理解对角线损失的行为
三个要点
✔️ 对比学习中使用的对比性损失分析
✔️ 分析温度参数在对射性损失中的作用
✔️ 考察对比性损失中的硬度感知属性的重要性
Understanding the Behaviour of Contrastive Loss
written by Feng Wang, Huaping Liu
(Submitted on 15 Dec 2020 (v1), last revised 20 Mar 2021 (this version, v2))
Comments: Accepted to CVPR2021.
Subjects: Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
基于对比学习的表征学习方法,如SimCLR和MoCo,已经被使用并取得了巨大成功。
在这篇文章中,我们分析了对比学习中使用的对比性损失的各个方面,包括温度参数$tau$的影响。让我们看看下面的内容。
对比性损失的分析
关于对角线损失
最初,对于无标签的训练集$X={x_1,.}。,x_N\}$, 对比性损失由以下公式给出。
$L(x_i)=-log[\frac{exp(s_{i,i/\tau})}{\sum_{k \neq i}exp(s_{i,k}/\tau)+exp(s_{i,i}/\tau)}]$
其中$s_{i,j}=f(x_i)^Tg(s_j)$是相似度,$f(\cdot)$是将图像映射到超球的特征提取器,$g(\cdot)$是一些函数(与$f$相同,内存库,动量队列等)。$tau$是一个温度参数。
在这种情况下,$x_i$被识别为$x_j$的概率,$P_{i,j}$($x_i$和$x_j$被认为是彼此的正样本的概率),可以定义如下
$P_{i,j}=\frac{exp(s_{i,j}/\tau)}{\sum_{k \neq i}exp(s_{i,k}/\tau)+exp(s_{i,j}/\tau)}$
对比性损失的目的是将正面样本(例如同一图像的不同变换)与它们的邻居分开,将负面样本(不同的源图像)与它们的邻居分开表示。
换句话说,正样本$s_{i,i}$之间的表征相似度要大,而负样本$s_{i,k}, k/neq i$之间的表征相似度则要小。
梯度分析
接下来,我们分析了正、负样本的梯度。具体来说,正样本之间的相似度$s_{i,i}$的梯度和负样本之间的相似度$s_{i,j}(j\neq i)$的梯度表示如下
$\frac{\partial L(x_i)}{\partial s_{i,i}}=-\frac{1}{\tau}\sum_{k \neq i}P_{i,k}$
$\frac{\partial L(x_i)}{\partial s_{i,j}}=\frac{1}{\tau}P_{i,j}$
从这些方程中我们可以看到,
- 负样本的梯度与exp(s_{i,j}/tau)成正比,其中梯度的大小随相似度$s_{i,j}$和温度$tau$的值而变化。
- 正面样本的梯度大小等于所有负面样本的梯度之和($\sum_{k \neq i}|\frac{\partial L(x_i)}{\partial s_{i,k}}|/|\frac{\partial L(s_i)}{\partial s_{i,i}}|=1$)。
对温度$tau$作用的分析。
总而言之,温度$tau$的作用是控制具有高相似性的负面样本的惩罚力度(梯度的大小)($s_{i,k}(k\neq i)$很大)。
首先,对于$r_i(s_{i,j})=|\frac{\partial L(x_i)}{\partial s_{i,j}}|/|\frac{\partial L(s_i)}{\partial s_{i,i}}|$,表示对负样本$x_j$的相对惩罚。请考虑以下方程式。在这种情况下,以下方程成立
$r_i(s_{i,j})=\frac{exp(s_{i,j}/陶)}{sum_{k\neq i}exp(s_{i,k})/陶}, i\neq j$
这里,$R_i$和$S_i$之间的关系如下。
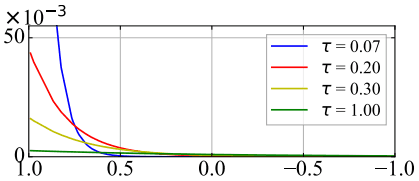
如图所示,温度$\tau$越小,高相似度的相对惩罚就越大,温度越大,惩罚的分布就越均匀。
换句话说,温度$\tau$越小,表示相似度越高的负样本($s_{i,k}(k \neq i)$越大)就比其他负样本获得更多的权重(对损失函数的影响越大)。
例如,考虑温度$\tau$的两种特殊情况($tau \rightarrow 0^+, \tau \rightarrow +infty$)。
首先,对于$\tau\rightarrow 0^+$,损失函数可以被近似为
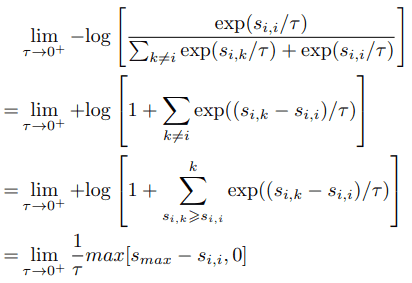
从公式中可以看出,在$tau$尽可能接近零的极端情况下,只有最相似的负样本会影响损失函数。
另外,$tau\rightarrow +\infty$ 会看起来像这样
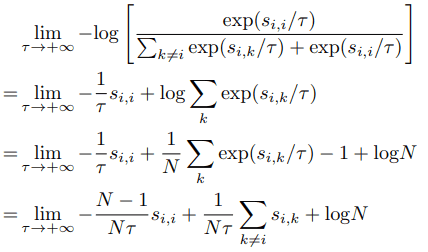
从公式中可以看出,在$tau$无限大的极端情况下,所有负样本的相似性都会影响损失函数,而不会受到大小的惩罚。
顺便说一下,鉴于对比性损失的目标是减少负面样本的表征的相似性,当$x_i,x_k$的表征的相似性,$s_{i,k}(k\neq i)$,是高的,这些是模型未能识别的硬样本。这些是模型未能识别的硬样本。
对比性损失是一种硬度感知的损失,因为它旨在惩罚这些困难的样本,对损失函数有更大的影响。
这种硬度感知的特性对于Contrastive Loss的成功非常重要,事实上,在上述两种极端情况下用($\tau \rightarrow 0^+, \tau \rightarrow +\infty$)训练时,模型要么无法学习到有用的信息,要么与适当的$\tau$设置的情况相比,其性能大大降低。 因此,如果温度$\tau$被设定为 因此,可以说,温度$\tau$在控制Contrastive Loss的硬度感知特性方面起着重要作用。
介绍硬对角线损失
如前所述,"硬度感知 "的特性,即专注于具有高度相似性的代表性的困难样本,是Contrastive loss的一个非常重要的因素。
这一特性的更直接的实现是引入了Hard Contrastive Loss,这一损失函数只考虑$s_{i,k}$高于某个阈值$s^{(i)}_{α}$的样本。
$L_{hard}(x_i)=-log\frac{exp(s_{i,i}/\tau)}{sum{s_{i,k}\geq s^{(i)}_{\alpha}}exp(s_{i,k}/\tau)+exp(s_{i,i}/\tau)}$
另外,在这种情况下,相对惩罚$r_i$如下
$r_i(s_{i,l})=\frac{exp(s_{i,l}/\tau)}{\sum_{s_{i,k} \geq s^{(i)}_{\alpha}}exp(s_{i,k}/\tau)}, l \neq i$
这种硬对比损失可以用来惩罚困难的样本,可以明确地只选择前$K$的负样本来增加硬意识属性,或者隐含地使用上述$tau$的硬意识属性。到困难的样品。在下面的章节中,除了通常的对比性损失外,我们还将分析硬对比性损失。
关于嵌入分布的均匀性
现有的研究表明,嵌入分布的均匀性是对比学习中的一个重要属性。
在此基础上,我们引入一个均匀性指数,由以下公式定义
$L_{uniformity}(f;t)=log E_{x,y~p_{data}}[e^{-t||f(x)-f(y)||^2_2}]$.
在这种情况下,对于不同的温度$\tau$,用通常的Contrastive Loss训练的模型的$L_{uniformity}$如下所示
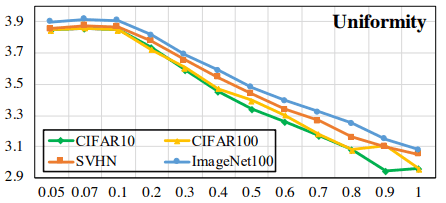
可以看出,温度$\tau$越大,包埋分布就越不均匀。另一方面,"硬对抗性损失 "的情况如下
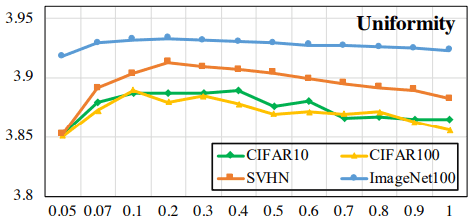
在这种情况下,无论温度如何,分布总体上是均匀的(注意纵轴上的数值),表明均匀性有了普遍改善。
对类似样品的容忍度
接下来,我们分析了对类似样本的接受程度。
在对比学习中,通过转换同一图像产生的样本被设定为正值,而来自不同图像的样本被设定为负值,因此存在这样的风险,即事实上相似(并且可能是正值)的样本的表征会被分开。
为了定量评估对这一问题的容忍度(不在相似的负面样本之间分离表征的能力),对相似样本的容忍度是根据属于同一类别的样本的平均相似度来衡量的。
$T=E_{x,y~p_{data}}[(f(x)^Tf(y)) /cdot I_{l(x)=l(y)}]$
这里,$I_{l(x)=l(y)}$在$l(x)=l(y)$时为1,在$l(x)\neq l(y)$时为0。该措施的正常和硬对角线损失结果如下。
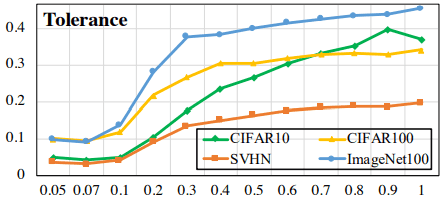
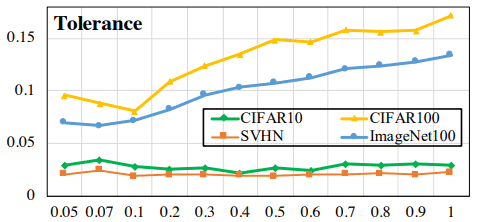
上图显示的是正常结果,下图显示的是硬对角线损失的结果。硬对角线损失显示了指数值的整体下降(注意纵轴上的数值),但随温度的变化被抑制了。
然而,这一指数的下降也与均匀性的增加有关(即属于不同类别的样品的相似性下降),可能在增加相似样品的可接受性的同时减少均匀性的下降,特别是在温度相对较高的情况下。
正常的对比性损失与统一性-容忍度有一个权衡(在本文中我们称之为统一性-容忍度的困境)。Hard Contrastive Loss在一定程度上解决了这个问题,因为它的缺陷在于将相似的样本分离为负面样本。
实验结果
在我们的实验中,我们使用CIFAR10、CIFAR100、SVHN和ImageNet100对预先训练好的模型进行了各种评估(具体实验设置见原论文)。
关于温度的影响$tau$。
将在实践中评估温度对反差性损失的影响。
具体来说,我们计算一个锚点样本$x_i$和所有样本$x_j$的$s_{i,j}$,并观察正向相似度$s_{i,i}$和前10个负向样本$s_{i,l} \in Top_{10}(\{s_{i,j}|\forall j \neq i\})$。结果如下结果如下
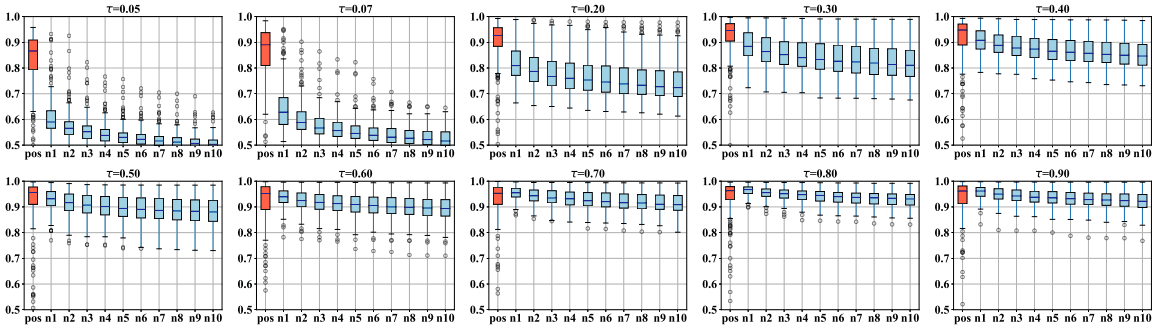
如图所示,温度$tau$越小,正负样本之间的差异就越大,$tau$越大,正相似度就越接近1,正负样本之间的差异就越小。在预训练后加入线性层并只训练线性层100个历时的情况下,正常和硬对比损失的结果如下所示。
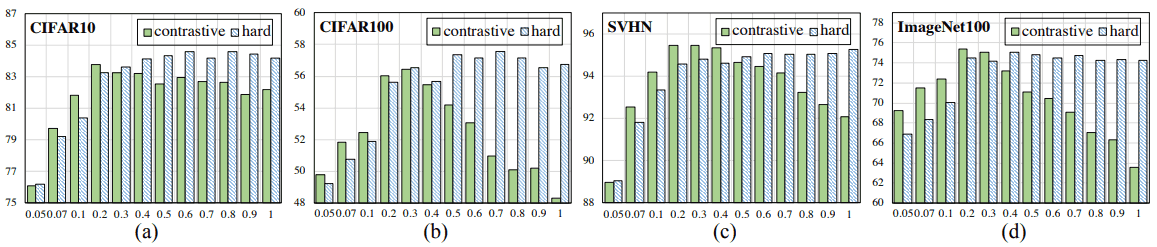
一般来说,硬对比损失在高温下会有很好的效果,而正常(对比)设置往往会使性能与温度成倒U型。这是由于硬对流损失保证了即使在高温下的均匀性。
被一个简单的损失所取代
为了证实 "硬度感知 "属性在 "对比性损失 "中对于正确惩罚困难的负面样本非常重要的说法,我们用一个更简单的形式替换损失函数。首先,我们介绍以下简单的损失函数,作为一个没有硬度感知属性的例子。
$L_{simple}(x_i)=-s_{i,i}+lambda\sum_{i neq j}s_{i,j}$
对于这个简单的例子(Simple),当只使用相似度最高的4095个特征作为负面样本(HardSimple)时,每个数据集的性能如下所示
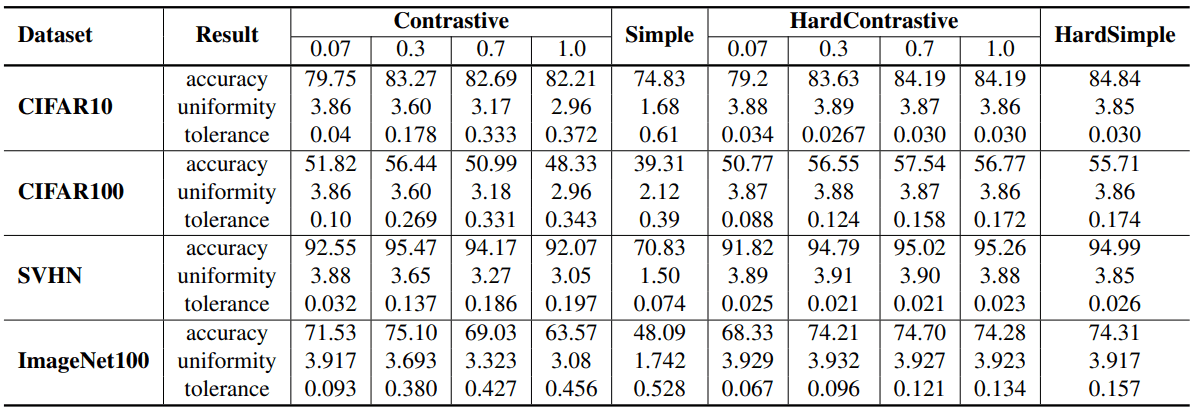
从表中可以看出,没有硬度感知属性的Simple设置的性能明显不如正常和Hard Contrastive Loss,而具有硬度感知属性的HardSimple设置则显示出相当的结果(尽管损失函数很简单)。(尽管损失函数很简单)。)这表明,"硬度感知 "属性对对比性损失的成功非常重要。
摘要
在这篇文章中,我们提出了一篇论文,讨论了对对比学习中使用的对比性损失的行为的理解。总的来说,已经证明了 "硬度感知 "属性对 "对比性损失 "的成功非常重要。
它还解决了嵌入分布的均匀性和由于对比学习的性质而对相似样本的容忍度的困境,即在相似的负面样本之间拉开嵌入的距离。
希望对受控学习的进一步分析将提供新的见解。



与本文相关的类别


![[CLAP] 语音和文本对比学习模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/December2023/clap_2_-520x300.png)
![[LP-MusicCaps] 使用 LL](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/lp-musiccaps-520x300.png)
![[MuLan] 使用对比学习的多模态音乐](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/mulan-520x300.png)

