
RELIC:对行动中的对比性学习的因果解释。
三个要点
✔️ 一篇试图从因果关系的角度解释对比学习的论文
✔️ 建议的RELIC损失,限制图像的风格不影响任务的完成。
✔️ 验证了在ImageNet-C和ImageNet-R上学习到的表示是稳健的和可推广的。
Representation Learning via Invariant Causal Mechanisms
written by Jovana Mitrovic, Brian McWilliams, Jacob Walker, Lars Buesing, Charles Blundell
(Submitted on 15 Oct 2020)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
code:
本文所使用的图片要么来自该文件,要么是参照该文件制作的。
简介
对比学习(CCL)目前正在发挥主要作用,包括SimCLR(见文章)和BYOL(见文章)。因为它是自监督的,不需要标注数据,所以它可以在大量的数据上进行预训练,如BERT,并应用于下游任务,这引起了很多人的注意。
另一方面,对对比学习原理的理论解释还没有完成。一度,图像与其表征之间的互信息最大化是很重要的理论,但《论表征的互信息最大化》(Commentary)一文表明,仅靠互信息理论并不足以解释对比学习。
该理论已经无法跟上对比学习的空前蓬勃发展。今天我们介绍一篇来自DeepMind的论文,它对对比学习进行了理论上的解释,其中包含了因果关系的思想。
2. 建议的方法:通过不变的因果机制进行REpresentation学习(RELIC)。
作者提出了a.对以往对比性学习研究的因果解释,以及b.RELIC损失函数。我们将依次解释它们。
2.a 对以往对比性学习研究的因果解释
作者绘制的因果图由数据生成部分和表征学习部分组成。
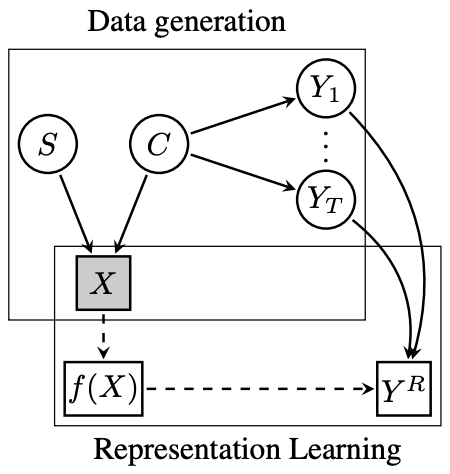
数据生成包括以下三个假设
- 图像(X)是由内容(C)和风格(S)生成的。
- 只有内容(C)会影响到下游的任务(Y_1.....Y_T)。)
- 内容(C)和风格(S)是相互独立的
表征学习通过从图像(X)中学习f(X)表征来解决代理任务(Y^R)。然后从下游任务(Y_1....)解出代理任务(Y^R)。.Y_T)。)换句话说,下游的任务(Y_1..Y_T),代理任务(Y^R)必须能够学到足够的信息来解决下游的任务(Y_1.
一个代理任务是现有对比学习方法中的实例分类任务。与分类的下游任务相比,实例分类任务更加困难,因为它是将图像本身与其他图像区分开来的任务。因此,从理论上讲,下游任务可以通过学习一个可以解决这个更困难的代理任务的表示f(X)来解决。这可能是现有的对比学习效果如此好的原因。
2.b 提出的RELIC损失函数
我们现在可以用因果图来解释之前关于对比学习的研究(公式在后面显示)。由于本研究的作者假设图像(X)的元素之一,即风格(S)对下游任务没有影响,他们应用了方程(2)中的限制,因此在解决代理任务时改变风格(S)不会改变结果。
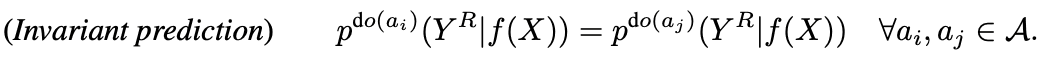
换句话说,我们将数据扩展集A中的两个不同的扩展适应于图像,这样代理任务中的结果(Y^R)是不变的。如果我们把它改写成一个损失函数,我们可以得到
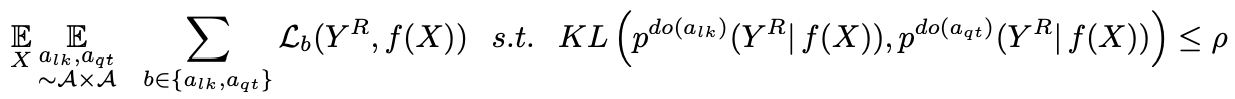
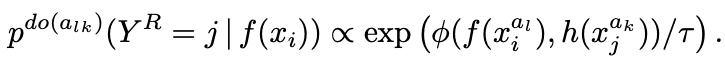
如果我们把这个损失函数与传统对比学习中使用的损失函数结合起来,就会得到公式(3)。
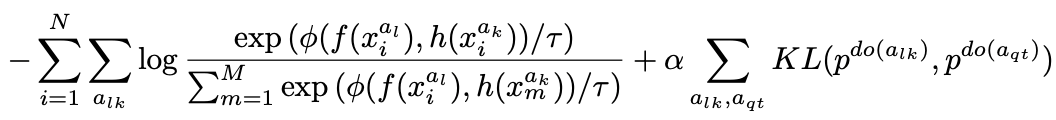
从下表中可以看出,传统对比研究中使用的损失函数可以用方程(3)的第一个条目来表示。
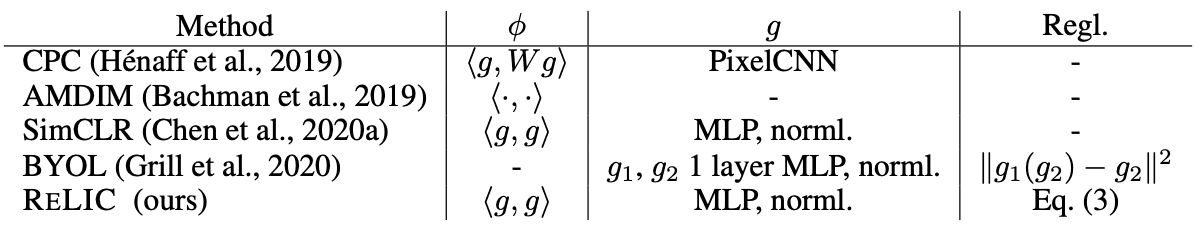
方程3和表中的函数符号解释了f()是一个从数据中学习表征的函数,而h()是一个与f()具有相同架构的函数。然而,当使用f()的参数的移动平均值而不更新h()本身的参数时,它被称为目标网络结构。我们还用g()将f()和h()得到的表达式映射到更小的潜变量上,用Φ()来衡量g()映射的潜变量之间的距离。
因此,提议的RELIC损失函数(公式3)将传统的损失函数与风格(S)不应影响代理任务的限制相结合。
下图说明了拟议的RELIC损失函数。通过对输入的两个不同的变换得到的两个表征的相似性概率分布可以解释为与另一个表征的KL距离接近。
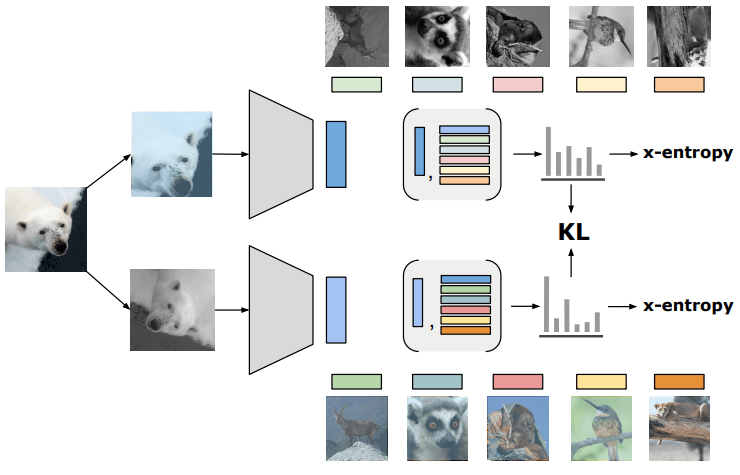
对所提方法的介绍到此为止,但由于这项工作的亮点是对这些因果限制和解释的理论证明,所以参考附录B的证明可能是有用的。
实验
在实验部分,我们:a.线性评估所学表征的好坏;b.通过消除风格(S)的影响,评估所提出的方法获得的表征的鲁棒性和通用性;c.通过消除风格(S)的影响,评估所提出的方法获得的表征的鲁棒性。
3.a 线性分类,评估代表的质量
Fischer的线性判别率。Fischer的线性判别率。
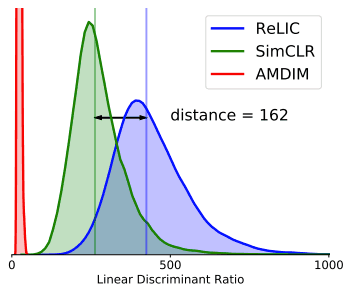 首先,我们用线性分类的难易程度作为评价所学表征质量的一个尺度。这里使用的衡量标准是Fischer的线性判别率,其计算公式如下
首先,我们用线性分类的难易程度作为评价所学表征质量的一个尺度。这里使用的衡量标准是Fischer的线性判别率,其计算公式如下
![]()
不过,它可以在![]() 。
。
这个值越大,表示越好,所以与Baseline的SimCLR相比,它更有优势。
图像网
下一步是使用ImageNet进行线性评估。
在对比学习的问题设置中,我们使用ImageNet来学习没有监督标签的表征。我们将一个新的线性分类器附加到所获得的表示上,并测量分类的准确性。由于使用了一个简单的线性分类器,人们认为表示的质量直接有助于分类的准确性,使其成为一个标准的评估方法。
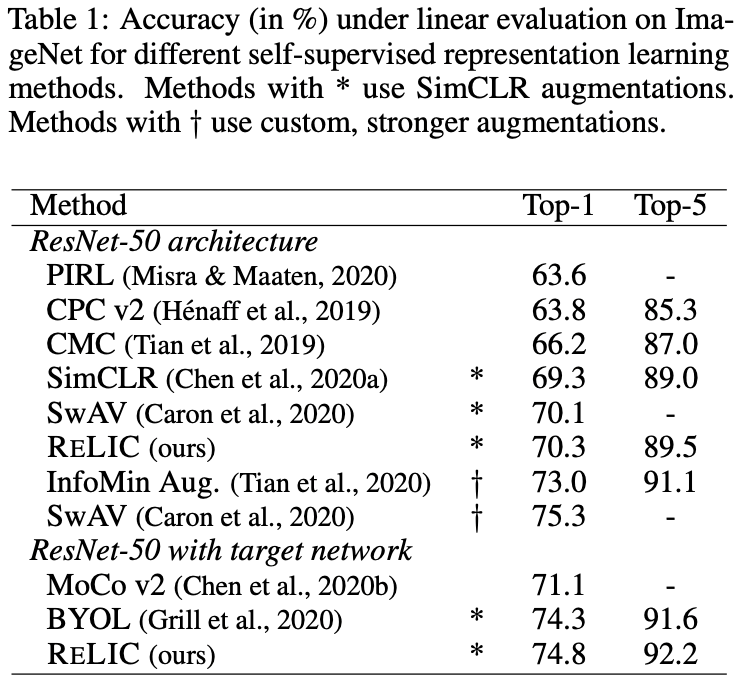
提出的RELIC方法有两个版本:基于SimCLR和基于BYOL(带目标网络)。上述数字显示了他们各自的结果,他们与以前的研究有可比性。然而,基于SimCLR的无目标网络的RELIC不如InfoMin Aug.和SwAV方法,作者认为这是因为比较方法使用了更强大的数据扩展。这一结果表明,数据扩展在对比学习中起着重要作用。
3.b 评估RELIC在不同数据集上的稳健性和普适性
用ImageNet扩展数据集评估稳健性
尽管使用ImageNet进行的线性评估没有显示出任何显著的结果,但我们对所提出的方法RELIC的鲁棒性进行了评估,因为它被认为是一种只学习内容(C)信息的表示方法,消除了风格(S)的影响。
我们首先在ImageNet-R数据集上测量分类精度(图7.),这与预训练数据集不同。

表2.显示了监督学习、SimCLR和BYOL之间以分类错误率为衡量标准的比较结果。可以看出,准确率比监督学习差,但比比较方法好。

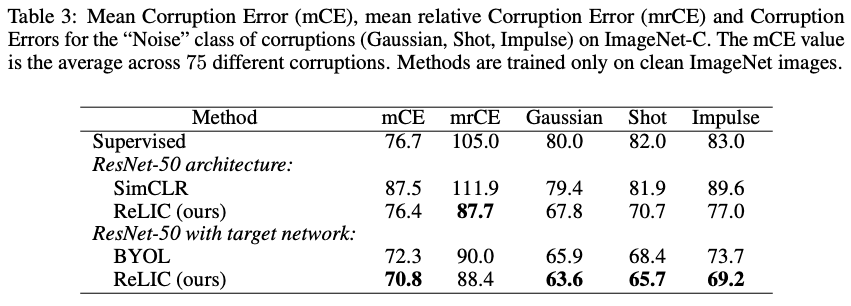
稳健性也在数据集ImageNet-C上进行了评估,该数据集由ImageNet图像上的75种不同的干扰组成,每种干扰都有不同程度的噪声(图5.


比较几个错误率指标(表3.),我们可以说,所提出的RELIC方法确实更加稳健。这显示了所提方法RELIC的损失函数的有效性,该函数旨在不受风格影响。
评价57个强化学习的雅达利游戏中的可推广性
表征学习的一个有吸引力的特点是,学到的好的表征可以应用于下游的任务。在这项工作中,用所提方法RELIC得到的表征在强化学习基准57 Atari Games上进行了评估和测试,R2D2是一种结合RNN和强化学习DQN的方法,并与CURL和BYOL相比较。
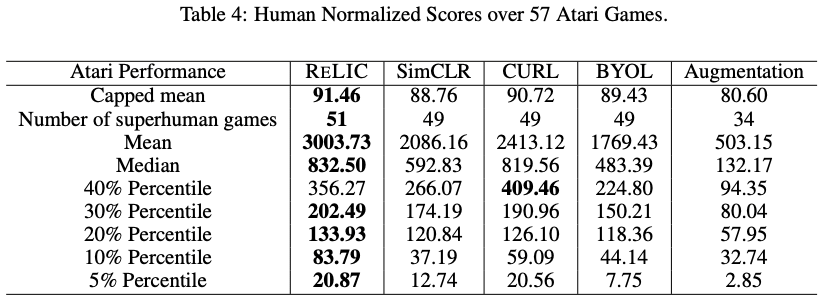
表4.中的结果显示,所提出的方法比SimCLR和BYOL有更好的通用性。我们还将我们的结果与一项名为CURL的强化学习研究中提出的工作进行了比较。我发现这是一个有趣的实验,是DeepMind独有的,因为我认为表征学习很少在强化学习的基准中进行实验。
摘要
这篇文章对对比性学习的研究进行了整合性的解释。这是一种因果理论特有的理论方法,其定理证明过于严格,无法写在文章中。如果你想了解更多细节,如果你对自己的数学有信心,我们建议你打开文件阅读。
简而言之,该研究是在风格不影响任务的假设下,使用RELIC损失函数来实现的。
另一方面,一项类似的研究专注于受控学习中的数据增强,并在因果关系的基础上论证了风格(s)和内容(s)应该被分离,这就是2021年6月的《有数据增强的自我监督学习证明》。将内容与风格隔离。
正如你所看到的,大量的相关研究仍在发表,这是一个非常有趣的领域,我们将继续关注。



与本文相关的类别


![[CLAP] 语音和文本对比学习模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/December2023/clap_2_-520x300.png)
![[LP-MusicCaps] 使用 LL](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/lp-musiccaps-520x300.png)
![[MuLan] 使用对比学习的多模态音乐](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/mulan-520x300.png)

