高分辨率图像的超级加速翻译: ASAP-Net
三个要点
✔️与现有方法相比,图像翻译任务的速度显著提高
✔️减少高分辨率到低分辨率下的操作
✔️尽管速度加快,但生成的图像质量与现有方法相当。
Spatially-Adaptive Pixelwise Networks for Fast Image Translation
Written by Tamar Rott Shaham, MichaelGharbi, Richard Zhang, Eli Shechtman, Tomer Michaeli
(Submitted on 5 Dec 2020)
Comments: 1Accepted to arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:.
首先
近年来,将图像从一个领域转换到另一个领域的任务得到了广泛的研究。目前的方法是使用条件GANs来学习从一个领域到另一个领域的直接映射。虽然这些方法在视觉生成的图像质量方面取得了快速的进展,但它们也大大增加了模型的大小和计算的复杂性。当试图将其用于现实世界的应用时,这种巨大的计算复杂性是一个非常严重的问题。
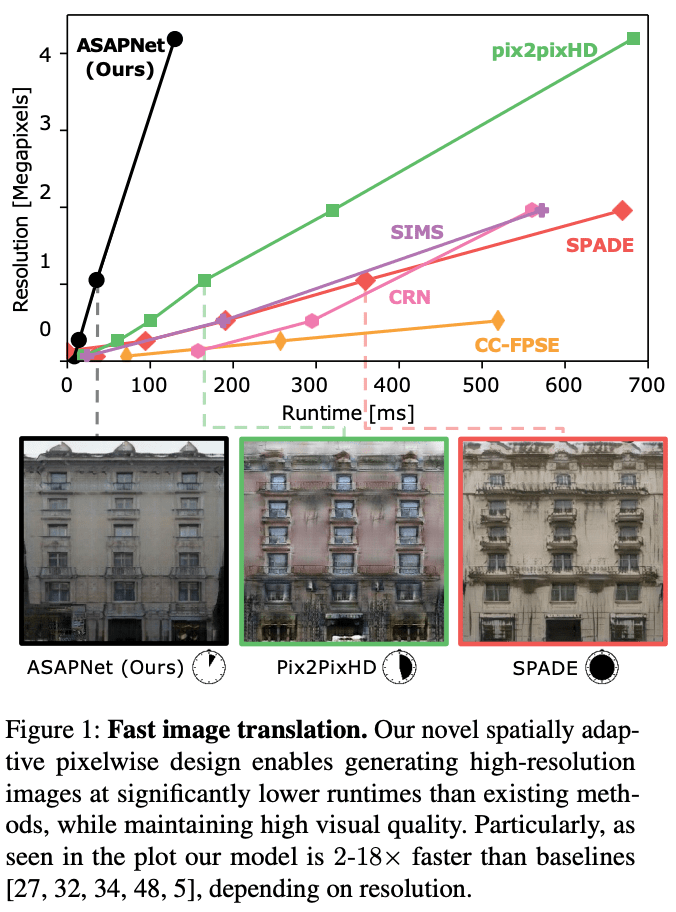
在本文中,我们开发了一个新的架构来加快图像风格转换的任务,名为ASAP-Net(A Spartially-Adaptive Pixcelwise Network)。(图1)。
技术
如前所述,任务是训练NN,使其在两个图像区域之间进行映射。也就是说,给定一个输入图像$x\in R^{H\times W\times 3}$,生成的图像$y\in R^{H\times W\times 3}$必须看起来像属于目标域。本文的目标是建立一个比现有方法更有效的网络,但仍然产生与现有方法相同质量的输出。
分析和理解图像的内容是一项复杂的任务,需要相应的深度NN,但我们在本文中认为,这种分析不需要在全分辨率下进行。首先,我们使用轻量级、可并行化的运算符来合成高分辨率的像素。然后,我们在一个非常粗略的分辨率下进行成本更高的图像分析。这种设计最大限度地减少了全分辨率计算的数量,使我们能够以较小的输入进行繁重的不可压缩的计算,同时仍然产生高质量的图像。
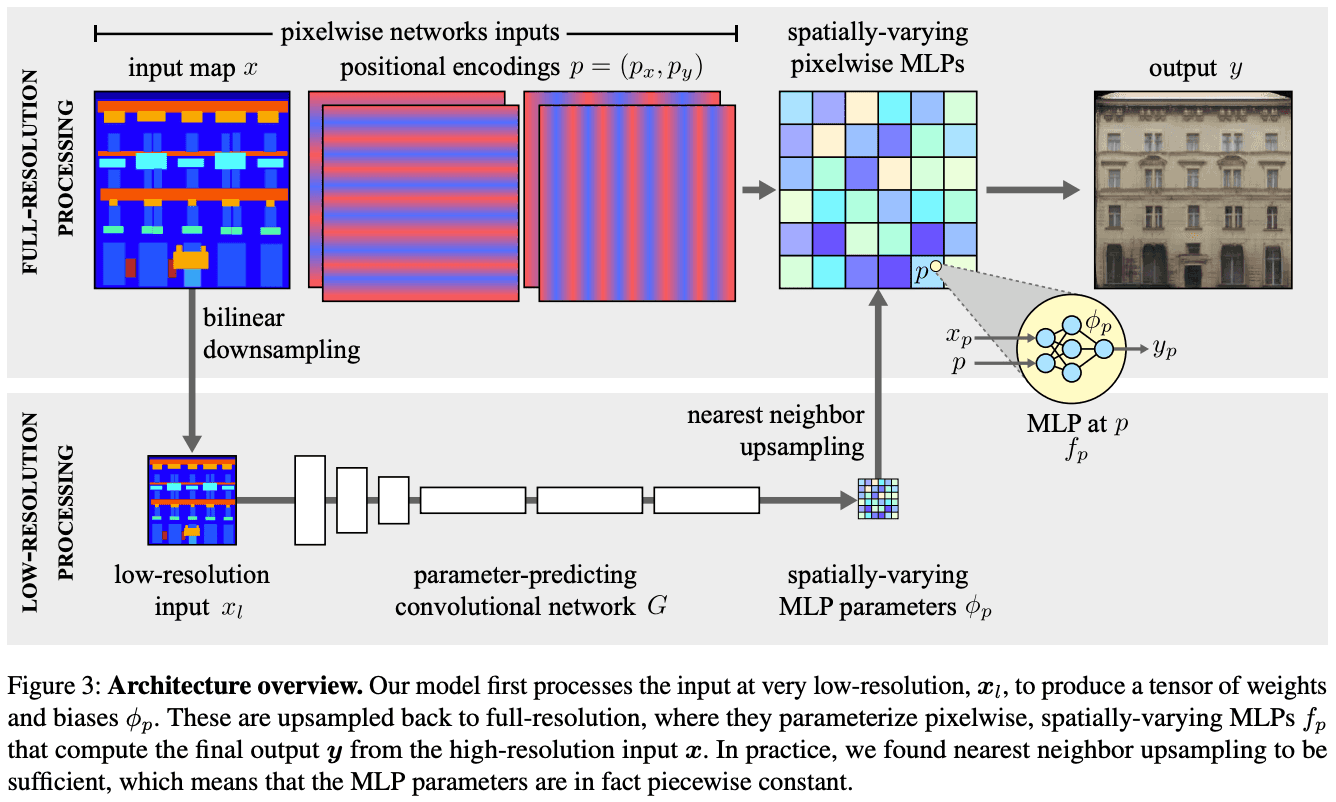
所提方法的整体架构如下图3所示。
像素网络
当输入是全分辨率时,计算的复杂性非常高。为了减少执行时间,我们建立了一个点式非线性变换$f_p$的模型。这里,$p$代表一个像素的坐标。这个过程对应于图3的顶部。由于每个像素都是独立于其他像素考虑的,所以计算可以并行化。然而,如果不仔细设计,独立考虑每个像素会限制模型的表达能力。
我们使用两种机制来维护空间信息。
- 每个像素的函数$f_p$将颜色值$x_p$和像素坐标$p$作为输入。
- 每个像素的函数$f_p$由空间变量$phi_p$设置参数,特别是多层感知器(MLP),它定义了以下映射

在公式(1)中,$f$代表MLP架构(对所有像素通用),$phi_p$代表MLP权重和偏置(在空间上变化)。MLP已经发现,5层和每层64个通道能产生更好的图像质量,执行时间更短。
如果输入图像不同,每个像素的参数集也不同。如果没有输入适应性和空间变化参数这两个特性,所提出的方法将是一个表达能力很差的模型,只是一系列1美元乘1美元的卷积层。
从低分辨率的输入中预测像素级的网络参数
对于自适应变换,$phi_p$必须是输入图像的一个函数。然而,要单独预测每个像素的参数向量$phi_p$是非常困难的。相反,它是由卷积神经网络$G$在分辨率更低的图像$x_l$上预测的。具体来说,网络$G$输出一个分辨率比$x$小$S$倍的参数网格。这个网格使用近邻内插法进行上采样,成为
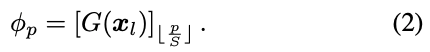
如图3底部所示,低分辨率计算首先对$x$进行双线性降样,以获得$x_l$。然后这个图像被$G$处理。$G$,并进一步减少系数$S_2$。G$的最终输出是一个张量,其通道对应于全分辨率的每像素网络的权重和偏差。这里我们使用$S_2=16$,并设置$S_1$,使$x_l$最多有256个像素。因此,总的下采样$S$取决于图像大小。这意味着低分辨率处理可以通过处理输入图像的非常低的分辨率表示,大大降低$G$的计算复杂性。
所提方法中的函数参数$phi_p$是在低分辨率下预测的,然后进行上采样。因此,在细节上预测高分辨率的能力受到一定的限制。在所提出的方法中,我们通过扩展每像素函数$f_p$,将像素位置$p$的编码作为额外的输入来避免这种情况。空间变化的MLPs,如CPPNs(构图模式生成网络)。可以比参数采样更精细地进行训练。此外,我们知道,NN有一个频谱偏向于首先学习低频信号。因此,我们发现将$p$直接传递给MLP,而不是像方程1那样,将二维像素位置的每个分量$p=(p_x,p_y)$编码为频率高于升采样系数的正弦波矢量,是非常有用的。每个MLP除了像素值$x_p$之外,还有2\times\times k$的额外输入。这种编码对应于图3的上半部分。
实验
实验设置
我们在一个图像翻译任务上验证了所提方法的性能。特别是,我们将执行时间和图像质量与以前的研究进行比较。
- 模型
- 我们的(ASAP-Net)
- CC-FPSE
- 引入一个新的条件卷积层来识别语义区域
- 旌德县
- 利用空间自适应归一化将语义图像转换为现实图像。
- pix2pixHD
- 卫星定位系统(SIMS)
- 改进部门结构
- CRN
- 高分辨率转换
- 数据集
- CMP
- 400对建筑图像
- 360/40张,划分为培训/参考数据
- 512*512,1024*1024
- 城市景观
- 城市景观的图像及其语义标签图
- 3000/500
- 256*512,512*1024
- 纽约大学深度数据集
- 1449张室内景观图片
- 1200/249
- CMP
实验结果
推理时间
使用了Nvidia GeForce 2080 ti GPU。根据不同的分辨率,建议的方法比pix2pixHD快6倍,比SPADE、SIMS和CRN快18倍。图1显示,建议的方法的优越性在更高的分辨率下显现。图1显示,在较高的分辨率下可以观察到所提方法的优越性,因为在较低的分辨率下,所提方法的卷积流相对于图像大小来说几乎是恒定的。
生成图像的质量
可以看出,生成的图像具有与基线模型相当的视觉质量。


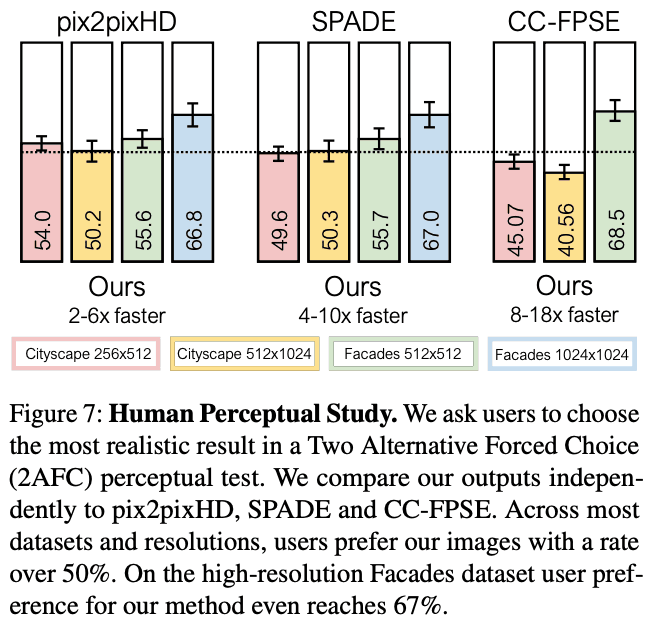
由人类进行评估
AMT被用来评估人类生成的图像。我们问用户,在拟议方法和基线模型生成的图像中,哪一个看起来更真实。图7显示,用户对拟议方法的评价与基线模型一样高。
 量化评价
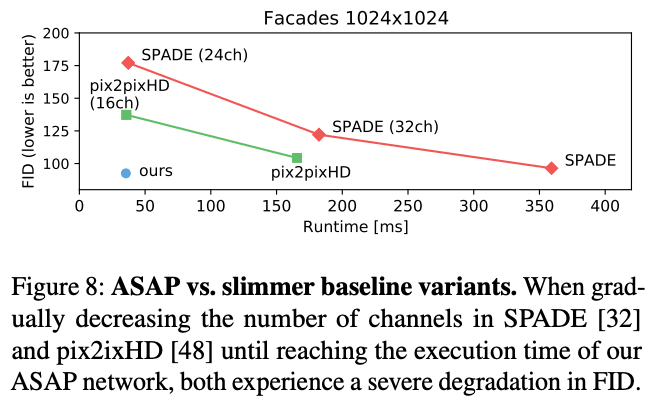
量化评价
我们对生成的图像的质量进行了定量评估。首先,我们将生成的图像通过语义分割网络,获得FID分数并进行比较。在图8中,我们可以看到建议的方法和pix2pixHD/SPADE有相同的得分。图8显示,提议的方法和pix2pixHD/SPADE的得分相同,这意味着提议的方法与基线模型具有相同的质量,但执行时间要短得多。当参数的数量减少,使基线模型的执行时间与建议的方法相同时,FID得分就会大大减少。
摘要
在本文中,我们提出了一个专门针对对抗性图像变换任务的加速的架构。尽管通过将高分辨率的图像还原成低分辨率的过程提高了速度,但我们还是能够产生与现有方法质量相当的图像。值得注意的是,计算是在低分辨率下进行的,因此,得分可能会因物体小于图像大小的3%而略有下降。



与本文相关的类别


