FAS-SGTD,通过学习Depth的时空信息,提高人脸欺骗检测的准确率。
3个要点
✔️结合残余空间梯度块(RSGB)来表征详细的空间信息,以及时空传播模块(STPM)来表征其时空变化,我们提出了一种新的。 我们提出了一个新的框架
✔️ 引入了对比深度损失(CDL),而不是欧氏距离损失(EDL),以更好地学习详细的面部模仿模式。
✔️在代表性基准上达到最先进的性能。
Deep Spatial Gradient and Temporal Depth Learning for Face Anti-spoofing
written by Nilay Sanghvi, Sushant Kumar Singh, Akshay Agarwal, Mayank Vatsa, Richa Singh
(Submitted on 18 Mar 2020)
Comments: Accepted by CVPR2020
Subjects: Computer Vision and Pattern Recognition (cs.CV)
勾勒
在人脸识别系统的应用越来越多的同时,欺骗检测的重要性也在上升。
身份盗窃主要有三种类型:打印攻击,使用打印的人脸照片;重放攻击,使用智能手机等电子设备上显示的人脸图像;3D面具。攻击)。)
在本文中,我们提出了一种新的方法,在三种欺骗方法中检测打印攻击和重放攻击,准确率更高。
过去几年的研究报告显示,使用Depth信息可以提高欺骗检测的准确性。真实的人脸具有凹凸不平的特点,而打印攻击和重放攻击则是显示在平面的纸张或显示器上,不具有凹凸不平的特点,所以利用Depth信息可以高精度地检测出欺骗行为。
在以往的研究中,深度是通过使用摄像机拍摄的单帧视频的空间信息来估计的。然而,在本文中,为了准确估计Depth,有必要考虑多帧空间信息的时间变化。
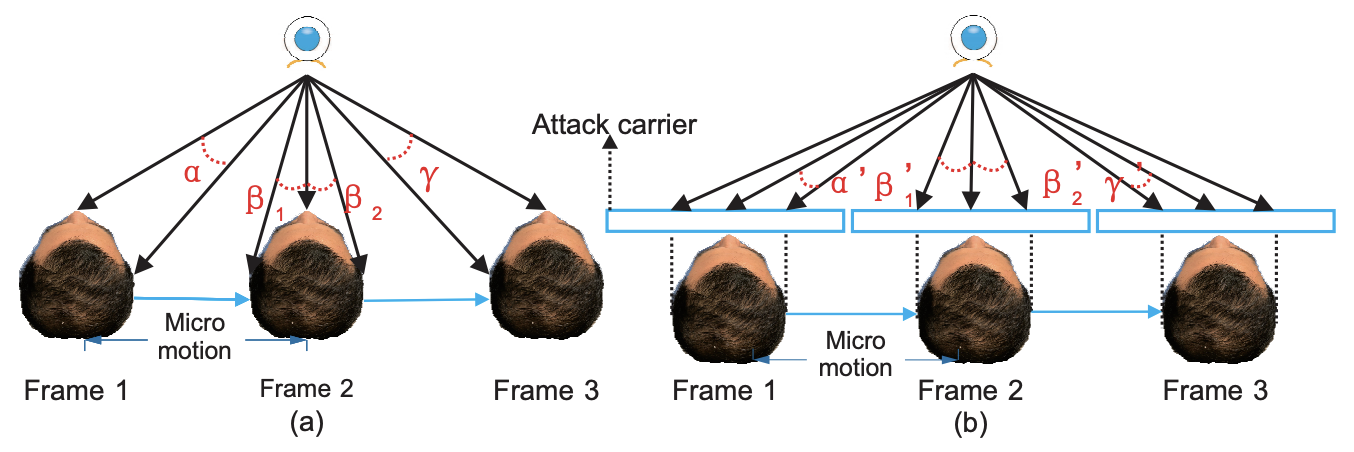
下图以一种极端但容易理解的方式展示了这种解释。(a)显示了一张真实的脸被拍摄,(b)显示了打印攻击和重放攻击被拍摄。
从(a)看,如果每一帧时面部向右移动,则鼻子中心与耳朵之间的距离就会发生变化。在这种情况下,α>β2应该为真。但是,在(b)中,如果脸部以同样的方式移动,则鼻子和耳朵之间的距离变为α'<β'2。
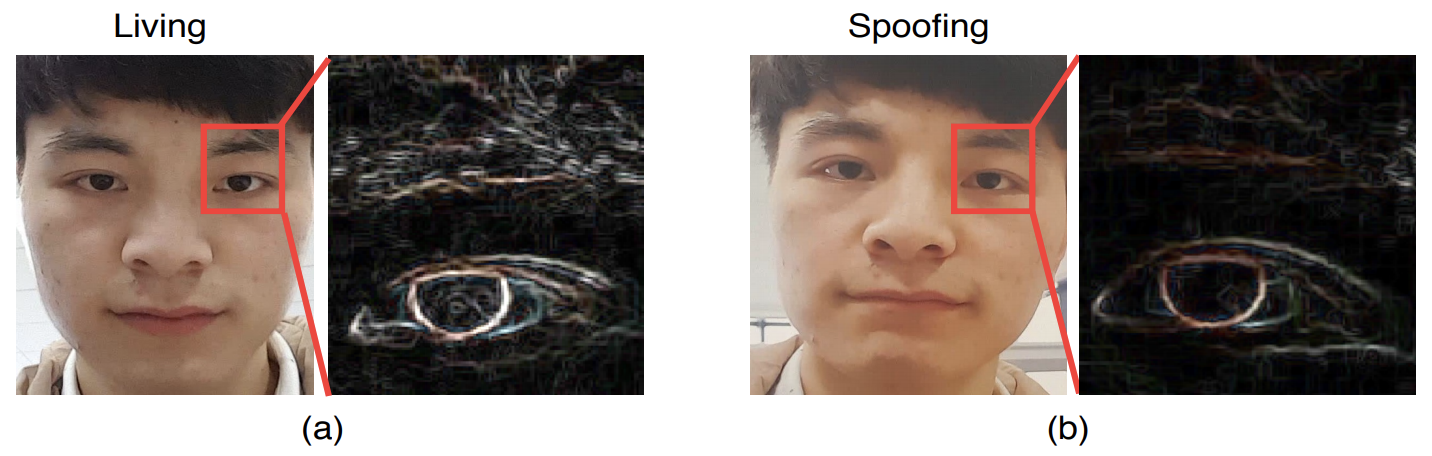
为了获得比以前更详细的空间信息,我们还使用了基于Sobel运算的空间梯度。
这是因为恶搞的空间梯度差异较大,如下图所示。
要阅读更多。
你需要在AI-SCHOLAR注册。
或


与本文相关的类别






