无条件的GANs的模型压缩
三个要点
✔️ 无条件GAN的模型压缩技术
✔️ 提出了一个修剪和知识提炼的方法,重点是保留图像中的重要内容。
✔️ 与现有压缩技术和原始模型相比,性能相同或更好
Content-Aware GAN Compression
written by Yuchen Liu, Zhixin Shu, Yijun Li, Zhe Lin, Federico Perazzi, S.Y. Kung
(Submitted on 6 Apr 2021)
Comments: CVPR2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
生成对抗网络(GAN)在图像生成和图像编辑等任务中显示了出色的效果。
然而,最先进的GANs,如StyleGAN2,在计算复杂性和内存成本方面面临挑战,使得它们难以部署在边缘设备上。
然而,这些方法不能直接应用于无条件的GANs,如StyleGAN。为了解决这个问题,本文提出了一种专门针对无条件GANs的模型压缩方法。让我们来看看下面的内容。
建议的方法
所提出的方法的目标是为$G$获得一个容量更小、效率更高的模型$G'$,一个从随机噪声中生成图像的无条件GAN。
更具体地说,我们的目标是实现以下两点
- 对于相同的潜在变量$z/in \mathcal{Z}$,生成的图像$G(z),G'(z)$的视觉质量是相似的
- 对于一个真实世界的图像$I/in \mathcal{I}$,相应的潜在变量$Proj(G,I),Proj(G',I)$是相似的
以下的渠道修剪和知识提炼将帮助我们实现这一目标。
内容感知型模型压缩
在讨论通道修剪和知识蒸馏的细节之前,让我们考虑一个案例,我们想压缩一个生成人脸图像的GAN。在这种情况下,生成的图像中最重要的部分是人脸的区域(其余的背景并不重要)。
因此,在最初的论文中,我们使用一个网络(内容解析神经网络)来识别GAN生成的图像中与重要内容相对应的区域(如人脸)。对于通道修剪,我们使用一个度量标准($CA-l1-out$)来衡量 "每个通道对图像中重要内容的产生有多大贡献"。对于知识提炼,我们使用的损失定义为 "图像中重要内容的生成知识 "的继承。
通过这种 "内容感知 "的模型压缩,我们的目标是获得一个具有与原始GAN相同质量的轻量级模型。
关于内容感知通道修剪
拟议方法的修剪是根据以下管道来衡量一个通道的重要性
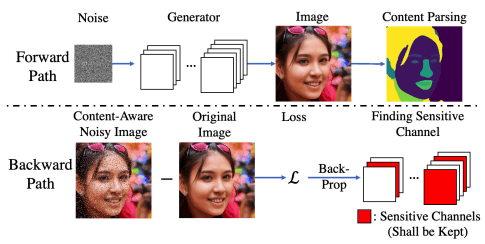
该管道由两条路径组成:前进路径和后退路径。
首先,在前进路径中,潜伏变量$z\in\mathcal{Z}$被用来寻找生成的图像$G(z) \in R^{H×W×3}$。
接下来,生成的图像通过$Net_p$,一个预测图像中内容掩码$m\in R^{H×W}, m_{h,w}\in {0,1}$的网络(内容解析神经网络),以获得内容图$COI={(h,w)|m_{h,w}=1}$。
在人脸图像的生成中,人脸区域与此相对应。
接下来,在后向路径中,我们准备一个仅在COI上有随机噪声的图像$G_N(z)$,这是生成图像$G(z)$的一个重要区域。例如,在人脸图像生成中,噪声只加在生成图像的人脸区域。
然后我们对微分损失$L_{CA}(G(z),G_N(z))$进行反向传播,找到与原始图像的梯度$nabla g\in R^{n_{in}×n_{out}×h×w}$。
通过对几个随机噪声样本$z$进行这样的处理,我们得到梯度的期望值$E[\nabla g]$。然后,每个通道$C_i$的重要性度量$CA-l1-out$被定义为每个通道梯度输出的L1-norm。
$CA-l1-out(C_i)=||E[\nabla g]_i||_1, E[\nabla g]_i\in R^{n_{out}×h×w}$
在修剪过程中,具有较大$CA-l1-out$的通道被保留,具有较小$CA-l1-out$的通道被删除。
关于知识蒸馏
所提出的方法,即知识蒸馏法,采用了几种损失的组合。让我们依次看一下。
像素级的蒸馏
最简单的例子可以是定义为减少生成图像$G(z),G'(z)$的输出层或中间层之间的规范的损失。
对于输出层和中间层来说,这分别用以下公式表示
$L^{norm}_{KD}=E_{z\in \mathcal{Z}}[||G(z),G'(z)||1]$(仅输出)。
$L^{norm}_{KD}=sum^T_{t=1}E_{z\in\mathcal{Z}}[||G_t(z),f_t(G'_t(z))||1]$(中间层)。
其中$G_t(z),G'_t(z)$是中间层(第$t$层)的激活,$f_t$是匹配深度维度的线性变换。
图像水平蒸馏
除了输出图像之间的像素级规范外,还可以使用更接近人类判断的相似度的指标。
所提出的方法通过LPIPS利用了输出图像之间的感知距离。
$L^{per}_{KD}=E_{z\in\mathcal{Z}[LPIPS(G(z),G' (z))]}$
内容感知蒸馏法
与修剪的情况一样,所提出的方法使用了一种蒸馏损失,集中于图像中的重要内容。这在下图中有所说明
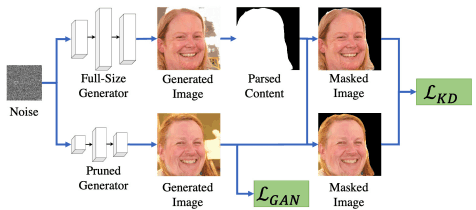
简而言之,它在掩盖了图像中非必要的内容区域(例如在人脸图像生成中的背景区域)之后,计算出上述图像的像素和图像级别的蒸馏损失。
通过使用这种内容意识(关注生成图像的重要内容)蒸馏损失,我们可以继承原始GAN的生成图像的重要内容的更多细节。将这些蒸馏损失与正常的GAN学习损失$L_{GAN}$相结合,最终的学习目标如下
$L=L_{GAN}+lambda L^{norm}_{KD} + γ L^{per}_{KD}$
在训练学生模型时,我们首先通过修剪教师GAN的生成器$G'$得出学生生成器$G'$,而学生判别器$D'$则使用教师判别器的原貌。然后我们通过标准的最小优化对$G'和$D'进行微调。
实验结果
在我们的实验中,我们对在CIFAR-10上训练的SN-GAN和在FFHQ上训练的StyleGAN2进行模型压缩。SN-GAN的输出图像的分辨率为32px,StyleGAN2的输出图像的分辨率为256,1024px square。
评价指标
为了评估所生成图像的性能,我们使用了五个定量指标
- 初始得分(IS):对生成图像的分类质量的衡量。
- Frechet Inception Distance(FID):衡量生成的图像和真实图像之间的相似度。
- 感知路径长度(PPL):衡量GAN潜在空间的平滑度。
- PSNR/LPIPS:通过使用GAN反转将图像转换为潜伏向量,衡量真实图像和从潜伏向量生成的图像之间的相似性。
PSNR和LIPS的最后评估指标如下图所示。

在基于GAN的图像编辑方法中(例如本研究),引入了这样的措施,因为获得与真实图像相对应的潜伏向量并能够从中恢复原始图像是很重要的。
我们还测量了图像中的非重要区域被屏蔽的图像之间的相似性(上图中的CAxPSNR/CA-LPIPS),因为这些图像编辑方法,例如,关注的是保留图像的重要内容。
关于建议的方法(通道修剪
首先,拟议方法的修剪结果及其与各种基线的比较如下
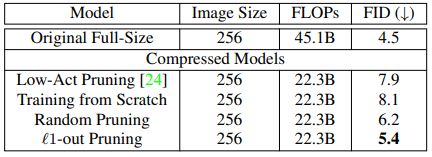
Low-Act修剪是一种现有的修剪方法,在GANs的模型压缩方面几乎失败,表现比随机修剪差,几乎与从头开始训练的模型一样好。
另一方面,拟议的修剪方法仅导致FID得分减少0.9,而将FLOPs保持在原来的一半左右。
关于拟议中的方法(知识蒸馏法
对于上述知识提炼中的学习目标$L=L_{GAN}+L^{norm}_{KD}+L^{per}_{KD}$,不同设置的超参数如$\lambda,\gamma$的实验结果如下(训练后的模型有80%的原始模型的通道被提议的修剪方法所删除)。)
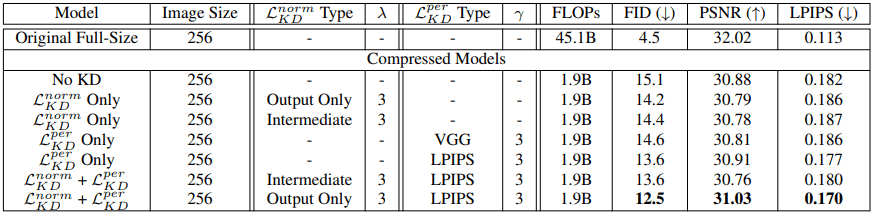
一般来说,当用$L^{norm}_{KD}$进行训练时,只需输出,而用$L^{per}_{KD}$进行训练时,获得了最好的结果。
与最先进的GAN压缩方法的比较
此外,我们还进行了实验,将提出的方法与最先进的GAN压缩方法GAN Slimming(GS)进行比较。结果如下
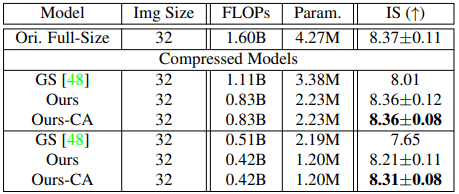
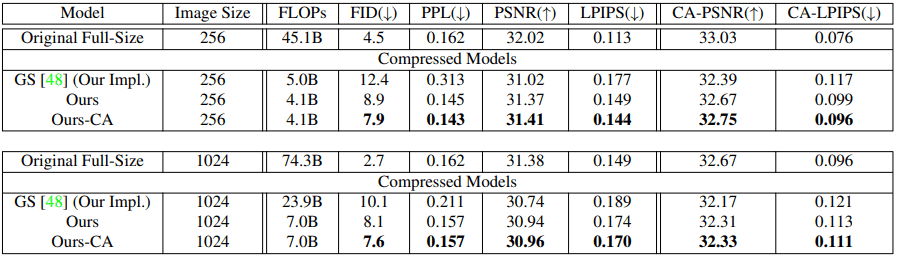
总的来说,对于CIFAR-10/FFHQ,所提出的方法(特别是在内容感知设置中)显示出更好的结果。
关于图像编辑
测试所提出的方法压缩的模型是否能用于风格融合、变形和GANS空间编辑任务的结果如下。

在这个图中,显示了风格融合和变形的结果,总的来说,我们成功地产生了质量良好的图像,几乎没有人工痕迹。
下面是用GANSpace进行图像编辑的例子。

在这个图中,考察了GANSpace中$u_0$方向的图像编辑(可以改变性别),在所提出的方法压缩的模型中,原始图像($sigma=0$)的性别成功地改变为男性或女性方向。这表明所提出的压缩模型在图像编辑中的有效性。
消融实验
将进行一项消融研究,以验证所提出的修剪和知识提炼方法的有效性。
首先,建议的方法在没有微调的情况下修剪的结果如下。

可以看出,所提出的方法,即$CA-l1-out$,与其他方法相比,保留了输出图像,并能正确地分辨出信息丰富的通道。
此外,下面是一个例子,说明知识蒸馏中的 "内容意识 "设置所产生的结果变化。

与没有 "内容感知 "设置的AS-KD相比,所提出的方法(CA-KD)被发现能更恰当地保留图像中的重要内容。
摘要
与现有的无条件GAN模型的压缩方法相比,所提出的方法在生成图像的质量和潜空间的平滑度方面显示出优越的效果,并且也可以应用于图像编辑和其他应用。
这些优秀的压缩技术非常重要,例如,对于在边缘设备上使用最先进的模型,我们期待着在这个领域的进一步发展。



与本文相关的类别






