比较连续学习中的预学习语言模型
三个要点
✔️ 将持续学习方法用于预学习语言模型
✔️ 各模型和连续学习方法的稳健性比较
✔️ 对每层的预学习语言模型进行分析。
Pretrained Language Model in Continual Learning: A Comparative Study
written by Tongtong Wu, Massimo Caccia, Zhuang Li, Yuan-Fang Li, Guilin Qi, Gholamreza Haffari
(Submitted on 29 Sep 2021)
Comments: ICLR2022
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
持续学习(Continual Learning),即在学习模型的同时避免灾难性的遗忘,一段时间以来一直是各种研究的主题,并提出了许多方法。在自然语言处理领域,许多预学习模型,如BERT和ALBERT,已经被提出并被积极研究。
本文对持续学习和预学习模型的组合性能进行了全面的比较研究,并介绍了一篇利用预学习模型揭示持续学习一系列信息的论文。
介绍
首先,介绍了前提知识,包括要比较的预训练的语言模型、连续学习设置和比较实验中要使用的连续学习方法。
预训练的语言模型(PLM)
使用预先训练的语言模型(PLM)是许多NLP任务的有效方法,如问题回答和总结。本文利用了以下五个预先训练好的语言模型
- BERT:本网站的说明性文章
- 阿尔贝特:本网站的解释性文章
- RoBERTa:本网站的解释性文章
- GPT-2:一个自回归语言模型,每次从左到右预测一个标记,通常用于自然语言生成任务。
- XLNET:本网站的解释性文章。
更多信息请见本网站的原始论文或解释性文章。
设置持续学习问题
持续学习的目的是学习一组给定的任务而不降低以前所学任务的性能。它通常在学习时间的增量(incremental, incremental)分类任务设置中被评估。更具体地说,使用了三种设置:类、域和任务增量学习。
在任何学习环境中,连续学习算法都是依次给每个任务一次,但存在以下区别

- 在Task-IL:test过程中,要处理的任务信息(task-ID,任务标签)被给出。
- 在Domain-IL:test过程中,没有给出要处理的任务(task-ID)的信息,但也不需要预测被处理的任务信息。
- 在Class-IL:test过程中,没有给出要处理的任务(task-ID)的信息,必须预测正在处理的任务的信息。
这一设置遵循了以前的研究。
持续学习方法
持续学习方法可分为三大类(排练、正规化和动态架构)。
基于排练的方法
基于排练的方法以某种形式存储过去的样本,并在训练新任务时重新使用它们。最简单的方法是将过去的样本与新数据一起重放,以阻止灾难性的遗忘。这被称为 "经验重放"(ER),通常是一种先进的基线。
为了提高ER的性能和效率,人们提出了许多基于排练的方法,如利用过去的样本而不是简单的重放进行约束性优化,以防止过去任务的损失增加。
基于正则化的方法
基于正则化的方法通过防止被认为在以前的任务中很重要的参数的重大更新来解决灾难性的遗忘。这些方法从弹性权重巩固(EWC)开始,EWC使用L2正则化损失抑制以前学习的权重的巨大变化。
基于正则化的方法往往依赖于任务边界,在没有给出长任务序列或任务ID的情况下往往会失败。
动态架构方法
动态架构方法,也被称为参数分离方法,利用不同的模型参数子集来适应不同的任务。属于这一类的著名方法包括对任务的严格关注(HAT)。
与基于正则化的方法一样,常规动态架构方法在测试时需要一个任务ID。
实验
通过标杆管理不断学习PLM
该实验将调查三个问题
- (1) 在持续学习PLM的过程中,是否存在灾难性遗忘的问题?
- (2) 哪种持续学习方法在PLM中最有效? 这其中的原因是什么?
- (3) 哪些PLM对持续学习最有力? 这其中的原因是什么?
实验装置
在实验中,PLM和线性分类器被结合起来,以比较以下方法。
- 香草:在前一个任务中学到的模型直接为下一个任务进行优化。这是最有可能发生灾难性遗忘的环境,是一个弱的下限。
- 联合:同时学习所有任务。它不受灾难性遗忘的影响,因此是一个性能的上限。
- EWC:采用了基于正则化的方法,即EWC。
- HAT:使用HAT,一种动态架构方法。(不适用于IL级设置)。
- ER:使用ER,一种基于排练的方法。
- DERPP: DERPP是一种基于排练-规则化的混合方法。
评价指标如下。
- Forward transfer:$FWT=\frac{1}{T-1}\sum^{T-1}_{i=2}A_{T,i}-\tilde{b_i}$
- Backward transfer:$BWT=\frac{1}{T-1}\sum^{T-1}_{i=1}A_{T,i}-A_{i,i}$
- 平均应计费用:$Avg.ACC=\frac{1}{T}\sum^T_{i=1}A_{T,i}$
其中$A_{t,i}$是在第t个任务上训练模型后第i个任务的测试精度,$Ttilde{b_i}$是随机初始化时第i个任务的测试精度。
实验中使用的数据集如下。
- CLINC 150。
- MAVEN。
- 网络红利
每个数据集的数据分布如下。
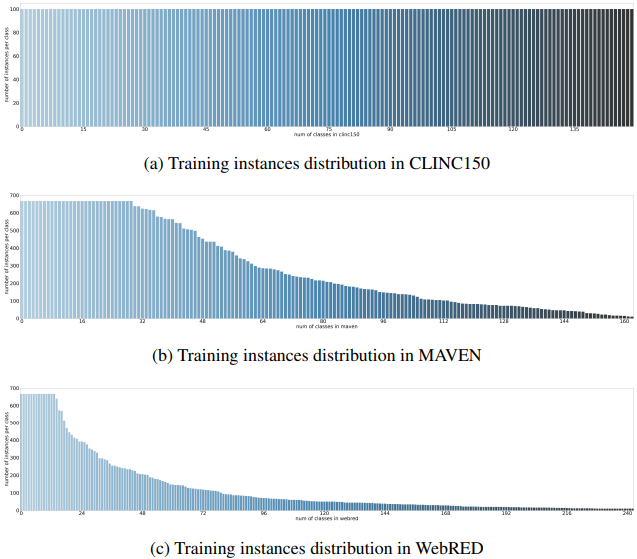
纵轴显示每个班级的数据数量,横轴显示班级的数量。
实验结果
在每个环境中都进行了实验,所获得的准确度总结在下表中。
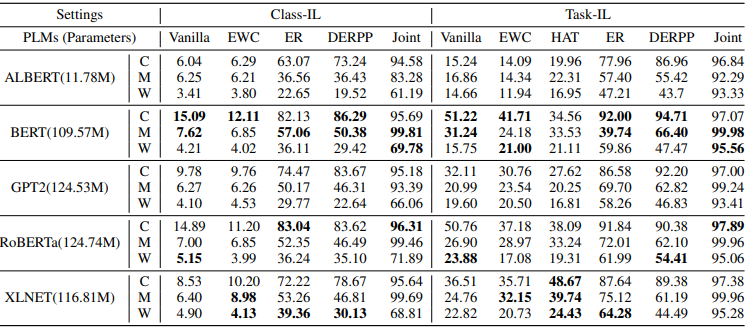
通过比较每个PLM的香草和联合精度可以看出,PLM中出现了严重的灾难性遗忘。这是所有数据集(C、M、W)的共同点,在Class-IL设置中尤其严重。每个模型的不同延续学习方法的结果和每个延续学习方法的不同模型的结果的比较如下所示。
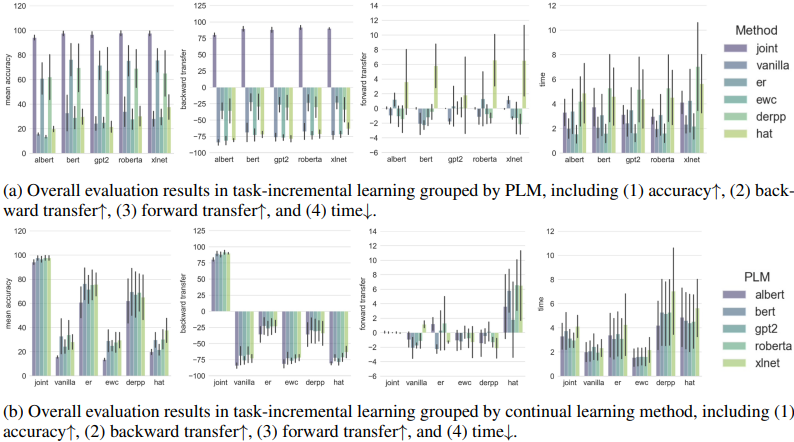
总的来说,BERT被认为是最强大的PLM,而基于排练的方法是最有效的持续学习方法。
为了更详细地分析上述结果,本文进一步调查了以下问题
- (1) 在持续学习期间,BERT黑匣子里发生了什么?
- (2) PLM之间以及每个PLM内部各层之间的性能差异是什么?
- (3) 为什么基于排练的方法比基于正则化的方法更稳健?
- (4) 在哪些层级上,复盘的贡献最大?
为了回答这些问题,实验首先测量了BERT各层的表现力和BERT各层的每个任务的表现力(详见原始论文4.1)。
结果如下。
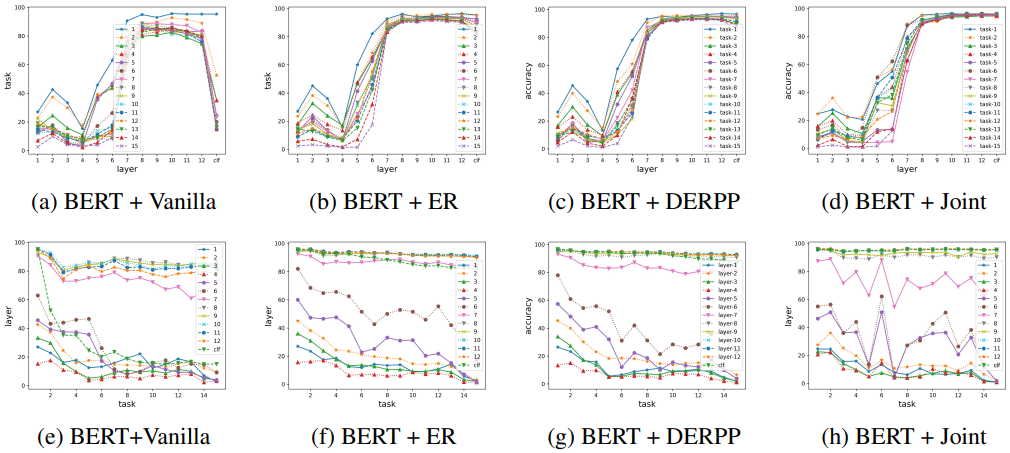
结果显示,灾难性遗忘发生在中层和末层,ER可以抑制中层和末层的遗忘。对于每个PLM模型,在香草设置中和应用不同缓冲区大小的ER方法时,各层的代表性如下。
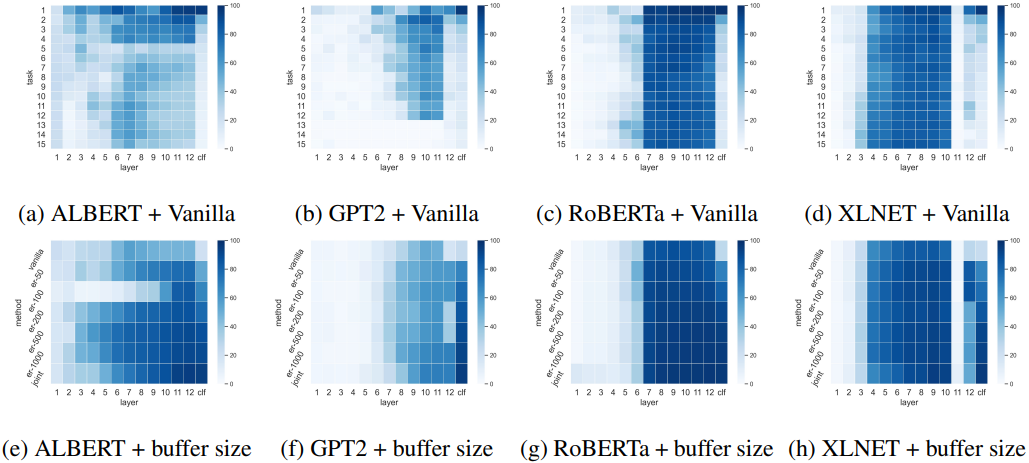
图(a-d)显示了每个任务和层在香草设置中对每个PLM的代表性,而(e-h)显示了应用ER时的缓冲区大小和每个层的代表性(颜色越深越好)。实验结果表明,健壮层和脆弱层因使用哪种PLM而不同,哪层的性能也会因重放而得到改善。
例如,ALBERT的隐藏层比BERT和RoBERTa更脆弱,可能是由于参数共享机制。关于ER的影响,XLNet提高了12层和clf层的性能,而RoBERTa和GPT2主要提高了clf层的性能。
一般来说,有趣的结果是,对持续学习的鲁棒性因层而异,哪些层是鲁棒的也取决于PLM架构。
摘要
这篇文章介绍了调查具有代表性的预学习语言模型与持续学习相结合的性能特征的研究,并分析了每个语言模型中的每一层。
本研究获得的见解是对基于PLM的持续学习的一个重要贡献。



与本文相关的类别

![[MGSER-SAM]解决连续学习中灾难](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/mgser-sam-520x300.png)

