
利用分离表示学习进行人脸欺骗检测
3个要点
✔️ 在人脸反欺骗任务中引入分解表示学习,将潜伏特征分解为Liveness特征和Content特征。
✔️ 通过结合低级纹理信息和高级深度信息来规范化Liveness特征空间。
✔️用具有代表性的基准进行实验,以验证与SOTA相比的有效性。
Face Anti-Spoofing Via Disentangled Representation Learning
written by Ke-Yue Zhang, Taiping Yao, Jian Zhang, Ying Tai, Shouhong Ding, Jilin Li, Feiyue Huang, Haichuan Song, Lizhuang Ma
(Submitted on 19 Aug 2020)
Comments: Accepted by ECCV2020
Subjects: Computer Vision and Pattern Recognition (cs.CV)
勾勒
随着图像识别精度的提高,现在的人脸识别技术的性能比人类更高。如今,它被广泛应用于智能设备、门禁、安防等熟悉的地方。
然而,由于人脸图像的熟悉和容易获得,人们担心冒充他人的风险。冒充他人也被称为演示攻击(PA),目前已经报道了很多方法,比如打印图像、使用电子设备的视频、3D面具、化妆等。为了提供一个安全可靠的人脸识别系统,必须要有一个强大的人脸识别技术来防止欺骗。
由于典型的PA包含视频图像特有的痕迹,基于纹理分析的方法已经被提出。与其他领域一样,有基于手艺的方法和基于CNN的方法,基于手艺的方法有局部二元模式(LBP)/定向网格直方图(HOG)/尺度不变特征变换等。(SIFT)等,通过关注视频中的唇部动作和眨眼等动作来检测欺骗行为。然而,这些方法无法检测电子设备上播放的PA。
近年来,随着深度学习的发展,基于卷积神经网络(CNN)的方法在人脸欺骗检测方面取得了重大进展。在本方法中,利用Softmax将欺骗检测任务作为二进制分类处理。然而,它很难学习到内在的欺骗痕迹,对特定数据集过度拟合,而且大多缺乏泛化性能。
最近,有报道称,一些技术通过使用深度图和rPPG等补充信息来检测欺骗,准确率较高,对欺骗检测很有帮助。然而,这需要预先定义对欺骗有用的特征,而要识别所有这些信息是不现实的。
在人脸欺骗检测中,重要的不是如何精确地预先定义欺骗模式,而是如何从高维特征来表示欺骗模式。
在这里,可能的解决方案之一是Disentangled Representation Learning(DRL)。这种DRL是一种假设高维度信息可以被实质上低维度和有意义的潜伏表征变量所解释的方法。
在人脸欺骗检测中,可以将欺骗的模式看作是人脸的属性之一,而不仅仅是某一种不相关的噪声类型或噪声类型的组合。因此,我们认为,通过直接针对从所有变化的人脸图像中提取Liveness特征,我们可以学习对欺骗检测有用的特征。
基于这一思想,本文提出了一种利用Disentangled Representation Learning进行人脸欺骗检测的方法,将Latent Representation分离出来,如下图所示。我们假设人脸图像的Latent Space可以分解为两个空间,即Liveness Space和Content Space。在这里,Liveness Feature是与Liveness相关的功能,Content Feature是与ID和光线条件相关的功能。
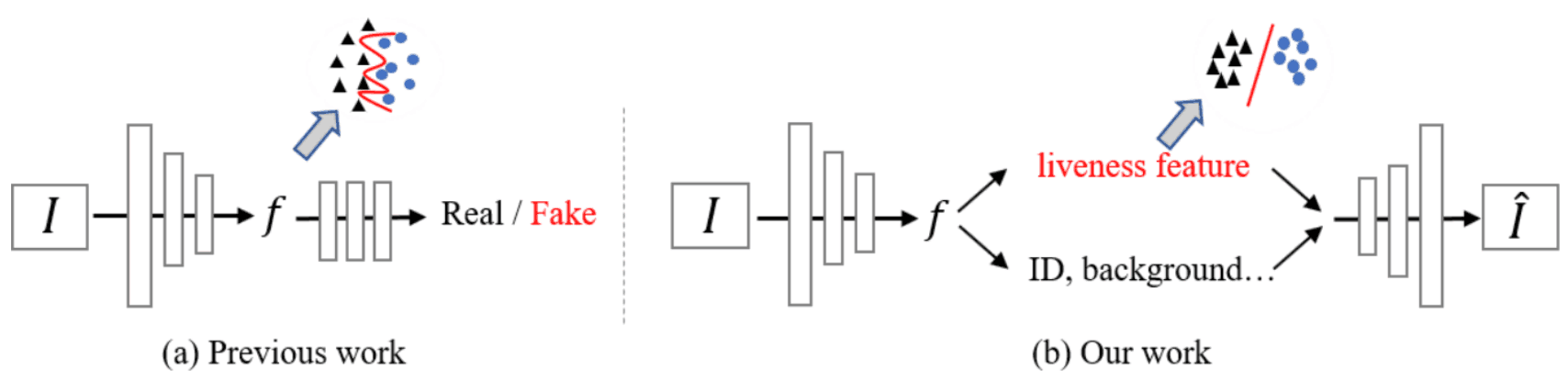
它提取了代表欺骗特征的Liveness特征,利用更多的内在信息进行欺骗检测,不受其他噪声信息的影响,因此可以实现比传统模型更高的泛化性能的模型。
要阅读更多。
你需要在AI-SCHOLAR注册。
或


与本文相关的类别






