人工智能及其无限的应用方式 -人工智能使世界线成为可能-
通常我写的都是比较技术性的话题,但这一次我想把重点放在人工智能的解释方面。
我相信你们中的许多人都熟悉姿势估计,或者可能听说过它。 简单地说,它是一种确定人的姿势的技术。在CVPR2017上展示的OpenPose,是最著名的姿势估计技术案例,你可能听说过。 在这篇文章中,我想深入介绍一下姿势估计。我想深入了解一下姿态估计。
姿势估计的社会需求如何扩大?
我写这篇文章的原因是,近年来,视频社交网站的人气爆棚,因此,视频研究也随之增加。所以视频数据变得越来越普遍。 除了社交网站之外,在犯罪预防和控制措施方面,安全摄像头也成为一种常见的工具。在这种情况下,姿势估计已成为分析客户行为、掌握护理病人情况或监测犯罪预防和控制措施的重要工具。护理中的病人,或监测可疑的行为。
大约10年前,姿态估计有一个经典的树状模型,据说因为其在准确性方面存在很多问题,所以很难用于商业。然而,随着深度学习的出现,这些问题都得到了解决,深度学习现在在商业发展中发挥着核心作用。因此,我想在下文中更深入地了解一下不断增长的姿势估计业务。
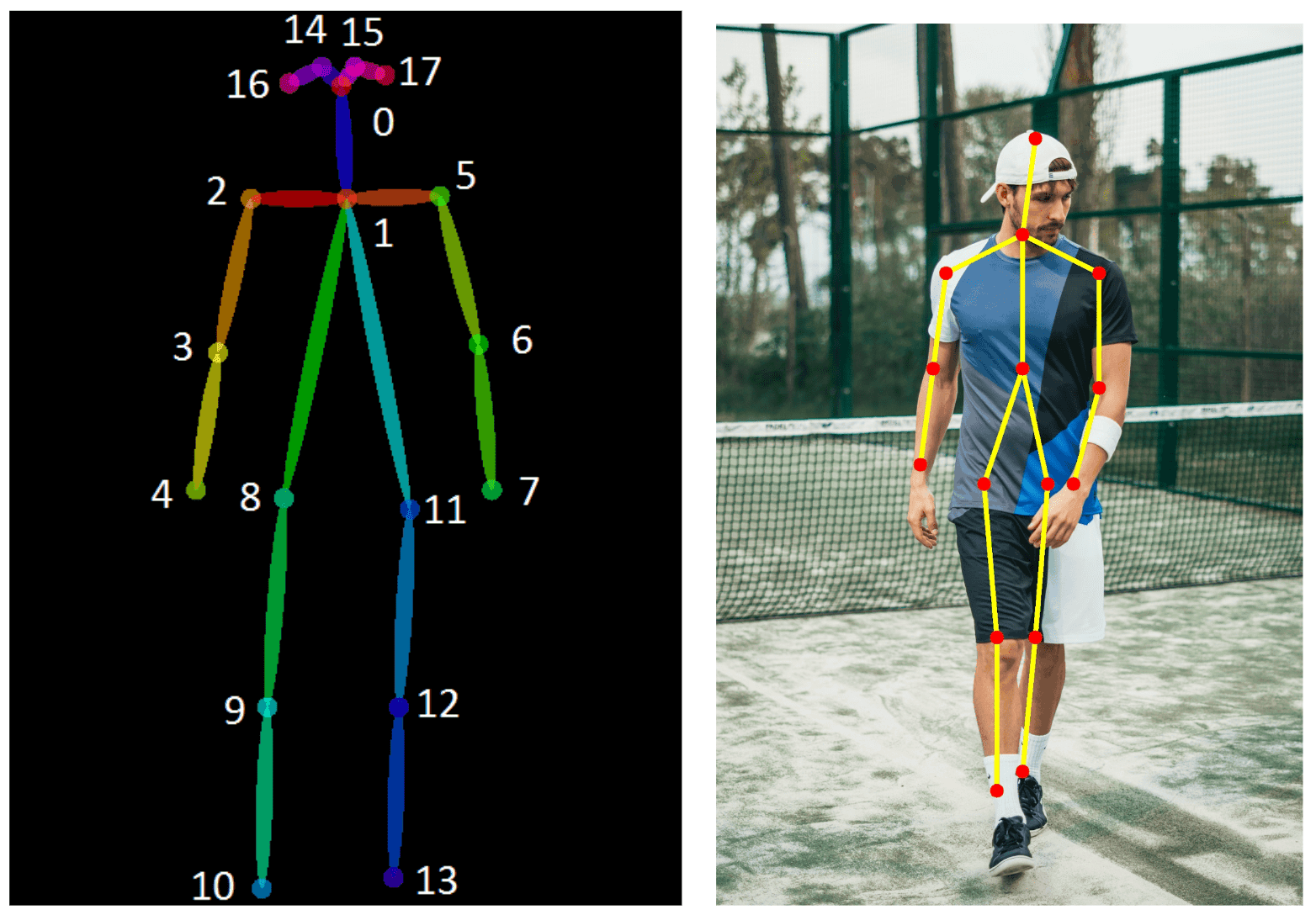
姿势估计的可能应用有哪些?
保安人员不可能24小时主动盯着监控摄像头的图像--有必要将这一过程自动化。 但为什么要提出估计,你认为呢?首先,视频包含大量的数据。 当你在拍摄人们的视频或照片时,身体姿势总是包括在内。而姿势为一个人做什么或即将做什么提供了重要的信息。
例如:在体育方面,你可以分析运动员的运动,并利用这些数据来防止受伤和创建教练员的练习计划。
在控制和安全方面,你可以监测做出某些动作的人。 传统的技术能够在每次有人接近限制区域时告诉你,但这只会增加管理成本,因为要追踪所有碰巧接近的人。有了姿势估计通过检测故意试图进入禁区的人的 "行为",可以防止不必要的跟踪。
通过分析人们的行为,我们可以创造更多的价值。 而这意味着为你的服务增加价值,并使你与其他公司区别开来。竞争。
关于姿势估计
让我们来看看姿势估计的技术问题。 首先,有两种类型的姿势估计:回归和热图检测。
回归方法
在这种情况下,需要逐个像素地预测关节位置,而且很难对位置做出准确的规定。逐个像素进行预测,而且很难对位置作出准确的规定。
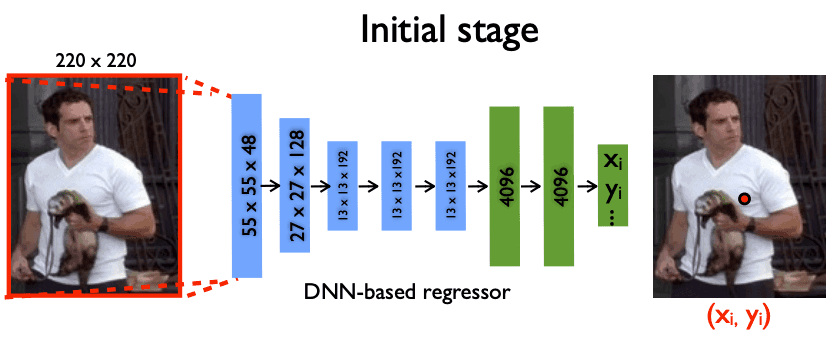
资料来源。DeepPose:通过深度神经网络进行人体姿势估计
热图法
在这里,关节位置的概率是以一个像素为单位计算的,这允许在一定范围内出现错位。这种方法比回归法更能容忍小的偏差,因此是目前姿势估计模型中最常用的方法。人们所熟悉的大多数模型都是基于这种方法的。
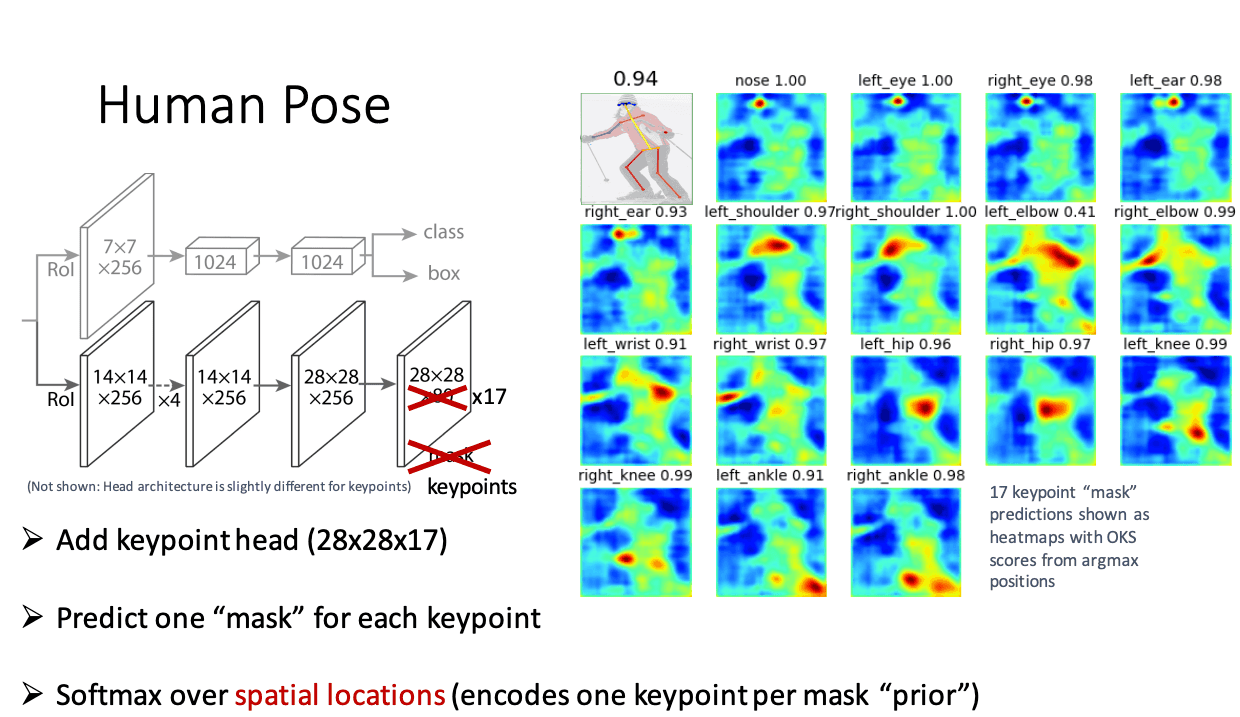
资料来源。用于实例级对象理解的深度学习
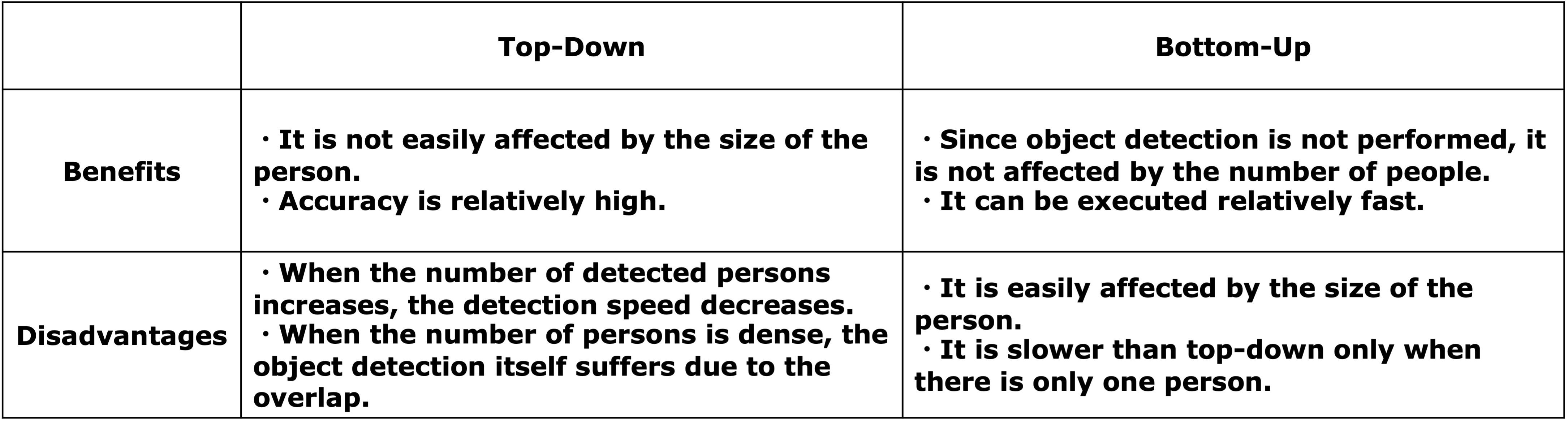
此外,姿势估计根据其属性分为自上而下和自下而上两种类型。
自上而下
这里,首先检测一个人,然后预测被检测人的骨骼坐标。
- 进行物体检测是为了识别一个人。
- 对检测到的人的骨骼点坐标进行预测。
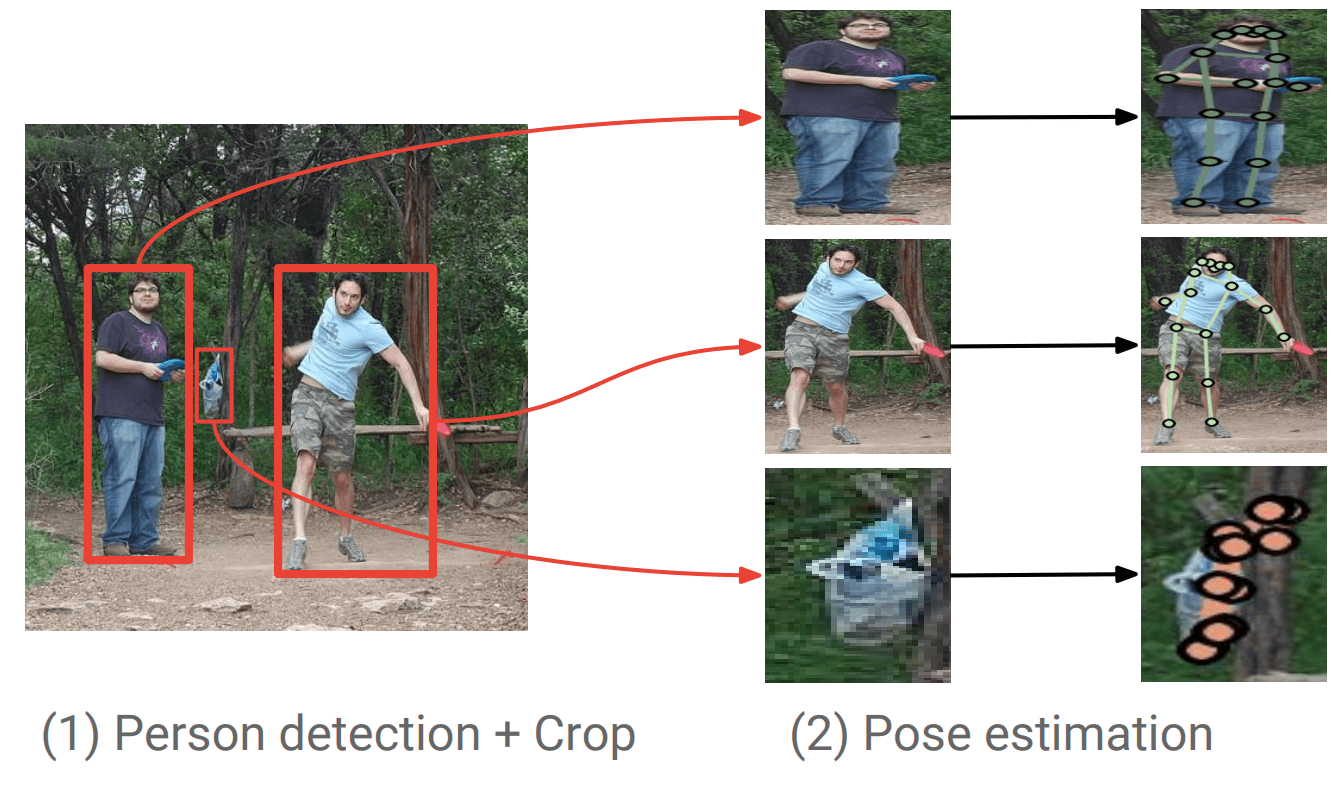
资料来源。在野外实现准确的多人姿态估计
自下而上
首先,一次性检测骨骼点,然后将检测到的骨骼点进行分组,形成整个人。
- 只从图像中检测出关节的关键点坐标(物体本身不被区分)。
- 通过基于距离的优化,将检测到的关键点分组到人身上

资料来源。DeepCut:用于多人姿势估计的联合子集划分和标记
总结一下上述情况。
目前常用的技术
在下文中,你会发现当今世界上普遍使用的主要姿态估计系统的清单。
自上而下的方法
- 深层思考
- 屏蔽R-CNN
- 简单基线
- HRNeT
自下而上的方法
- 敞开的姿势
- 姿势网
- 关联嵌入
- 高等教育
专家访谈
我们邀请了Naka Hiroyuki先生和Kenji Koyanagi先生,他们都是来自NEXT-SYSTEM有限公司系统开发部的专家,请他们谈谈对以下问题的看法。我们向NEXT-SYSTEM公司系统开发部的专家Hiroyuki Naka先生和Kenji Koyanagi先生请教。


左:系统开发部,分管经理,小柳健二先生
右图:系统开发部,专家,Hiroyuki Naka先生
什么是VisionPose?
VisionPose是我们内部开发的人工智能姿势估计引擎,可以分析人类骨骼和2D/3D的姿势信息,不需要标记。除了相机图像外,还可以从静态图像和视频中进行检测。我们将VisionPose作为SDK提供,可用于各种开发目的,并作为综合设备包提供,可用于研究目的。 目前,该系列共售出300多套,主要由日本的大公司提供。目前,该系列共售出300多套,主要由日本的主要公司销售(截至2021年11月)。VisionPose网站
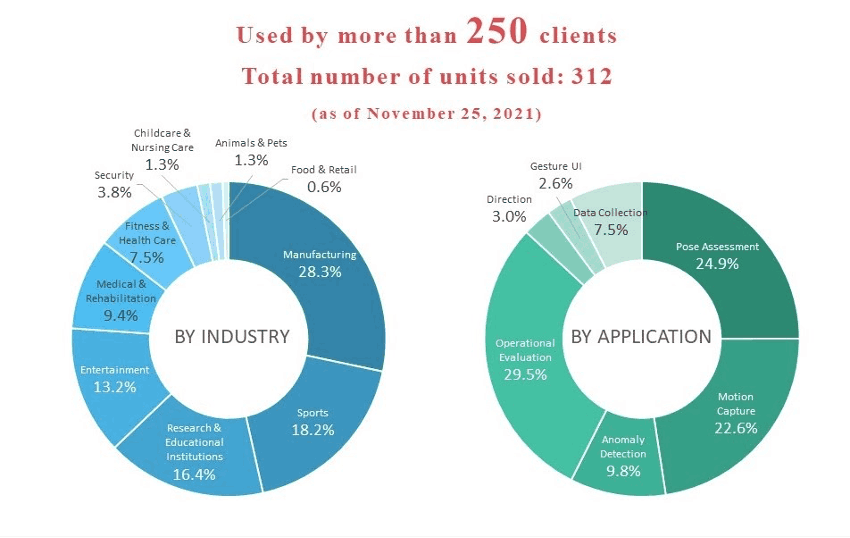
- 这张图显示,已经有广泛的行业在使用VisionPose,并且有多种方式应用AI引擎。这些信息与我前面提到的对姿势估计的不断扩大的社会需求是一致的。
你为什么决定开发VisionPose?
开发VisionPose的最初触发因素是2017年10月Kinect V2运动传感器相机的突然停产。由于我们无法找到一个类似的相机来取代Kinect,所以当时我们的AR标牌系统Kinesys是我们的主要产品。由于我们找不到可替代Kinect的相机,我们公司被迫面对一个困难的商业局面。
这是宣布停产后,我们在恐慌中买下的所有Kinect V2相机的照片。

-图片本身很有趣,但情况绝对不是这样....。.所以这就是姿势估计对NEXT-SYSTEM起作用的时刻。
由于这种情况,我们决定开发一个姿势估计系统,只需使用普通的网络摄像机就能实时检测人体运动。这是通过应用图像识别人工智能技术实现的,这是我们通过合同积累的技术诀窍。因此,VisionPose诞生了。
2017年12月,我们在SNS上发布了一个简单的演示,得到了很好的反响,于是我们开始认真开发,经过一年左右的努力。我们终于在2018年11月开始将VisionPose作为一种产品销售。
VisionPose的特点是什么?
VisionPose能够检测2D/3D坐标中多达30个关键点的骨骼信息,它包括一个SDK和两个随时可用的应用程序:"BodyAndColor",它从相机图像中实时检测骨骼信息,以及 "VP Analyzer",它检测摄像机图像中的实时骨骼信息,以及 "VP分析器",它从视频和静态图像中检测骨骼信息。
VisionPose标准版配备了我们训练有素的模型,可以轻松识别日常生活中的常见姿势。 在更具体的领域,如舞蹈和体育。分析的准确性可以通过额外的学习来提高,也可以增加额外的检测点(额外的学习是一个可选的服务)。
由于姿势估计技术有广泛的应用,VisionPose支持广泛的操作系统和设备。它还支持擅长实时处理的边缘设备,可以在小空间内操作,同时降低终端成本,便于在生产现场使用。也可用于商业用途.
- 30个关键点的最大检测量比其他姿势估计技术通常提供的要多得多。 此外,额外的学习此外,额外的学习似乎相当重要,以满足客户的要求,这取决于应用。
在使用国外的姿势估计技术时,除了iOS等附属解决方案外,大多是开源的或纸质的。将姿势评估纳入你的服务可能相当困难,因为可能会出现很多问题和议题,但我们公司可以提供额外的实施支持,我认为这是一个非常特殊的功能。
- 这是真的,有些人可能会提供很多帮助,但一般来说,没有固定的支持系统。 而且,这一切都由边缘计算完成,这一点令人惊讶。令人惊叹。
因为它是一个自下而上的人工智能,VisionPose不会逐一分析图像中的每个人,而是首先检测整个图像中的关键点,而不会因此,即使检测到的人的数量增加,速度也不会降低,这是VisionPoses的优势之一。因此,即使检测到的人的数量增加,速度也不会降低,这是VisionPoses的优势之一。
你为什么选择自下而上而不是自上而下?
我们选择这种方法是为了让它能实时工作,即使画面中有多人。 我想如果FPS下降,可能很难使用我想,如果FPS下降,可能很难使用 所以我决定使用自下而上的方法,以确保速度不下降,即使有所以我决定使用自下而上的方法,以确保即使检测到多人,速度也不会下降。
然而,虽然速度不减是个优点,但也存在着关键点可能会混在一起推论给多人的问题。因此,为了提高分组的准确性,我们使用多样化的多人数据进行额外的学习。
能够在内部进行补充学习是一个很大的优势。 你在这方面有什么困难吗?
是的,我们用来开发VisionPose的第一个大型数据集有17个关键点,但由于我们最初的目标是创建一个Kinect V2的替代品,我们利用内部学习将关键点的数量增加到30个。
在这项研究中,我们在绿色屏幕前拍摄了约7000张我们员工的各种姿势和角度的照片,然后创建了数以万计的我们还必须手工输入所有这些图像上的每一个关键点,这是一个很大的工作,但我们能够极大地提高准确性,我们能够通过增加更多的模式,如合成背景,来创造数以万计的数据。我们能够极大地提高准确性,并将关键点的数量增加到我们的目标,即30个。


(左)拍摄数据用于额外学习
(右图)注释器同步理解骨架上的关键点位置
为了使额外的学习更有效率,我们开发了自己的教师数据创建工具,即 "VP注释工具",并建立了一个服务器环境,以便多人可以同时进行工作。
VP ANNOTATION TOOL的视频介绍,这是一个教师数据创建工具。
我们相信,在额外的学习方面仍有改进的余地,作为一种使教师数据更容易创建的方法,我们也旨在我们认为,在额外的学习方面仍有改进的余地,作为一种使创建教师数据更容易的方法,我们也旨在通过创建一个工具,通过使用3DCG人的各种姿势和环境来产生教师数据,从而降低工作成本。
我们遇到了很多困难,但最后它帮助我们大大增加了我们的专业知识。 例如,到目前为止,我们只对人类教师进行培训。例如,到目前为止,我们只对人类教师数据进行了训练,但发现了一个问题,即我们无法将人类数据与背景区分开来。 因此,我们在图片中没有任何人物的情况下进行了额外的学习,只对背景进行了学习,结果准确性有所提高。因此,我们在图片中没有任何人物的情况下做了额外的学习,只用了背景,准确率提高了。.
到目前为止,客户提出的最令人惊讶的应用要求是什么,或者你为其提供的技术最有趣的行业是什么?到目前为止,客户提出的最令人惊讶的应用要求是什么,或者你为其提供的技术最有趣的行业是什么?
我相信最令人惊讶的询问是那些询问VisionPose是否可以应用于动物、机器人,以及其他非人类的情况。
近年来,国内畜牧业出现了严重的劳动力短缺问题。 劳动力在不断减少,并出现了老龄化,而在因人力不足而无法投入足够时间进行监测的情况下,劳动力正在减少和老化,而由于农林渔业部支持的农场增加,饲养的动物数量正在上升。在由于缺乏人力而无法投入足够时间进行监测的情况下,会导致疾病检测和发情期检测的延误。通过农林渔业部等项目,传统的可穿戴设备已被证明可以提高生产效率,但它会导致疾病检测和发情期检测的延迟。通过农林渔业部等项目,传统的可穿戴设备已被证明可以提高生产效率,但它们的安装费用很高,而且给牲畜带来了沉重的负担。
出于这个原因,我们的客户希望使用无标记技术,并结合廉价和容易获得的相机。 因此我们制作了VisionPose因此,我们制作了VisionPose来学习牛和马等牲畜的姿势,并成功地从摄像机图像中实时检测出多种牲畜的骨架。通过根据获得的骨骼数据确定牲畜的姿势和行为,我们可以期望通过检测来支持繁殖季节的工作通过根据获得的骨骼数据确定牲畜的姿势和行为,我们可望通过早期检测疾病以及检测骑乘行为(牛骑在对方身上的行为,表明发情)来支持繁殖季节。
终于有一个非人类的例子了!终于有一个非人类的例子了!这不是我研究你们公司时出现的东西。因此,VisionPose和附加学习的优势,在边缘计算中易于使用,可适应社会的需求。
您能给我们举几个例子,说明到今天为止VisionPose在哪些方面得到了应用?
作为额外学习的一个例子,Avex管理公司将VisionPose用于他们的智能手机应用程序,通过视频分析来评估舞蹈技术。VisionPose最多可以检测到30个关键点,但由于 "轮子 "对评价舞蹈很重要,所以在这种情况下,进行了额外的学习,将点的数量增加到32个。我们还支持那些希望通过额外学习将球拍或球棒的尖端作为关键点的客户。我们还支持那些希望通过额外学习将球拍或球棒的尖端作为关键点的客户。
其他用途还包括体育领域,VisionPose被用于高尔夫和棒球的形态分析。 自己分析和改善形态是相当困难的,但VisionPose可以通过详细获取骨骼信息并进行评估,帮助球员分析和改善他们的形态。自己分析和改善形体是相当困难的,但VisionPose可以通过详细获取骨骼信息并进行量化评估,帮助选手分析和改善形体。此外,体育科学实验室,一个普通的法人协会,正在使用VisionPose来预测和避免年轻棒球运动员的伤害,方法是详细识别骨骼信息并进行定量评估。此外,体育科学实验室,一个普通的公司协会,正在使用VisionPose通过识别某些动作和投球障碍之间的关系来预测和避免年轻棒球运动员的伤害。
除了体育之外,VisionPose还被用于医疗康复领域,例如丰田汽车公司生产的支持瘫痪下肢康复的机器人。我们还不能告诉你细节,但我们正计划也向娱乐业的主要公司实施。娱乐业也是如此。
我们也使用VisionPose进行内部开发,例如我们的全身动作捕捉应用程序"MICHICON-Plus",它允许用户将其在智能手机摄像头上的动作实时投射到3DCG角色上。我们还开发了一个人工智能锻炼计数器应用程序,"IETORE",它可以自动计算重复训练动作的数量,如深蹲,从我们还开发了一个人工智能锻炼计数器应用程序 "IETORE",它可以通过用户的智能手机摄像头自动计算重复训练动作的数量,如深蹲。 此外,我们的应用程序"Kinesys "允许用户只需站在数字标牌前就能虚拟试穿衣服。
你在未来有什么更新计划?
在未来,我们计划专注于开发基于VisionPose的新服务。 目前我们正在开发一个使用时间序列数据的行为分析工具。VisionPose用于训练时间序列数据,以便可以检测到具体的行动。
例如,如果你只用静态数据看一个人的睡姿,仅凭他们的姿势就很难确定他们是 "睡觉 "还是 "躺着"。如果你使用时间序列数据,你可以根据因果关系进行判断,如站立→睡觉=躺下。
通过使用这些技术,我们将能够分析各种环境下的行为,例如跌倒的人。具体来说,我们将能够获得以前只使用姿态数据无法获得的新信息,如跌倒的人、偷窃者、捡到的产品和退回的产品。 通过使用这些技术,我们将能够分析各种环境中的行为。通过使用这些技术,我们将能够分析各种环境中的行为,包括零售店、工厂车间、医疗设施以及护理和儿童保育设施。
NEXT-SYSTEM还为他们的人工智能姿势估计引擎VisionPose开设了一个全球EC网站,截至2021年11月,我们希望我们能够我们将继续做出最大努力,提供创新的向所有人提供服务。
关于NEXT-SYSTEM
NEXT-SYSTEM是一家日本的系统开发公司,于2002年在福冈市成立,此后一直专注于行为分析的研究。通过人工智能技术、人体工程学系统的开发和研究、尖端xR系统(AR/VR/MR)的开发,以及开发和销售该公司一直专注于通过人工智能技术进行行为分析的研究,人体工程学系统的开发和研究,开发尖端的xR系统(AR/VR/MR),以及开发和销售他们的姿势估计人工智能引擎 "VisionPose "和AR标牌系统 "Kinesys",其口号是 "我们创造未来"。



与本文相关的类别

