现在只需一个注释就能实现语义部分的分割
三个要点
✔️ 只需对1-10张图片进行人工标注,就可以进行语义部分的分割。
✔️ 使用GAN的内部表示
✔️ 尽管教师数据较少,但性能不亚于10-50倍的数据。
Repurposing GANs for One-shot Semantic Part Segmentation
written by Nontawat Tritrong, Pitchaporn Rewatbowornwong, Supasorn Suwajanakorn
(Submitted on 7 Mar 2021 (v1), last revised 5 Jul 2021 (this version, v5))
Comments: CVPR 2021 (Oral)
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
以前的一些研究试图通过使GANs的内部信息更易解释来分析GANs;一些研究试图通过允许用户玩弄GANs的潜在代码来控制生成的图像;一些研究试图通过使GANs的内部信息更易解释来分析GANs。在本文中,我们假设GAN的内部表示与生成的图像密切相关,并能持有语义信息。
我们在本文中处理的语义部分分割与语义分割不同,后者的目的是分割图像中的物体。这使得语义部分的分割成为一项更困难的任务,因为两个部分之间可能没有可见的边界,如眼睛、鼻子或脸。这种技术需要大量的像素级注释,尽管现有的方法已经取得了相当大的进展,但它们并不控制物体各部分的分割,导致任意分割。在本文中,我们能够通过简单地准备少量的注释图像来控制这些任务。
元学习中也解决了少许语义分割的问题,但它需要类似对象类别的注释掩码,这使得特定部分的学习无法进行。相比之下,从GANs中提取的表征可以在没有监督的情况下进行训练,因为它们包含了部分级别的信息。
方法
在本文中,我们设定了我们将引入的条件。首先,给定一个未标记的图像和一些带有部分注释的图像(1-10),我们的目标是对未标记的图像进行部分分割。还假设这几个部分注释的图像可以由用户手动设置。这项任务可以通过提供一个独特的部分分割函数$f$来完成,该函数可用于分割仅从部分注释的图像中没有意义的信息。作者使用一个经过训练产生目标物体图像的GAN来推导这个函数。本文现在将展示如何将GANs用于这项任务,如何将训练好的GANs用于分割,以及允许在推理过程中不需要GANs或高级映射的分割的扩展。
首先,我们将展示如何从GAN中提取表示。使用GANs作为映射函数并不是一个简单的问题,因为GANs通过向生成器输入随机的潜伏代码,而不是要映射的图像像素来生成图像。因此,考虑这样一种情况:潜伏代码被送入基于卷积的GAN(DCGAN)以生成一幅图像。每个输出像素可以被看作是计算的结果,可以通过每个卷积层追溯到第一个输入潜伏代码。产生像素的计算发色通常是一个定向无环图(DAG),其中每个节点代表一个参与计算像素的参数和输入的潜伏代码。然而,在本文提出的方法中,每个节点代表一个激活值,路径只是由该像素对应的发生器中所有层的激活序列来表示。
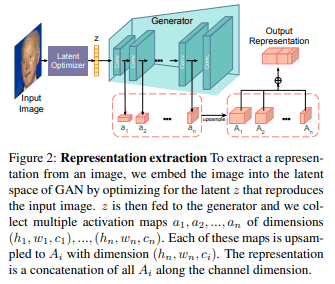
如图2所示,我们从生成器的所有层中提取激活图(每个都有$h_i,w_i,c_i$维度),并将其表示为$a_1,a_2,。.a_n$。然后,我们学习像素级的表示,如下所示。
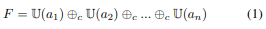
这里,$U()$对输入的最大激活图$(h_n,w_n)$进行上采样,并沿通道维度串联$⊕c$。通常情况下,这种特征图提取过程只对生成器生成的图像有效,不能直接用于测试图像。然而,给定一个任意的测试图像,可以通过优化生成给定图像的潜伏代码,以类似方式生成特征图。
为了实现Few-shot中的分割,我们从训练好的GAN中生成$k$的随机图像。然后,我们为这些$k$图像创建特征图,并对其进行人工注释。这些$k$特征图和注释被成对使用作为监督数据来训练分割模型(图3)。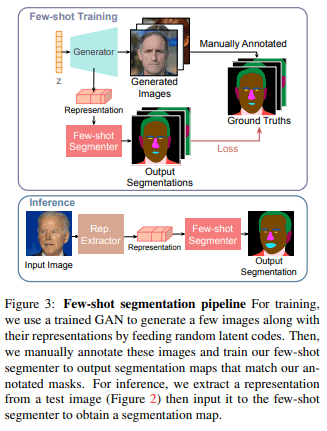
对于测试图像的分割,上述的潜伏代码优化被用来计算一个像素级的特征图,然后将其输入训练好的分割网络。
在仅使用GAN执行这项任务时,需要注意的一个重要问题是,测试图像必须接近GAN使用的图像分布。否则,潜伏的代码将不会得到很好的优化。如果对象是人脸,那么测试图像必须与用于训练GAN的图像有类似的分布,并且必须只包含一张脸。优化潜伏代码的过程也是计算昂贵且耗时的,因为它需要一些前向和后向传播的操作。
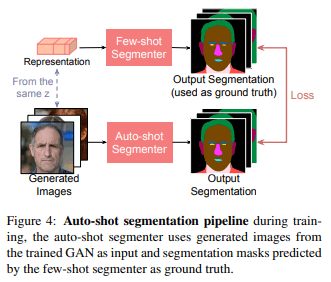
为了解决上述问题,在本文中,我们用训练好的GAN和提出的方法的网络来创建一对新的训练数据,并训练另一个网络,如Unet。这使我们能够通过一个单一的模型来进行分割,而不依赖于GANs或特征图。这个过程在本文中被称为自动照片分割。 图4显示了自动照片分割的流程。
最后,我们将再次总结拟议方法的流程。
- 在感兴趣的对象的数据集上训练一个GAN
- 使用训练有素的GAN生成图像的逐个像素表示法
- 手动注释由2生成的图像
- 以表征信息为输入,进行少许镜头分割
- 在4中,创建了一个新的数据集并预测了一个新的分割图。
实验
实验设置
在我们的论文中,我们使用StyleGAN2作为训练的GAN。少许网络是一个卷积网络(CNN)和一个多层感知器(MLP)。CNN和MLP都使用亚当作为优化器,交叉熵作为损失函数。对于自动拍摄的分割网络,我们使用前面提到的UNet,它是用GAN生成的图像和少数拍摄网络分割的图像对作为训练数据进行训练的。在这个过程中,对数据集进行了以下数据增强。
- 随机反转
- 0.5~2倍的随机缩放
- -10~10度随机旋转
- 随机移动0%~50%的图像尺寸
本文所使用的数据集和指标列举如下。
- 数据集
- 一张人脸 (CelebAMask-HQ)
- 汽车 (PASCAL-部分)
- 马 (PASCAL-部分)
- 评价指标
- 相互交叉的工会(IOU
- 属于该类的像素数占总像素数的比率
实验
人脸部分的分割
在人脸部位分割实验中,我们比较了Few-Shot分割的架构(CNN或MLP)、部位类别的数量(3或10)以及人工注释的数量(1、5或10)。
首先,比较一下CNN和MLPs:与CNN不同,MLPs预计不如CNN准确,因为它们独立推断每个像素,但表1显示MLPs有MLP几乎和CNN一样好然而,表1显示,MLP具有
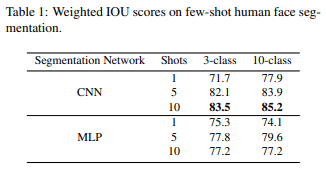
表2显示了10张照片分割法和在此基础上训练的自动照片分割法之间的比较。自动照片分割法对除衣服以外的所有类别产生的IOU分数与10张照片分割法相似,尽管它只依赖10张照片分割法产生的数据集。尽管自动分割只依赖于10次分割产生的数据集,但它在除衣服以外的所有类别中仍然取得了与10次分割相似的IOU分数。衣服得分较低的原因可能是,该模型无法应对大量不同类型的衣服(颜色和形状)。

图5和Tab3显示了采用CNN进行的几张照片分割所生成的图像和欠条。可以看出,在这两种情况下,10-shot的性能最好。

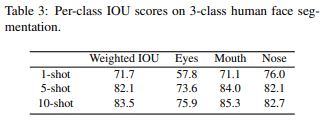
图6比较了监督学习的结果,其架构与提议的方法相同,但使用CelebAMask-HQ作为数据集和不同数量的标签,以及提议的方法的结果,少数照片分割。该图显示,需要100多个注释才能超过1张照片的分割,需要大约500个注释才能达到与10张照片分割相同的性能水平。
汽车零部件细分市场
由于姿势和外观的广泛变化,汽车的部分分割预计将是一个比人脸图像更困难的任务。然而,如图7所示,所提出的方法能够识别单次拍摄图像中的轮胎、窗户和车牌。

表4比较了由提议的10次拍摄方法与DeepCNN-DenseCRF和Ordinal Multitask Part Segmentation训练的自动拍摄。其性能优于基线,即完全监督学习。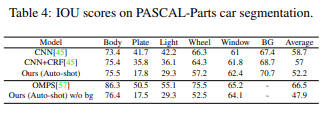
马匹部分的划分
预计对马匹的细分将是一项比前两项更困难的任务。这可能是由于马匹处于各种姿势,如站立或跳跃,腿和身体之间的界限并不明确。正如预期的那样,所提出的单次拍摄方法的性能不如人脸和汽车,但如图8所示,通过增加注释的数量可以取得明显的改善。

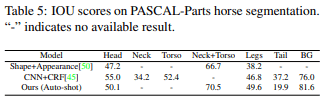
表5比较了用Shape+Appearance和CNN+CRF对10张照片进行的自动拍摄训练。 表6显示了RefineNet和Pose-Guided Knowledge的结果。表6显示了RefineNet和Pose-Guided Knowledge Transfer的结果。表6显示了RefineNet和Pose-Guided Knowledge Transfer的结果。 所提出的方法优于RefineNet,但在300个镜头的完全监督学习中略低于Pose-Guided Knowledge Transfer。

摘要
在本文中,我们提出了一种方法,将用于图像生成的GANs用于少数照片的语义部分分割。其新颖之处在于使用了GAN生成过程中的每像素表示信息。所提出的方法可以用非常少的注释来实现部分分割,并取得了与需要10-50倍标签的完全监督方法相媲美的性能。此外,通过从Few-Shot方法生成的分割图像中创建一个新的数据集,我们能够处理不同尺寸和方向的图像。本文认为,无监督的表征学习,即GAN,可以成为未来对物体部分进行语义和逐像素预测的有效和通用的提炼任务。



与本文相关的类别






