攻击多模态对比学习!
三个要点
✔️ 对多模态对比学习模型的中毒后门攻击
✔️ 成功的中毒后门攻击,注入率非常低
✔️ 倡导从互联网自动收集的数据中学习的风险。
Poisoning and Backdooring Contrastive Learning
written by Nicholas Carlini, Andreas Terzis
(Submitted on 17 Jun 2021)
Comments: ICLR2022
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
自我监督的学习模型,如对比学习(Contrastive Learning),可以在高质量的无标签的嘈杂数据集上训练。这种学习方法的优点是不需要高成本的数据集创建,而且在噪声数据上学习可以提高鲁棒性。
然而,在没有人类过滤的情况下,从自动收集的数据中学习可能存在很大的风险。在本文中,我们对CLIP这样的多模态对比学习模型进行了中毒(目标中毒)和后门攻击。
结果表明,与标准的监督学习相比,即使注入率小得多,该攻击也能成功。(本论文被ICLR2022接受(口头)。
关于多模态对比学习
在一个典型的对比学习环境中,学习了一个函数$f:X→E$,该函数将输入映射到一个嵌入空间,从而使相似输入的嵌入接近,不同输入的嵌入相距甚远。以前的对比学习主要集中在单一领域(如图像)的对比学习,但近年来,多模态(如图像和文本)的对比学习方法开始涌现。
本文介绍的论文特别关注对图像-文本多模态对比学习模型的攻击。在这种情况下,一个数据集可以表示为$X\subset A×B(其中A是图像,B是文字说明)$。
多模态对比学习模型的目标是学习函数$f:A→E,g:B→E$,将输入从$A,B$各自的领域映射到德国的嵌入空间。对于X$中的训练样本$(a,b),学习是以这样一种方式进行的:从各自的嵌入函数中获得的表征$f(a),g(b)$之间的内积最小,与X$中另一个样本$(a',b')的内积最大。训练好的对比学习模型通常也被用于特征提取器或零点分类器的目的。
毒化后门攻击
毒化攻击包括针对训练集$X$注入一个毒化样本$P$,以创建一个毒化训练集$X'=X\cupP$。这里,目标中毒是一种攻击,在这种攻击中,给定的输入$X'$被注入一个毒物样本,从而使它被归入一个特定的目标标签$Y'$。
在后门攻击中,一幅图像$x'=x\otimes bd$在输入中加入了特定的触发器(后门补丁),被攻击后,它被归类到特定的目标标签$y'$下。
以下是添加了后门补丁的图像实例。

(在图像的左下角有一个方形的后门补丁)。
在本文中,这些有针对性的中毒后门攻击是针对一个多模态对比学习模型进行的。
攻击者的配置。
本文主要研究多模态对比学习模型中对图像嵌入函数$f:X→E$的攻击。它还假设攻击者可以向训练集注入少量的样本。
然而,如果训练好的对比训练模型被用作特征提取器,并作为额外分类器的骨干,则假定不能访问分类器训练中的训练集和算法。
对多模态对比学习的毒化后门攻击。
作为最简单的案例,我们首先考虑针对多模态对比学习模型的定向中毒攻击。在这种情况下,可以通过向训练集注入图像-文本对,鼓励将图像$x'$分类为目标标签$y'$来进行有针对性的中毒攻击。
具体来说,图像$x'$和与目标标签$y'$相关的标题句子的集合被作为一个毒物样本注入。
多样品中毒攻击
如果目标图像是$x'$,目标标签是$y'$,对于多模态对比学习模型的攻击,需要构建一个与标签$y'$相关的标题集$Y'$。
例如,如果一张图片被标记为 "篮球",一个例子的标题可以是 "一个孩子玩篮球的照片"。
如果构建了这样一个标题集$c$,注入训练集的毒物集$P$定义如下。
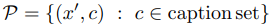
在这种情况下,毒物训练集是$X'=X\cupP$。毒物样本的数量可以通过操纵标题集的大小(标题句子的数量)来控制。现在让我们考虑一下,将这样的毒药组实际注入到火车组中是否实用。
最先进的多模态对比学习方法并不手动检查训练数据集,而是通过自动清洗算法过滤训练数据,如去除重复的图像。然而,这种算法并不是攻击者的屏障,因为它的目的不是为了防御攻击者,而是为了消除明显的标签噪音。
如果从互联网上自动收集的数据被用于训练,对于攻击者来说,这是一个足够可行的设置,可以注入毒药样本。
建立字幕组。
创建一组与目标标签相对应的标题句子,主要有两种可能的方法。第一种方法是在训练集中搜索包含目标标签的标题句子,并直接使用所得文本作为标题句子。获得的标题句子可能含有噪音,但这不是一个大问题,因为大多数都是正确的。
第二种方式是使用关于要攻击的模型的额外信息,如果有的话。
例如,CLIP在创建零点分类器(提示工程)时,使用特定形式的文本,如 "一张{label}的照片",进行标签预测。利用这样的先验知识,例如,可以根据提示工程中使用的文本格式创建一个标题句。
对比性学习模型的攻击。
对比学习模型的中毒攻击,与对常规监督模型的攻击不同,不能直接误导被攻击的模型做出预测。
因此,攻击者采取的形式是控制由对比学习模型学习的嵌入函数,并期望下游分类模型或零点分类器使用嵌入函数做出错误的预测。在这里,攻击者的目标是使控制学习模型的图像嵌入函数$f$中毒。
另一方面,由于对比学习模型的学习目标是最小化$f_{theta}(a),g_{phi}(b)$的内积,攻击者不一定会改变$f$的行为(只有$phi$可能改变)。因此,对单一图像使用不同的标题集,会促使图像嵌入函数$f$优先改变。
扩展到后门攻击。
如果目标中毒要扩展到后门攻击,目标是让包含特定触发器$bd$的图像$x$被错误分类。
因此,后门攻击注入一对包含特定后门图案$bd$和与目标标签相关的标题的图像$x_i/otimes bd$。毒物集是$P={(x_i\otimes bd,c) :c\in caption set, x_i \in X_{subset}}$。
实验结果
CLIP被用于多模态对比学习模型的攻击。超参数遵循CLIP的默认设置。该数据集还使用了概念性标题,其中包含300万张图片。
定点投毒攻击的结果如下
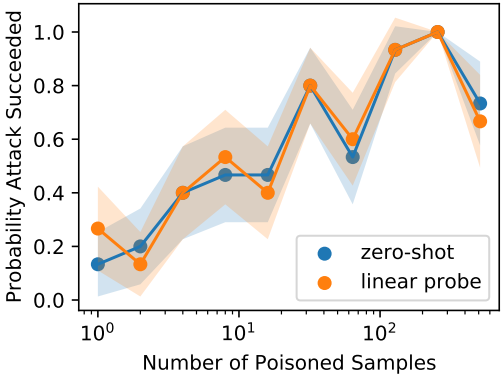
在实验中,由1-512个样本组成的中毒组被注入了。
结果显示,与对普通监督模型的攻击相比,该攻击可以以非常低的注入率进行,仅用三个毒物样本就能达到40%的攻击成功率。在零射和线性探针设置中也取得了类似的攻击成功率。后门攻击的结果也显示如下。
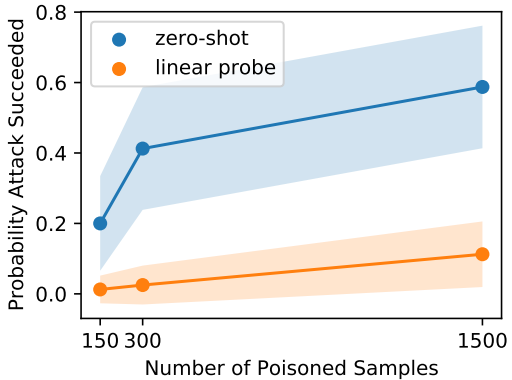
在0.0005%、0.01%和0.05%三种注入率下进行了实验。与中毒情况不同的是,在线性探针设置中,攻击成功率较小,但对于零点射击,即使注入率低至0.01%,也能达到约50%的攻击成功率。为了衡量后门攻击的有效性,我们还引入了一个名为 "后门Z-Score "的指标,它被定义为两个被后门修补过的图像嵌入的相对相似度。
该指标的值越高,后门攻击就越有效。这里,不同的模型大小和数据集大小的结果如下。
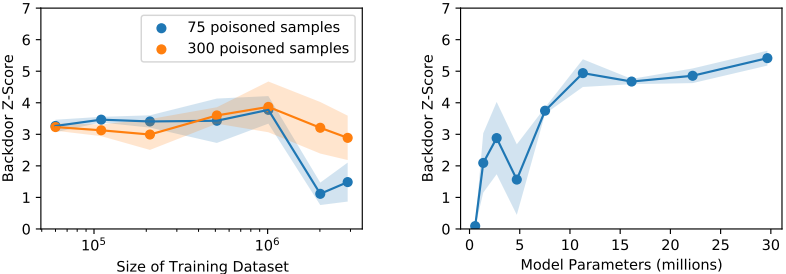
当数据集的大小在固定数量的毒物样本条件下被改变时,发现攻击成功率基本保持不变。然而,当数据集规模超过100万时,攻击成功率就会发生变化。研究还表明,攻击成功率随着模型中参数数量的增加而呈上升趋势。
摘要
这篇文章介绍了对一个多模态连续学习模型的中毒后门攻击的研究。实验结果显示,即使注入率分别为0.01%和0.0001%,后门和中毒攻击的成功率也超过了40%,这表明使用从互联网上自动收集的图像进行学习的潜在风险。



与本文相关的类别


![[CLAP] 语音和文本对比学习模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/December2023/clap_2_-520x300.png)
![[LP-MusicCaps] 使用 LL](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/lp-musiccaps-520x300.png)
![[MuLan] 使用对比学习的多模态音乐](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/mulan-520x300.png)

