基于压缩视频的系统实现实时面部表情识别!
三个要点
✔️ 作者提出了一种直接从压缩视频中识别面部表情的方法。
✔️ 压缩后的视频包含面部表情肌肉运动以差分数据的形式嵌入,利用面部表情的内在特征,实现了稳健的模型建立。
✔️ 利用差分数据,降低计算成本,加快处理速度。
Identity-aware Facial Expression Recognition in Compressed Video
written by Xiaofeng Liu, Linghao Jin, Xu Han, Jun Lu, Jane You, Lingsheng Kong
(Submitted on 1 Jan 2021 (v1), last revised 7 Jan 2021 (this version, v2))
Comments: Accepted at ICPR 2020
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Multimedia (cs.MM)


介绍
通过互联网发送和接收Netflix、YouTube和TikTok等视频数据已经变得很普遍,随着5G的普及,这种趋势预计会更加强烈。
由于这种视频数据的数据量较大,一般都是以压缩格式处理。在可以恢复的范围内消除无用的数据,只将数据减少到必要的最低限度,就可以有效地处理视频。这对面部表情识别也有很大影响,这也是本文的主题。
面部表情识别的应用场景包括:从拍摄的视频中自动提取重点场景,搜索营销资料,提高工作效率。在医疗领域观察病人,以及;或根据人类情绪改变行为的机器人。各类这只是几个例子。这些都需要处理大量的视频数据。尤其是根据人类情绪改变动作的机器人,需要实时反应,所以需要尽可能高效地处理数据。
以前的大多数方法都是处理解码压缩视频序列的RGB图像,但本文介绍的IFERCV是直接从压缩视频数据中识别面部表情。因此,它的处理速度是传统方法的三倍,而精度却达到了同样的水平。
IFERCV,一个使用压缩数据的面部表情识别模型
如前所述。对于视频的面部表情识别,传统的方法是将图像一次解码成RGB图像,如下图所示(黄色)。另一方面,IFERCV如下图所示(绿色)。另一方面,IFERCV可以在不对压缩视频进行解码的情况下识别面部表情。因此,与传统方法相比,IFERCV省去了解码过程,用压缩数据进行面部表情识别,数据量更少,大大提高了处理速度。
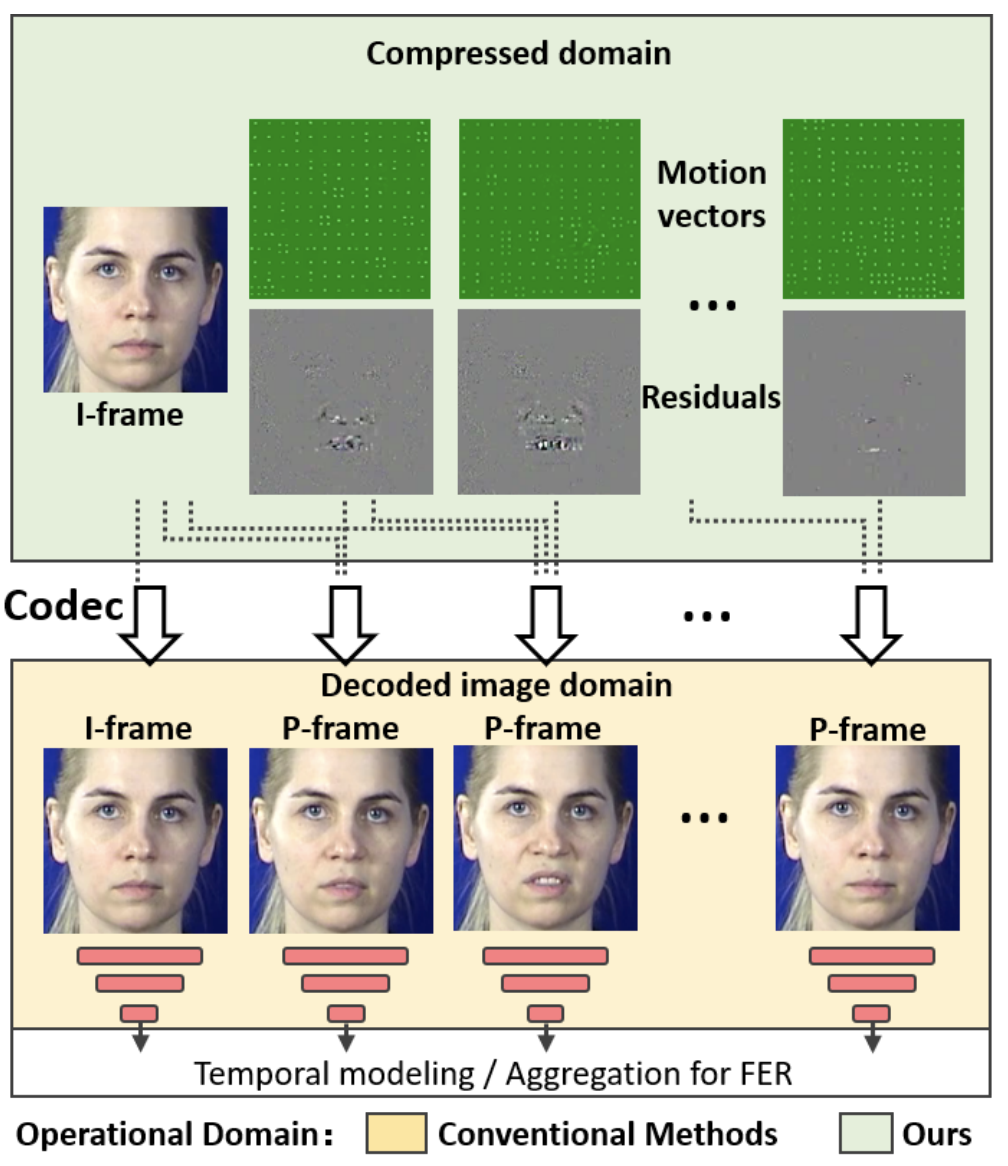
一个视频一般由I帧和P帧组成。I帧(Intra-coded Frame),又称关键帧,是指帧与帧之间不做预测的关键帧。还有:P-frame(Predicted Frame)是指考虑到图像与前一帧图像在时间上的差异(Residuals)的帧。此时,运动矢量(Motion Vectors),也就是帧中物体运动的修正信息,也被嵌入其中。
在压缩视频中,原始帧信息不被保留,但参考I帧和。差异(余数)和和运动向量(Motion Vectors)。和运动矢量。在本文中,我们重点介绍了这差额(余数)在本文中,直接从这些差异中识别面部表情(Residuals)。大纲如下图
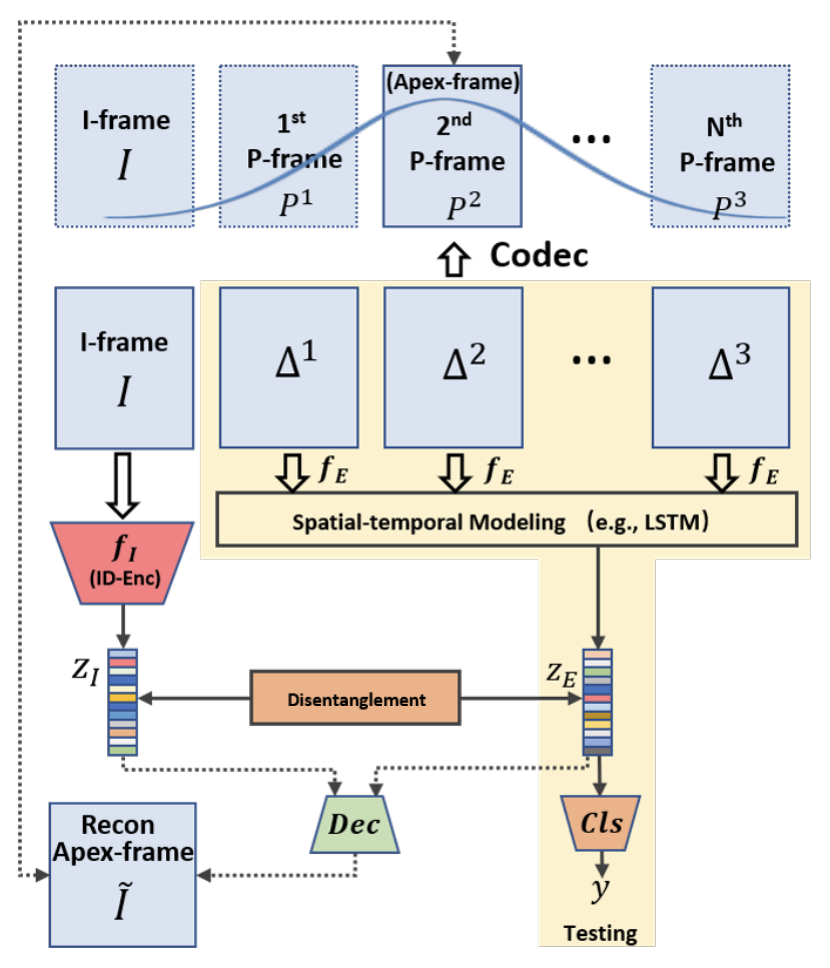
I型架和P型架分别为I和P分别是差值和运动矢量。ΔT和T表示的是P和I代表自I表示自该帧以来所经过的时间。在本方法中,为了便于学习面部表情的变化,我们选择一帧参考真面孔作为I帧,用学习到的FaceNet(fI)用于提取真实人脸的特征(ZI)是利用学习的FaceNet( )提取出来的。
接下来,为了提取与面部表情变化相关的特征。Δt我们使用一个典型的CNN-LSTM用于一系列Δt对于美国有线电视新闻网(fE),然后应用由LSTM提供fE通过LSTM,再将从fE中提取的特征聚合成一个,最后将面部表情变化的特征集。ZE是提取。由于差异数据Δ的信息量比典型帧小得多,我们可以使用比传统面部表情识别中使用的CNN更简单、更快速。因此,计算负荷变得更小。
此外,我们还利用Disentanglment Learning提取更多必要的面部特征信息,并将ZI和ZE清晰地分为"真实的脸"和"有表情的脸"两类,建立健壮的模型。具体来说,我们从ZI和ZE中解码出对应于Apex帧的I帧,这两个帧是表情变化最明显的帧。我们把ZI和ZE分成两类:"真实的脸"和"有表情的脸"。由于大多数面部表情识别的数据集(CK+、MMI等)都是为了显示从真实面孔到表现面孔的变化,所以我们可以在真实面孔和表情变化最大的面孔(Apex-frame)之间选择。
实验结果
在这里,我们使用CK+和AFEW两个数据集来比较SOTA的模型和性能。CK+(Extended Cohn-Kanade)是一个广泛使用的面部表情识别任务的基准。被摄者面对镜头拍摄,背景为空白。换句话说,它是一个在某种准备环境下拍摄的视频数据集。每个视频由593个图像序列组成,从无表情到有表情,最后一帧是表情变化最大的画面。面部表情有六种标签:愤怒、厌恶、恐惧、快乐、悲伤、惊讶。科目数量为123个。
AFEW(Acted Facial Expressions in the Wild)由影片中的视频片段组成。因此,与CK+不同的是,它是在没有任何拍摄条件的情况下,在更真实的环境下拍摄的视频数据集。和CK+一样,面部表情有六个标签:愤怒、厌恶、恐惧、快乐、悲伤、惊讶。 题目不明,但视频数量为1809个。
CK+的实验结果
首先,通过CK+与传统模型的性能对比结果如下表所示。为了公平地比较每个模型,这里不包括基于图像的模型和集合模型。
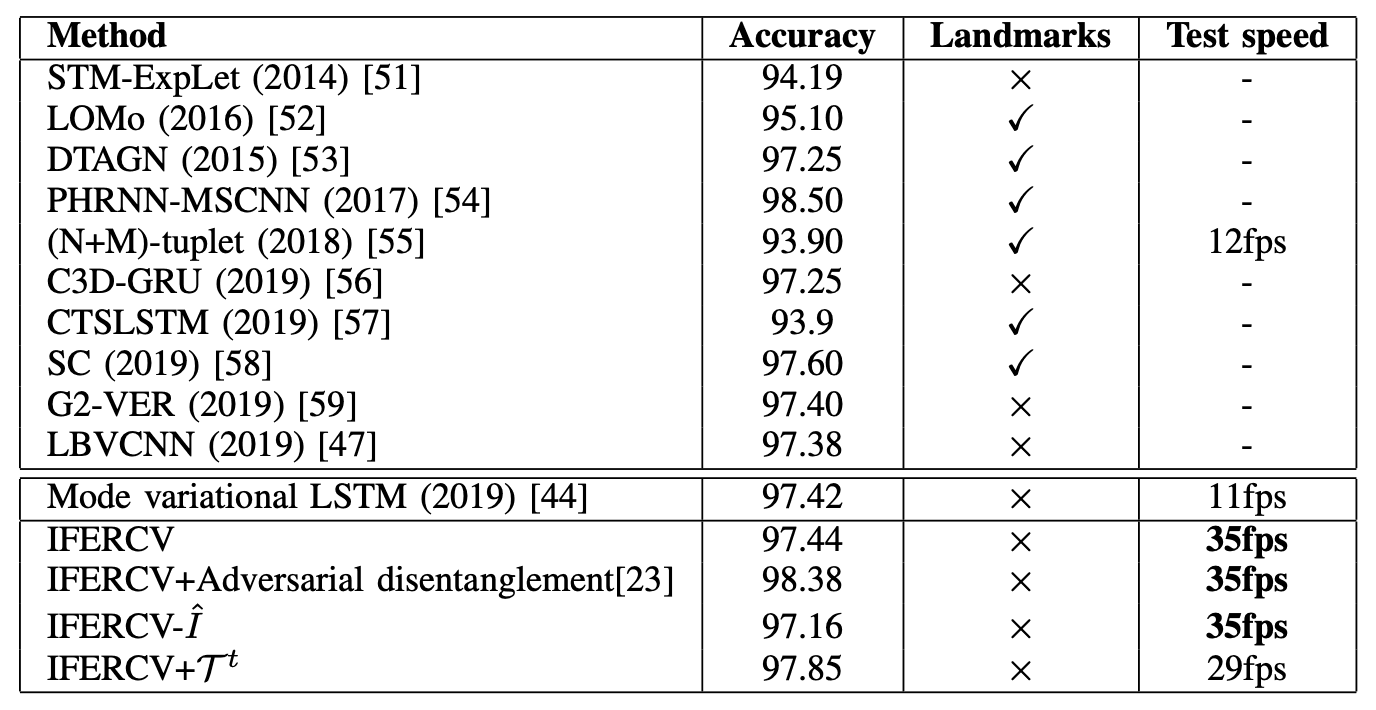
许多已经取得高性能的模型(如LOMo、DTAGN、PHRNN-MSCNN、CTSLSTM、SC)使用了人脸地标信息。它们主要依靠高度精确的人脸地标检测模型。这张脸Landmark本身就是一项艰巨的任务,计算成本很高。
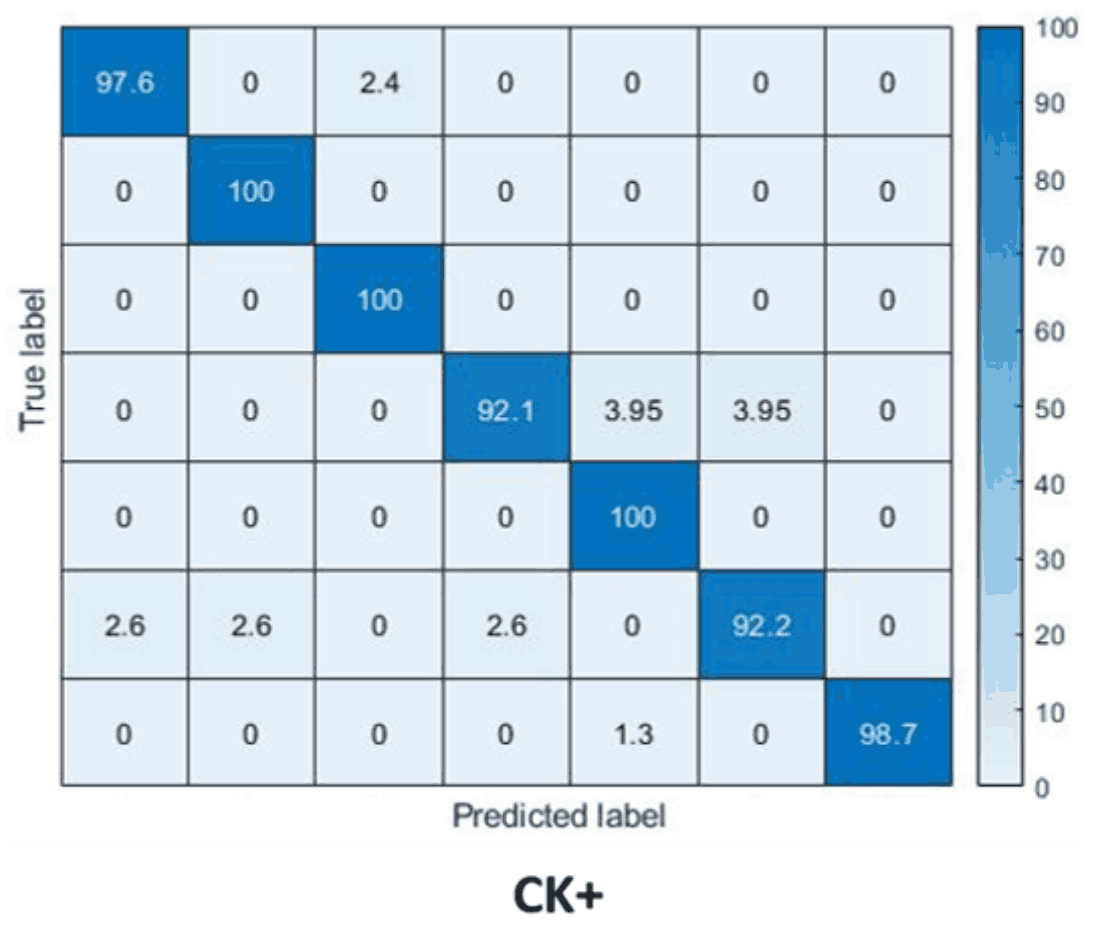
另一方面,他们提出的IFERCV是基于Mode variational LSTM,在不使用人脸地标、3D人脸模型和光学流等补充信息的情况下,实现了SOTA精度。还有:IFERCV是一个基于压缩的过程,可以做到以下几点基于压缩的IFERCV不需要对视频进行解码,所以它的速度是基础Mode变分LSTM的3倍左右,并且实现了更高的精度。混乱矩阵是这样的每一行、每一列从上/左起分别代表愤怒、厌恶、恐惧、快乐、中立、悲伤、惊讶,可以看出,在所有情况下都能达到很高的准确率。
AFEW的实验结果
接下来,AFEW与传统模型的性能对比结果如下表所示。同样,为了公平地比较每个模型,不包括集合模型。该表是从纸上但型号和精度的项目名称似乎是相反的。
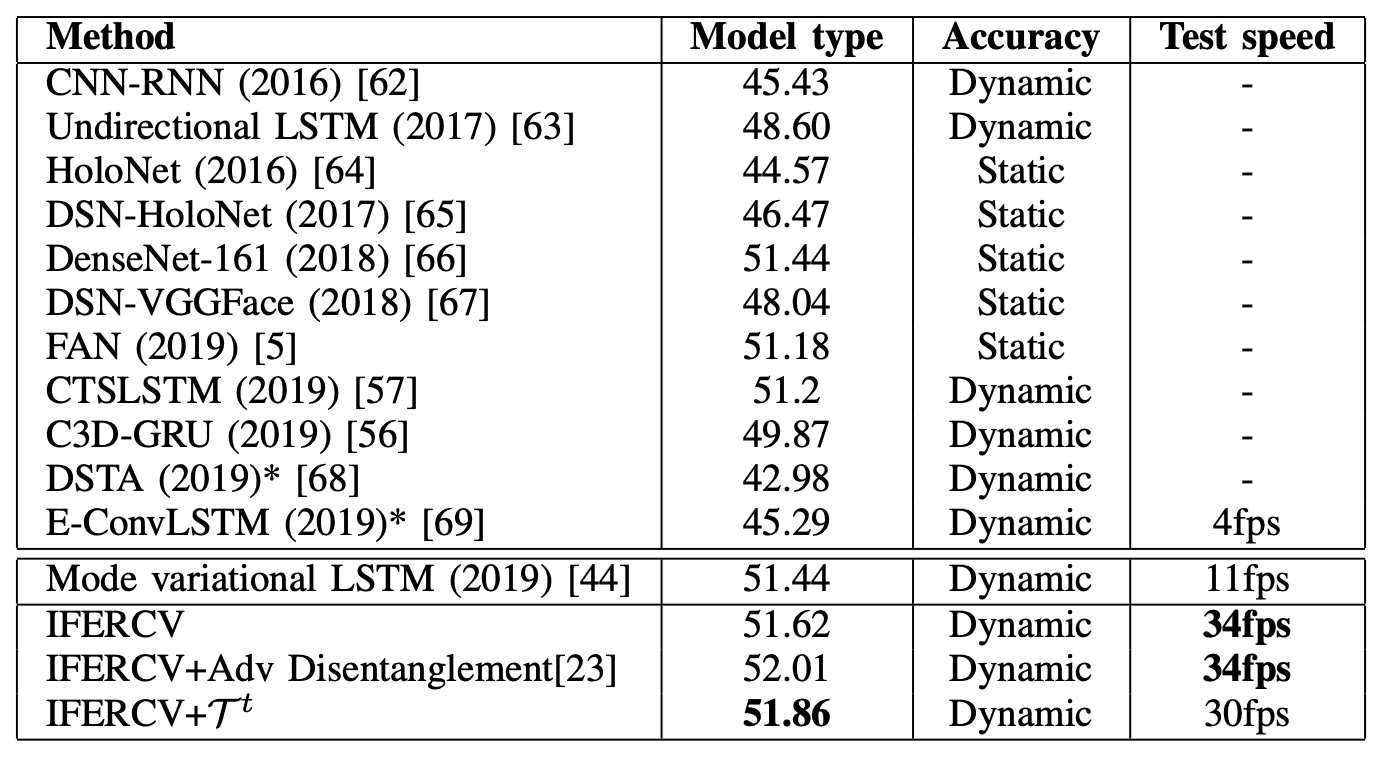
AFEW的拍摄效果不如CK+,所以整体准确率较低。另外,这里没有使用音频数据。IFERCV在压缩的基础上实现了与SOTA方法相当或更好的识别性能。与这里使用的Mode variation LSTM相比,它的处理速度也快了3倍。虽然识别精度不够,但基于压缩的处理方式表明,即使在真实的拍摄环境中,也有可能以接近实时的速度识别面部表情。
传统模型需要对视频进行解码,还需要复杂的数据处理,如使用互补信息。另一方面,拟议的IFERCV可以消除这些过程。也看到,它显著提高了测试速度,并达到了与之前模型相同的精度。在这项工作中,他们只关注了图像压缩的验证,但有可能通过尝试使用音频数据的多模态来进一步提高准确性。
摘要
本文提出了一种直接从压缩视频数据中进行面部表情识别的方法。它是基于面部肌肉的运动在压缩图像数据中被很好地编码为差分数据,提供了面部表情的基本特征,可以建立一个健壮的模型。通过利用差异数据,还可以期望消除背景等冗余数据,因为背景在视频中几乎没有变化,学习的计算成本更低。
在IFERCV中,还将Disentanglment应用于从I帧和差异数据中提取的特征,将人脸识别信息与表情信息分离,提取出必要的表情信息。通过应用这些方法,将IFERCV与典型的基于视频的FER基准进行比较,在不应用任何补充信息的情况下实现SOTA的准确性。此外此外,处理速度也有明显提高,显示出实时FER的可喜成果。



与本文相关的类别


![Swin 变形金刚] 基于变形金刚的图像](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



