Pun-GAN,产生双关语的人工智能!
三个要点
✔️使用GAN生成双关语句的任务
✔️不需要双关语的句子语料库
✔️包括一个双关语句生成器和一个词义辨别器
Pun-GAN: Generative Adversarial Network for Pun Generation
written by Fuli Luo, Shunyao Li, Pengcheng Yang, Lei li, Baobao Chang, Zhifang Sui, Xu Sun
(Submitted on 24 Oct 2019)
Comments: Accepted by IJCNLP 2019
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文件,要么是参照论文件制作的。
简介
生成有创意和更有趣的文本是构建智能自然语言生成系统的重要步骤。在这里,双关语是指巧妙而有趣地使用一个具有两种含义的词,或者一个具有相同声音但不同含义的词。在本文中,我们将重点讨论前一种类型的双关语。一个双关语的例子是 "我曾经是一个银行家,但我失去了兴趣"。对 "兴趣 "的双关语可以解释为好奇心和兴趣。
双关语生成的问题之一是缺乏大量的双关语语料库,在这些语料库中,双关语的句子被贴上了两个词义。早期的工作是基于规则,使用模板,缺乏创造性和灵活性。后来的工作将神经网络用于这项任务,确保作为输入的词义被包括在生成的句子序列中。然而,该方法无法检测出两个词义是否被支持。双关语句的检测可以通过词义辨析(WSD)来帮助,其目的是通过多类分类器来识别句子中某个词的正确词义。基于上述动机,所提出的方法使用生成对抗网(GAN),这是一种使用具有特定含义的两个词作为GAN生成器的输入来生成双关语句的模型。鉴别器是一个模型,用于识别一个给定的句子是否是一个真实的句子。
本论文还讨论了对双关语生成的评价。在本论文中,进行了自动评价和人工评价。结果表明,所提出的方法,即Pun-GAN,在模糊性和多样性方面产生了更高质量的双关语。
方法
GAN的结构如图1所示。GAN由一个双关语生成器$𝐺_𝜃$和一个词义辨析器$𝐷_𝜙$组成。
发电机
生成器$𝐺_𝜃$输出的句子$𝑥不仅包含句子中的$𝑤$,而且当目标词𝑠的两个含义$(𝑠_1,𝑠_2)$被作为输入时,还表达了相应的两个含义。Yu等人(2018)的神经约束语言模型被用作发生器的模型。它与传统的神经语言模型不同的是,它的设置方式是,在每个时间步骤产生的词应该具有分别以$𝑠_1$和$𝑠_2$作为输入计算的两个概率的最大和。产生第t$个词汇的概率由以下公式给出
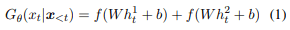
这里$h_t^1(h_t^2)$是第t$步的隐藏状态,当$s_1(s_2)$为输入时,$f()$是softmax函数。x_{<t}$是前面的$t-1$词。那么,产生整个句子$bf{x}$的概率就可以表述为:。
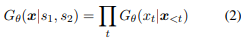
鉴别器
鉴别器将类别划分为$𝑘+1$类别,即$𝑘$的感官数量加上 "生成 "类别(="假 "类别)。判别器是Kageback和Salomonsson的WSD(2016)的扩展。判别器的计算方法如下。

其中$c$是来自双向LSTM的上下文向量,以$x$为输入,$U_w$是特定词的参数,而$y$是目标标签。
损失函数
鉴别器的训练目标是最小化以下内容
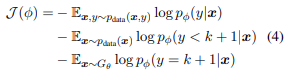
这里,$p_{data}$指的是只有一种含义的句子。为了鼓励产生双关语的句子,鉴别器应该给那些可以同时被解释为两种含义的模糊双关语的句子以更高的奖励。在双关语的情况下,$𝐷_𝜙(𝑐_1|𝑥)和$𝐷_𝜙(𝑐_2|𝑥)的概率应该很接近,这两个概率应该被训练来说明很多。例如,当它是(0.1,0.5,0.4)时,我们应该让它更有可能是一个双关语。另一方面,如果这个句子看起来像(0.1,0.8,0.1),那么它就是一个具有(0.8)含义的一般句子。为了实现这一目标,我们将奖励设计如下。
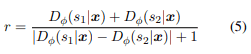
分母中的1是一个数字,以确保分母不为零。
训练发生器时,最小化负的预期报酬是目标(公式6)。
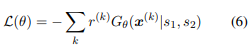
方程6的梯度可以近似为:。
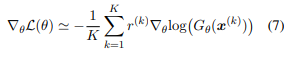
实验
实验设置
- 学习数据
- 用英语维基百科语料库中标有词义的词对生成器进行预训练
- 以下三条是判别标准
- SemCor,用于WSD的人工注释语料库(公式4中的第一项)。
- 维基百科语料库(第2节
- 生成的双关语(第3节
- 评价数据
- 评价数据
- SemEval2017任务的双关语数据集7(人类制造的双关语)。
- 设置
- 随机初始化维度为300的单词嵌入
- 样本量K:32,学习率:0.001,优化器:SGD
- 对生成器进行5个历时的预训练,对鉴别器进行4个历时的预训练。
- 在对抗性学习中,生成器每隔1个历时训练一次,判别器每隔5个历时训练一次。
- 基线模型
- LM:正常RNN
- CLM:一个语言模型,确保一个给定的词出现在生成的文本中。
- CLM+JD:一个最先进的生成双关语句的模型,扩展了CLM
- 评级
- 自动评估:不寻常性的评估方法是将用于训练的句子的对数概率减去生成的双关语句子的对数概率,多样性的评估方法是单关语与大关语的比率。
- 人工评估:一个人根据三个标准对100个随机抽样的产出进行1-5级的评估
- 歧义:该句是双关语吗?
- 流畅性:你的写作有多流畅?
- 总体:总体评价
实验结果
实验结果见表1(自动评价)和表2(人类评价),Pun-GAN比CLM+JD更有创意,更令人惊讶,可以生成更多不同的句子。然而,结果也表明,Pun-GAN生成的句子与人类写的双关语之间仍有很大差距。
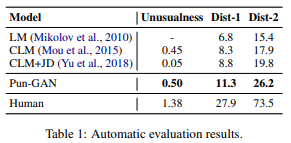
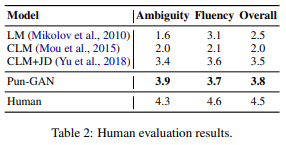
图2显示了由Pun-GAN生成的一个句子的例子。

最后,Pun-GAN的错误类型如图3所示:Pun-GAN生成的句子的错误类型是只支持一个词义的句子(即不是双关语的句子),非通用的句子,以及语法不正确的句子。

摘要
在这篇文章中,我们提交了一篇论文,提出了Pun-GAN,一个用于生成双关语的对抗性生成网络,它由一个双关语生成器和一个词义鉴别器组成。Pun-GAN不需要一个双关语料库。作者说,Pun-GAN是通用和灵活的,将来可以扩展到其他受限文本生成任务。



与本文相关的类别






