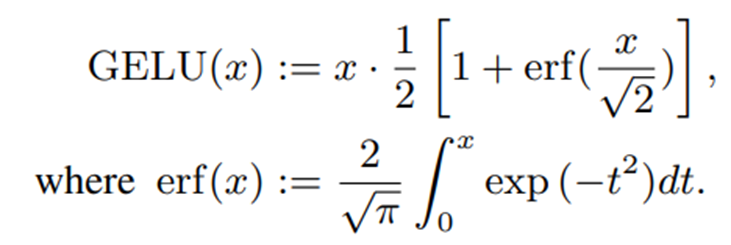
由于 Erf(误差函数)的积分项计算效率较低,因此提出了各种近似方法。
例如,下面的近似值是用西格玛函数求得的。
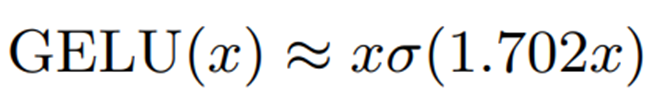
sigmoid 函数 (σ) 本身是一个非线性函数,因此不适合作为整数运算的近似方法。
另一种方法是用硬 Sigmoid(h-Sigmoid)近似 sigmoid 函数。本文将这种近似方法称为h-GELU。
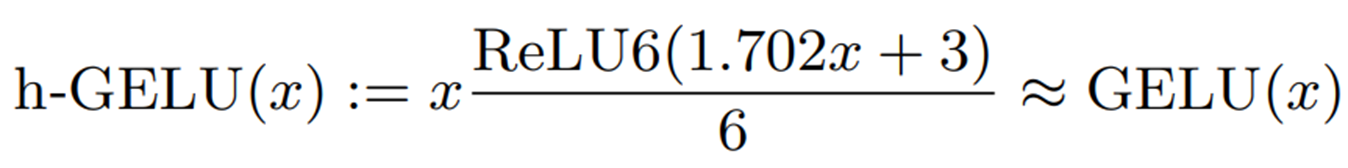
h-GELU 只能对整数类型进行运算,但存在近似精度降低的问题。
因此,本文提出用二维多项式来近似误差函数。
为了近似,请考虑以下优化问题
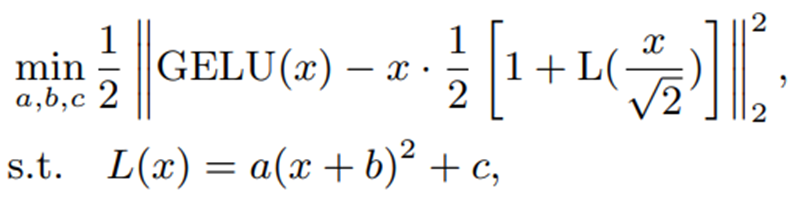
L(x) 表示逼近误差函数的二次多项式。如果优化时定义域为整个实数,近似的精度就会降低。
为了解决这个问题,我们利用了当 x 较大时误差函数接近 1 的事实,并考虑在有限的范围内进行逼近。此外,由于误差函数是奇函数,因此只考虑正区域。
在这些条件下,上述使用插值多项式的近似方法如下。
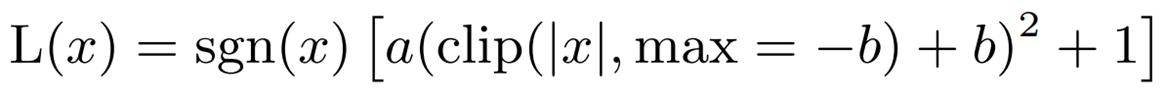
a = -0.2888 和 b =-1.769,其中 sgn 是符号函数。使用该多项式的 GELU 近似值(i-GELU)可表示如下。
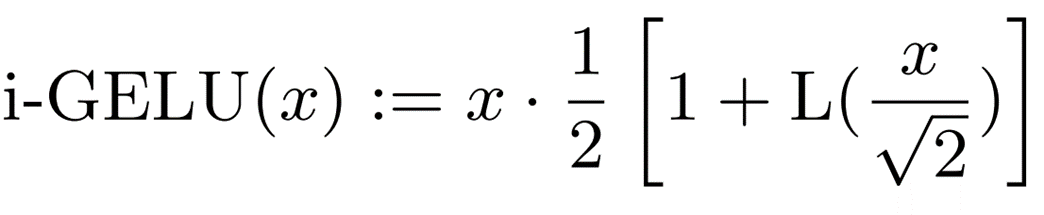
i-GELU 的操作算法如下。

下图比较了 i-GELU 和现有的基于 sigmoid 函数的方法 h-GELU。
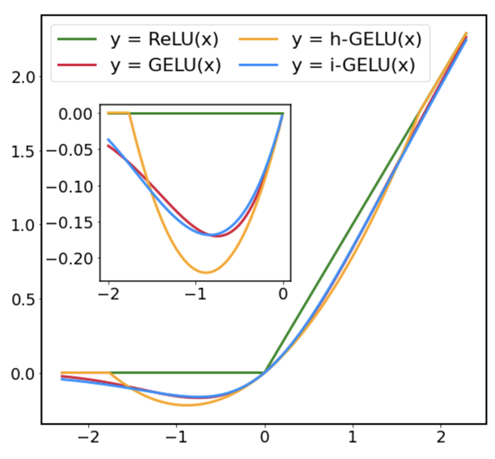
下表列出了近似精度(L2 和 L∞ 距离)的定量比较结果。从图和表中可以看出,i-GELU 的近似精度最高。

仅整数 Softmax
Softmax用以下等式表示,可以将输入向量转换为概率分布。
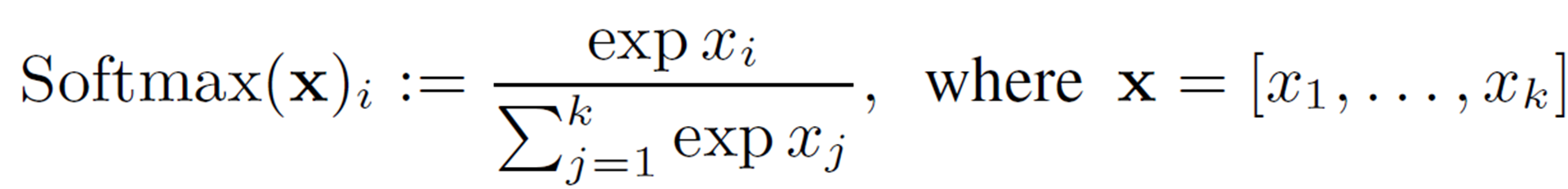
与 GELU 一样,我们考虑的是范围受限的二阶多项式近似。首先,为了数值稳定性(防止溢出),输入值要减去最大值 (![]() )。
)。
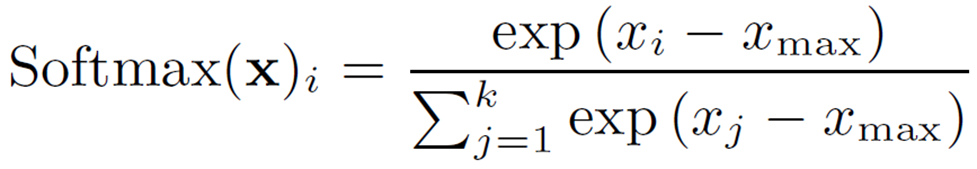
![]() 细分如下。
细分如下。
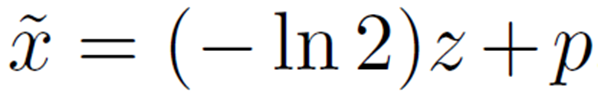
z 和 p 分别表示除以-ln2 后的商和余数。因此,Softmax 的指数部分可以表示如下。
![]()
因此,我们考虑在![]() 逼近 exp(p)。与 GELU 一样,应用上面解释的内插多项式,我们可以将其逼近如下。
逼近 exp(p)。与 GELU 一样,应用上面解释的内插多项式,我们可以将其逼近如下。
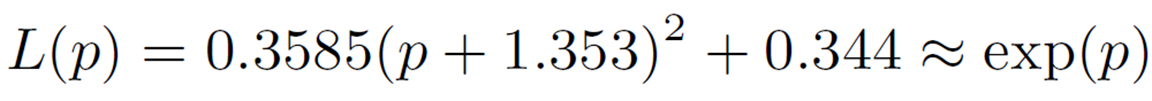
因此,![]() 的计算方法如下。
的计算方法如下。
![]()
![]() 和
和![]() 。这个指数函数的近似值可以用下面的图形表示。
。这个指数函数的近似值可以用下面的图形表示。
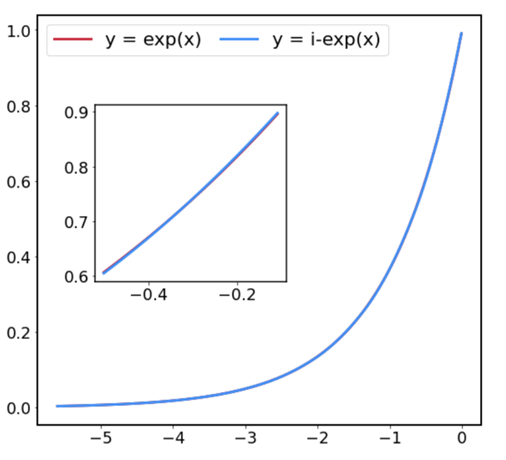
最大误差为![]() ,这表明,考虑到 8 位量化误差为
,这表明,考虑到 8 位量化误差为![]() ,误差足够小。最后,总结一下,以整数格式计算 Softmax 的算法如下所示。
,误差足够小。最后,总结一下,以整数格式计算 Softmax 的算法如下所示。

只限整数
LayerNorm将各通道维度的输入特征标准化,并用以下公式表示。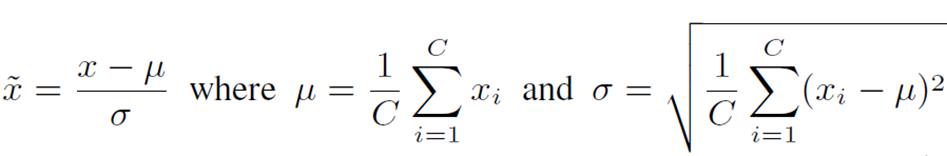
µ 和σ分别代表平均值和标准偏差。
计算标准偏差所需的平方根运算很难直接以整数形式计算。因此,我们使用基于牛顿法的迭代算法来计算标准偏差。
算法如下

试验
精确度等级
我们首先来看看 I-BERT 的推理准确性,它已在名为 GLUE 的基准任务中的 RoBERTa-Base 和 RoBERTa-Large 模型上得到验证。
结果见下表。

在除 MNLI-m、QQP 和 STS-B 任务之外的所有任务中,RoBERTa-Base 的精确度均高于使用 FP32(浮点数)时的精确度。
即使在精度降低的任务中,差异也非常小,最大仅为 0.3%。对于 RoBERT-Large,I-BERT 在所有任务中的表现都优于 I-BERT,平均准确率提高了 0.5%。
上述结果表明,I-BERT 的精度与 FP32 相近或略高于 FP32。
推理速度评估
I-BERT 的推理速度也得到了验证。
下表列出了各句子长度 (SL) 和批量大小 (BS) 与 FP32 相比的速度提升情况。使用的模型是 BERT-Base 和 BERT-Large。
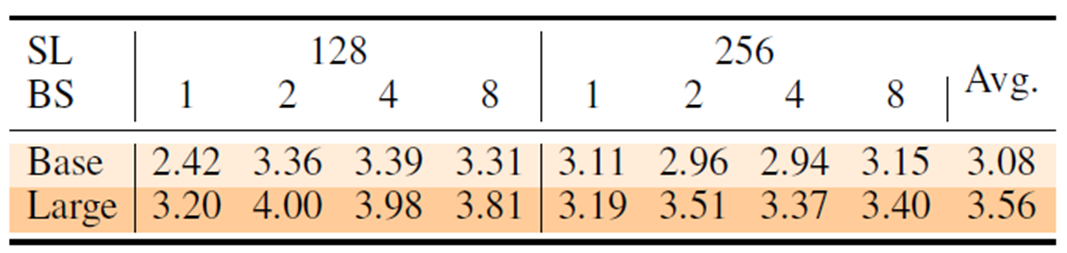
采用 INT8 型推理的I-BERT 与 FP32 型推理相比,BERT-Base 平均提速 3.08 倍,BERT-Large 平均提速 3.56 倍。
消融研究
I-BERT 使用的 GELU 近似方法 i-GELU 的验证工作也在进行之中。
在 RoBERa-Large 模型中,下表比较了无近似 GELU、h-GELU 和 i-GELU 在相同 GLUE 任务中的准确度评估[2]。
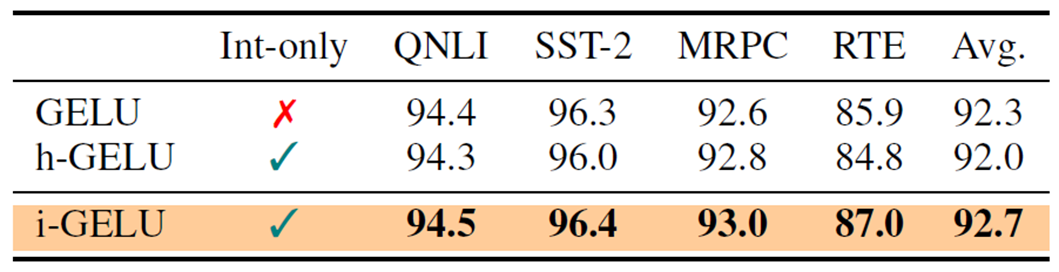
可以看出,在 MRPC 以外的任务中,h-GELU 的精度低于 GELU。这表明 h-GELU 的近似精度不够。
在所有任务中,i-GELU 都优于 h-GELU,其精确度与 GELU 相似或略高于 GELU。这些结果表明,i-GELU 近似值是适当的。
摘要
在本文中,我们介绍了 I-BERT,这是一种所有计算都以整数类型实现的 BERT。它的主要优点是速度提高了约三倍,而精度却没有明显下降。
在需要用手头的自然语言模型处理需要保密的信息的情况下,人们认为可能需要像 I-BERT 这样计算量小的模型。
补贴
[1]Prime Numbers: A Computational Perspective | SpringerLink
[2] 验证在 Tesla T4 GPU 上进行。



与本文相关的类别






