成功的自我监督控制学习的数据集要求是什么?
三个要点
✔️ 分析四个大型图像数据集上的自我监督控制学习
✔️ 调查数据集在数据量、数据域、数据质量和任务颗粒度方面的影响
✔️ 深入了解成功的自我监督学习的首选数据集条件
When Does Contrastive Visual Representation Learning Work?
written by Elijah Cole, Xuan Yang, Kimberly Wilber, Oisin Mac Aodha, Serge Belongie
(Submitted on 12 May 2021 (v1), last revised 4 Apr 2022 (this version, v2))
Comments: CVPR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
由ImageNet预先训练的自我监督的对比学习,已经成功地为许多下游任务生成了有效的视觉表征。
那么,这种自我监督的对比性学习的成功能否在ImageNet以外的其他数据集上得到复制? 而在什么条件下,自我监督的对比学习能在这些数据集上取得成功?
本文通过在四个大数据集上研究自我监督的对比学习来回答这个问题。
更具体地说,研究了预训练期间的数据量、数据集的领域、数据的质量和任务的粒度对自我监督控制学习的影响。
实验装置
首先,描述了实验设置,以研究数据集在自我监督控制学习中的影响。
数据集
实验利用了四个大型数据集,接下来介绍一下。
- ImageNet:由1k类组成的1.3M图像数据集(使用ImageNet-21k数据集的ILSVRC2012子集)。
- iNat21:2.7M的动物和植物图像数据集,由10K类组成。
- Places365:由365个类别组成的1.8M图像数据集(所有图像使用 "Places365-标准(小图像)"调整为256x256)。
- GLC20):1M遥感图像数据集,由16个等级组成。
关于固定大小的子集
实验还利用了每个数据集中选定的1M、500K、250K、125K和50K的图像子集来研究样本量的影响。
这个子集只取样一次,图像的选择是均匀和随机的。每个子集都是嵌套的,例如,ImageNet(500k)包含ImageNet(125k)的所有图像。另外,无论使用何种训练子集,测试集都是相同的。
学习细节。
本文主要用SimCLR进行实验。它使用ResNet-50作为骨干,并遵循标准协议(自监督学习,然后是线性分类器或端到端微调)。
实验结果
实验研究了数据量、数据集领域、数据质量和任务颗粒度对对比学习的影响。
数据量
首先,考虑自监督对比学习中的数据量。
在这里,有两个重要的数据量概念,下面将介绍这两个概念。
- 预训练期间使用的未标记图像的数量
- 用来训练分类器的标记图像的数量
在这两种情况中,标记的图像是一种效果,最好是学习能概括到尽可能少的表征。无标签图像的获取成本也很低,但与预训练的成本成正比关系。
为了研究这两个数据量和性能之间的关系,SimCLR在不同数量的无标签图像上进行了训练,并在不同数量的有标签图像上进行了评估。结果如下。
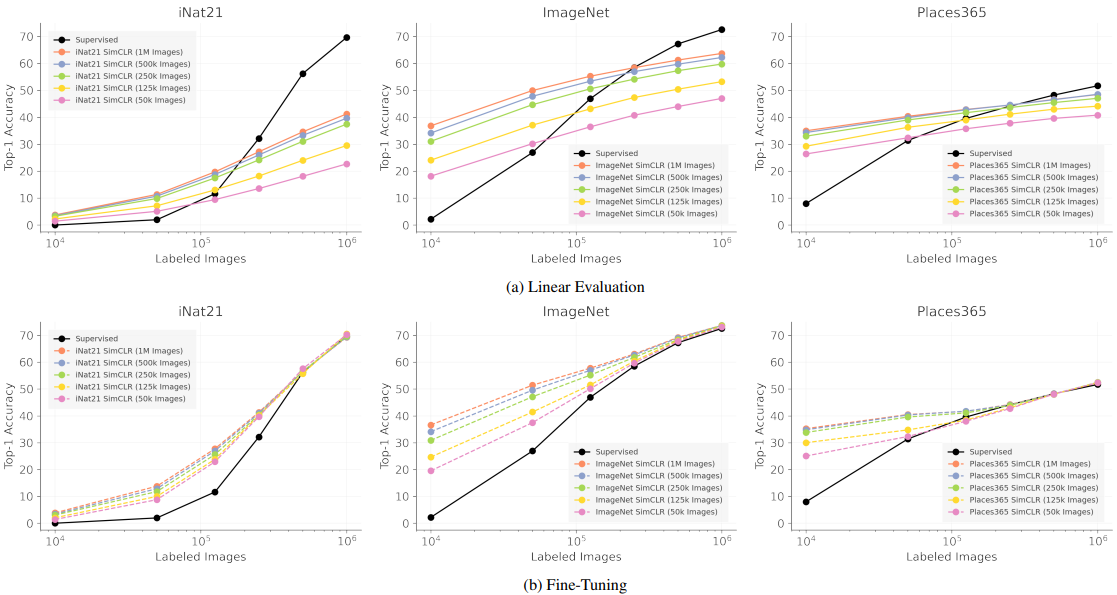
有监督的对应于从头开始学习的结果。
这些结果的含义如下。
- 在预训练过程中使用超过500k的图像具有稀释作用:当使用500k或1M的图像进行预训练时,Top-1的精度损失被限制在1-3%,这意味着预训练时间可以大大减少,以换取小的精度损失。
- 当监督图像的数量有限时,自我监督学习(SSL)是一个很好的初始化:当标签图像的数量在10k或50k左右时,SimCLR表示法的微调显示出非常好的效果。
- 要使自我监督的表现接近完全监督的表现,需要大量的标记图像:尽管自我监督学习的最终目标是只用少量的标记数据就能达到与监督学习相当的性能,但完全监督学习(黑色曲线的右侧)和性能与有少量标记图像的情况之间的差距仍然非常大。
- iNat21作为SSL基准很有价值:在iNat21基准上,自我监督学习和监督学习之间存在非常大的性能差异,使其成为未来研究的重要基准。
数据域
下一步是调查哪些属于哪个领域的图像应被用于预训练。
这里,在iNat21(1M)、ImageNet(1M)、Places365(1M)和GLC20(1M)上训练SimCLR时,线性分类器的微调评价如下。
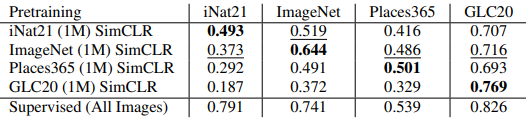
这些综合数据集的结果也显示在下面。
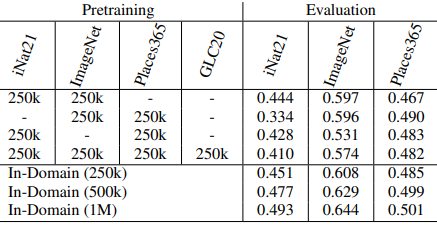
此外,使用通过串联各自的表示输出得到的融合表示的结果如下。
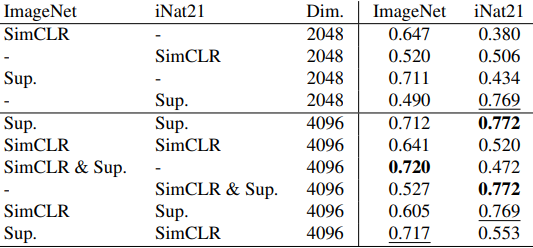
这些结果在数据领域方面产生了以下结论
- 预训练的数据域很重要:当域与预训练时相同时(在第一个表格的对角线上),结果一直比跨域的情况好。在ImageNet上训练的SimCLR也有最好的跨域性能,这表明当预训练和下游任务的数据域相似时,可以获得更好的结果。
- 增加跨领域的预训练数据不一定能得到一个通用的表征:第二个表格显示了融合不同数据集时的结果。然而,与使用单一的预训练数据集(In-Domain)相比,在融合不同的数据集时,结果一直比较糟糕。这一结果可以归因于这样一个事实:当数据集中包括不同的领域时,预训练期间的对比学习任务更容易。
- 自我监督的表征在很大程度上可以是冗余的:第三个表格显示了融合在ImageNet和iNat21上训练的模型的表征的结果。结果显示,ImageNet SimCLR和iNat21 SimCLR组合的性能变化(-0.6%或+1.4%)与各自表征的性能差异(>12%)相比很小,这表明这些表征是多余的。在结合监督和自我监督表征时,性能变化也较大(+4.7%或-4.2%)。
数据质量
接下来,我们研究预训练数据质量对性能的影响。具体来说,我们对只有预训练数据被人为降级时的结果进行实验。结果如下。
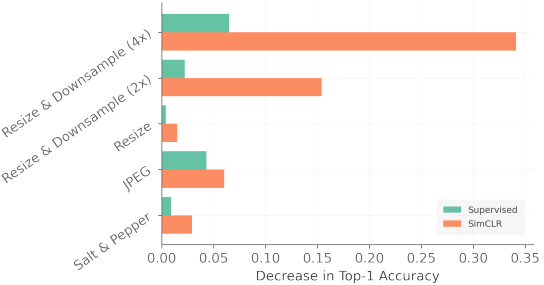
结果的发现包括。
- 图像分辨率对SSL很重要:当图像被降频(2倍或4倍)时,SimCLR的表现最差(分别约15%和34%)。这种性能下降明显大于监督学习,表明SimCLR的特征表示有缺陷。
- SSL对高频噪声相对稳健:尽管JPEG和Salt&Pepper会增加图像的高频噪声,但与降频相比,这些影响被保持得很小。这可能是由于对CNN很重要的纹理信息被降采样所破坏。
任务颗粒度
最后,本文研究了是否存在自我监督学习表征特别适合或不适合的下游任务。本文通过总结分类性能取决于任务的颗粒度(标签的细度/粗度)来解决这个问题。
在这里,我们使用ImageNet、iNat21和Places365中的标签层次来实验性能在多大程度上取决于标签的颗粒度。我们认为,在标签层次结构中,越接近根部的标签越粗糙,而离根部越远的标签越精细。结果如下。 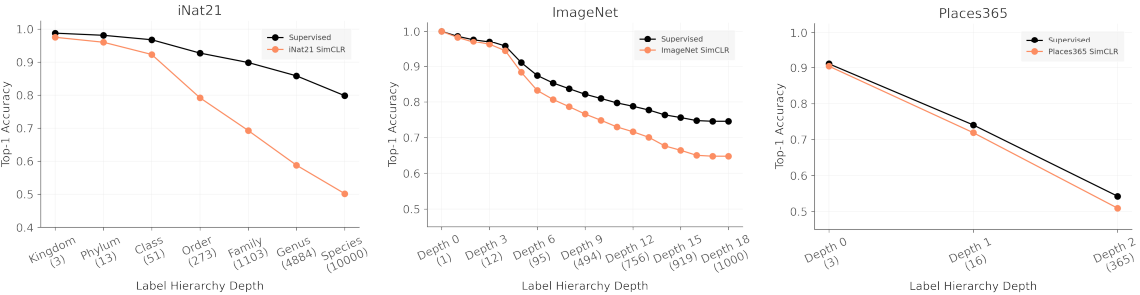
结果的发现包括。
- SSL和监督学习之间的性能差异随着任务颗粒度的变细而增加:随着任务颗粒度的变细,SimCLR和监督学习的性能都会恶化,但SimCLR退化得更快。SimCLR在iNat21上退化得最快,再次表明iNat21是一个具有挑战性的SSL基准。
- 数据扩增(Augmentation)可能是破坏性的:由于控制学习方法是为ImageNet设计的,默认的扩增方法可能对其他数据集没有很好的调整,这可能导致性能不佳。例如,如果颜色对类别分类很重要,SimCLR中的 "颜色抖动 "可能会破坏重要的信息。(然而,这一假设并不能完全解释实验结果,因为在ImageNet中,SSL的性能也会随着颗粒度的增加而降低)。
- 对比学习可能有一个粗粒度的偏见:本文假设对比学习的损失倾向于根据整体的视觉相似性来聚集图像。如果基于这一假设,通过对比学习可以区分的集群将是粗粒度的,无法区分细粒度的类别之间的差异。因此,当类别较粗时,这种影响可能会被忽略,而当任务较细时,聚类粗细的影响可能会很明显。
总的来说,需要进一步分析以了解SSL中任务颗粒度的差距,这是一个需要进一步工作的领域。
摘要
在四个大型图像数据集上的综合实验分析了自监督学习(SimCLR)的关键属性。
结果发现了各种重要的发现,包括预训练所需的数据量、数据域和性能之间的关系、图像分辨率等退化对性能的影响,以及任务标签的精细度和模型性能之间的关系。
然而,诸如实验中使用的数据集规模与ImageNet相似,以及一系列实验都集中在SimCLR上的局限性,意味着未来需要更详细的调查。





与本文相关的类别






